 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInfSplign: Inference-Time Spatial Alignment of Text-to-Image Diffusion Models
Dec 19, 2025
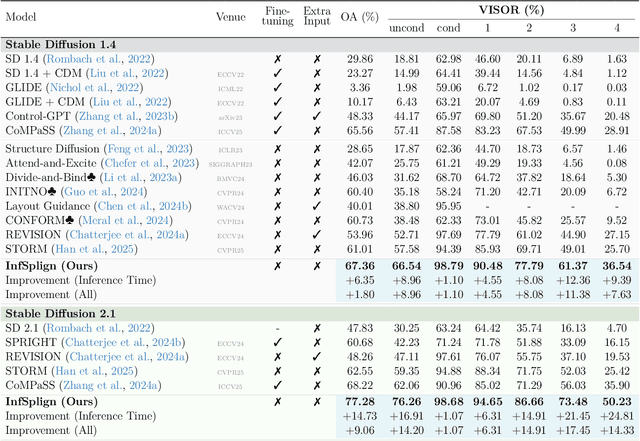
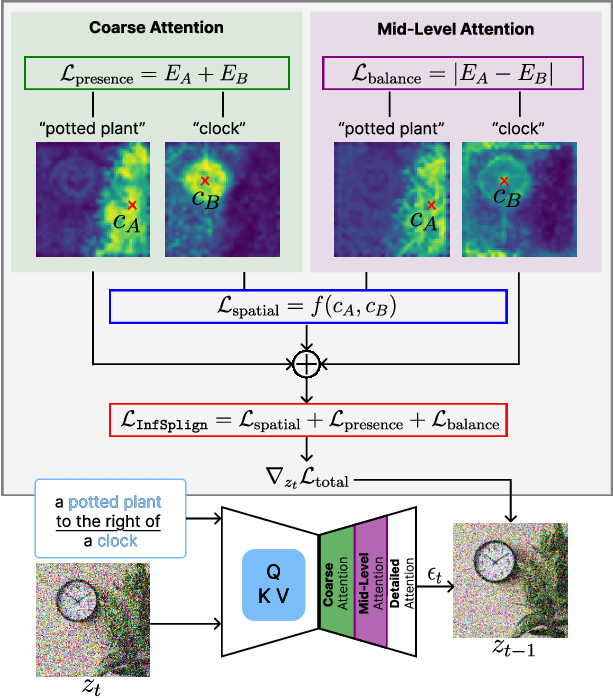
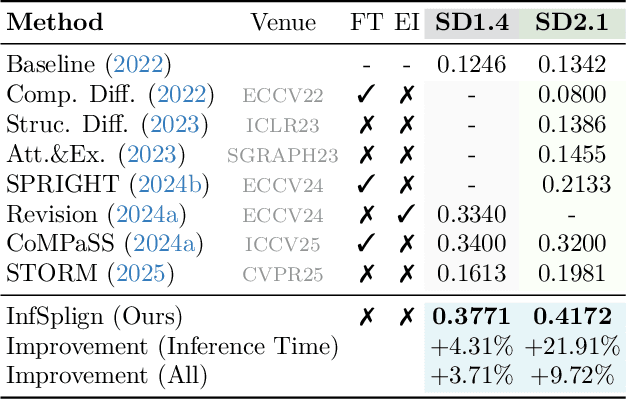
Text-to-image (T2I) diffusion models generate high-quality images but often fail to capture the spatial relations specified in text prompts. This limitation can be traced to two factors: lack of fine-grained spatial supervision in training data and inability of text embeddings to encode spatial semantics. We introduce InfSplign, a training-free inference-time method that improves spatial alignment by adjusting the noise through a compound loss in every denoising step. Proposed loss leverages different levels of cross-attention maps extracted from the backbone decoder to enforce accurate object placement and a balanced object presence during sampling. The method is lightweight, plug-and-play, and compatible with any diffusion backbone. Our comprehensive evaluations on VISOR and T2I-CompBench show that InfSplign establishes a new state-of-the-art (to the best of our knowledge), achieving substantial performance gains over the strongest existing inference-time baselines and even outperforming the fine-tuning-based methods. Codebase is available at GitHub.
Side Effects of Erasing Concepts from Diffusion Models
Aug 20, 2025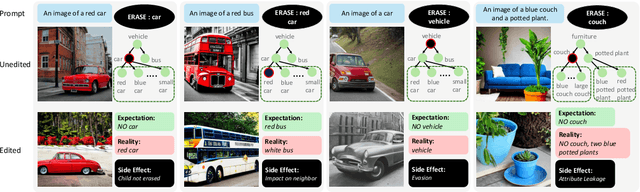
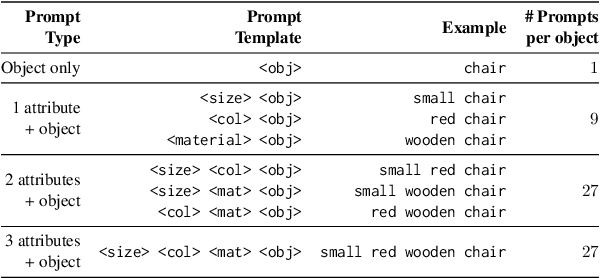
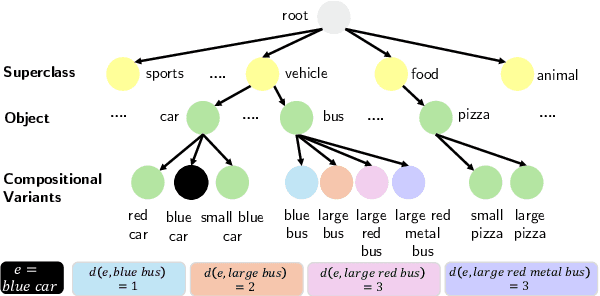

Concerns about text-to-image (T2I) generative models infringing on privacy, copyright, and safety have led to the development of Concept Erasure Techniques (CETs). The goal of an effective CET is to prohibit the generation of undesired ``target'' concepts specified by the user, while preserving the ability to synthesize high-quality images of the remaining concepts. In this work, we demonstrate that CETs can be easily circumvented and present several side effects of concept erasure. For a comprehensive measurement of the robustness of CETs, we present Side Effect Evaluation (\see), an evaluation benchmark that consists of hierarchical and compositional prompts that describe objects and their attributes. This dataset and our automated evaluation pipeline quantify side effects of CETs across three aspects: impact on neighboring concepts, evasion of targets, and attribute leakage. Our experiments reveal that CETs can be circumvented by using superclass-subclass hierarchy and semantically similar prompts, such as compositional variants of the target. We show that CETs suffer from attribute leakage and counterintuitive phenomena of attention concentration or dispersal. We release our dataset, code, and evaluation tools to aid future work on robust concept erasure.
TripletCLIP: Improving Compositional Reasoning of CLIP via Synthetic Vision-Language Negatives
Nov 04, 2024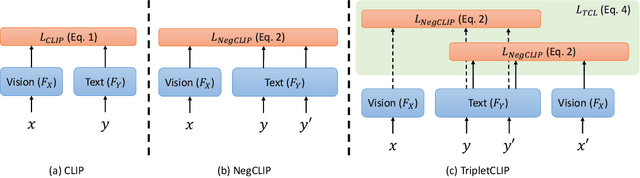

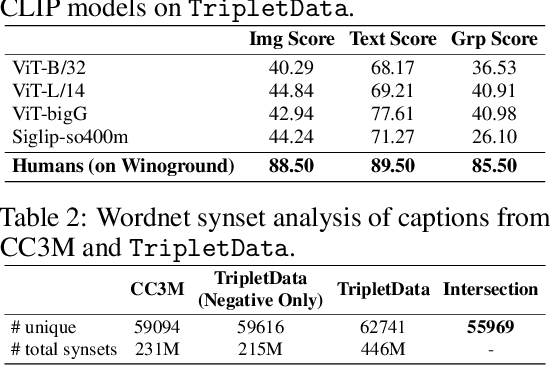

Contrastive Language-Image Pretraining (CLIP) models maximize the mutual information between text and visual modalities to learn representations. This makes the nature of the training data a significant factor in the efficacy of CLIP for downstream tasks. However, the lack of compositional diversity in contemporary image-text datasets limits the compositional reasoning ability of CLIP. We show that generating ``hard'' negative captions via in-context learning and synthesizing corresponding negative images with text-to-image generators offers a solution. We introduce a novel contrastive pre-training strategy that leverages these hard negative captions and images in an alternating fashion to train CLIP. We demonstrate that our method, named TripletCLIP, when applied to existing datasets such as CC3M and CC12M, enhances the compositional capabilities of CLIP, resulting in an absolute improvement of over 9% on the SugarCrepe benchmark on an equal computational budget, as well as improvements in zero-shot image classification and image retrieval. Our code, models, and data are available at: https://tripletclip.github.io
REVISION: Rendering Tools Enable Spatial Fidelity in Vision-Language Models
Aug 05, 2024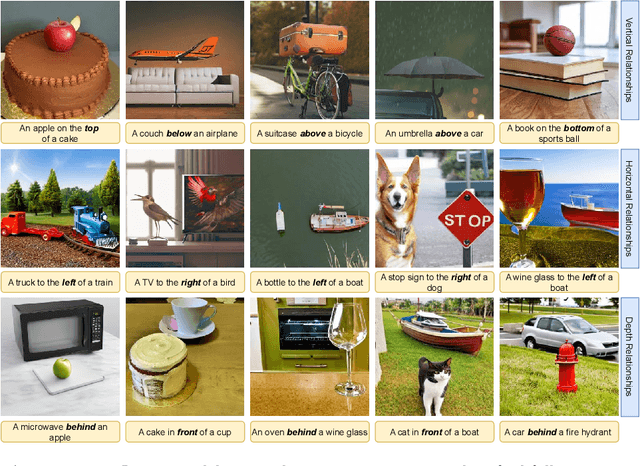


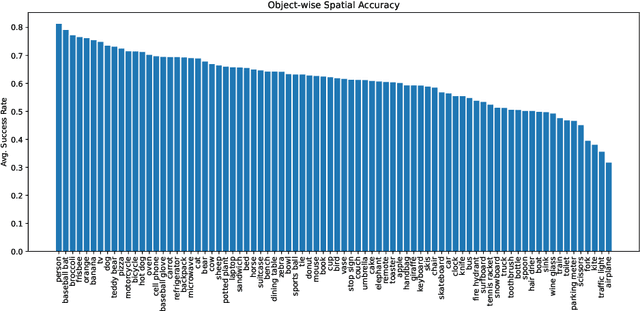
Text-to-Image (T2I) and multimodal large language models (MLLMs) have been adopted in solutions for several computer vision and multimodal learning tasks. However, it has been found that such vision-language models lack the ability to correctly reason over spatial relationships. To tackle this shortcoming, we develop the REVISION framework which improves spatial fidelity in vision-language models. REVISION is a 3D rendering based pipeline that generates spatially accurate synthetic images, given a textual prompt. REVISION is an extendable framework, which currently supports 100+ 3D assets, 11 spatial relationships, all with diverse camera perspectives and backgrounds. Leveraging images from REVISION as additional guidance in a training-free manner consistently improves the spatial consistency of T2I models across all spatial relationships, achieving competitive performance on the VISOR and T2I-CompBench benchmarks. We also design RevQA, a question-answering benchmark to evaluate the spatial reasoning abilities of MLLMs, and find that state-of-the-art models are not robust to complex spatial reasoning under adversarial settings. Our results and findings indicate that utilizing rendering-based frameworks is an effective approach for developing spatially-aware generative models.
Grounding Stylistic Domain Generalization with Quantitative Domain Shift Measures and Synthetic Scene Images
May 24, 2024



Domain Generalization (DG) is a challenging task in machine learning that requires a coherent ability to comprehend shifts across various domains through extraction of domain-invariant features. DG performance is typically evaluated by performing image classification in domains of various image styles. However, current methodology lacks quantitative understanding about shifts in stylistic domain, and relies on a vast amount of pre-training data, such as ImageNet1K, which are predominantly in photo-realistic style with weakly supervised class labels. Such a data-driven practice could potentially result in spurious correlation and inflated performance on DG benchmarks. In this paper, we introduce a new DG paradigm to address these risks. We first introduce two new quantitative measures ICV and IDD to describe domain shifts in terms of consistency of classes within one domain and similarity between two stylistic domains. We then present SuperMarioDomains (SMD), a novel synthetic multi-domain dataset sampled from video game scenes with more consistent classes and sufficient dissimilarity compared to ImageNet1K. We demonstrate our DG method SMOS. SMOS first uses SMD to train a precursor model, which is then used to ground the training on a DG benchmark. We observe that SMOS contributes to state-of-the-art performance across five DG benchmarks, gaining large improvements to performances on abstract domains along with on-par or slight improvements to those on photo-realistic domains. Our qualitative analysis suggests that these improvements can be attributed to reduced distributional divergence between originally distant domains. Our data are available at https://github.com/fpsluozi/SMD-SMOS .
On the Robustness of Language Guidance for Low-Level Vision Tasks: Findings from Depth Estimation
Apr 12, 2024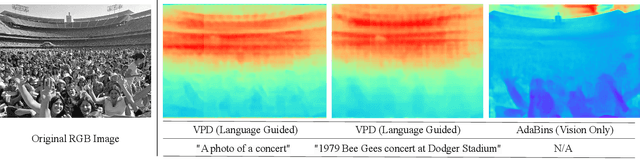
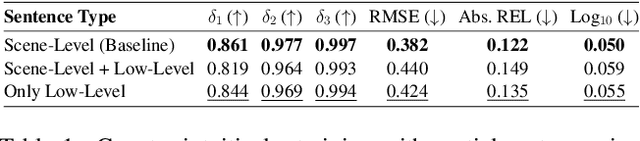
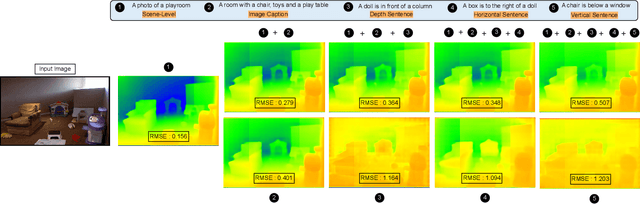
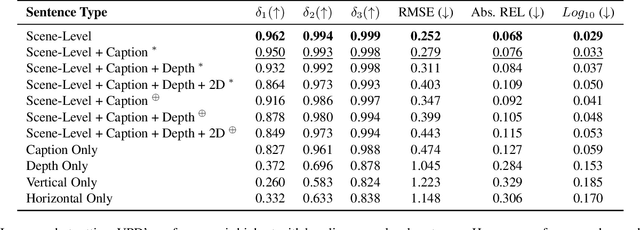
Recent advances in monocular depth estimation have been made by incorporating natural language as additional guidance. Although yielding impressive results, the impact of the language prior, particularly in terms of generalization and robustness, remains unexplored. In this paper, we address this gap by quantifying the impact of this prior and introduce methods to benchmark its effectiveness across various settings. We generate "low-level" sentences that convey object-centric, three-dimensional spatial relationships, incorporate them as additional language priors and evaluate their downstream impact on depth estimation. Our key finding is that current language-guided depth estimators perform optimally only with scene-level descriptions and counter-intuitively fare worse with low level descriptions. Despite leveraging additional data, these methods are not robust to directed adversarial attacks and decline in performance with an increase in distribution shift. Finally, to provide a foundation for future research, we identify points of failures and offer insights to better understand these shortcomings. With an increasing number of methods using language for depth estimation, our findings highlight the opportunities and pitfalls that require careful consideration for effective deployment in real-world settings
Improving Shift Invariance in Convolutional Neural Networks with Translation Invariant Polyphase Sampling
Apr 11, 2024Downsampling operators break the shift invariance of convolutional neural networks (CNNs) and this affects the robustness of features learned by CNNs when dealing with even small pixel-level shift. Through a large-scale correlation analysis framework, we study shift invariance of CNNs by inspecting existing downsampling operators in terms of their maximum-sampling bias (MSB), and find that MSB is negatively correlated with shift invariance. Based on this crucial insight, we propose a learnable pooling operator called Translation Invariant Polyphase Sampling (TIPS) and two regularizations on the intermediate feature maps of TIPS to reduce MSB and learn translation-invariant representations. TIPS can be integrated into any CNN and can be trained end-to-end with marginal computational overhead. Our experiments demonstrate that TIPS results in consistent performance gains in terms of accuracy, shift consistency, and shift fidelity on multiple benchmarks for image classification and semantic segmentation compared to previous methods and also leads to improvements in adversarial and distributional robustness. TIPS results in the lowest MSB compared to all previous methods, thus explaining our strong empirical results.
Getting it Right: Improving Spatial Consistency in Text-to-Image Models
Apr 01, 2024One of the key shortcomings in current text-to-image (T2I) models is their inability to consistently generate images which faithfully follow the spatial relationships specified in the text prompt. In this paper, we offer a comprehensive investigation of this limitation, while also developing datasets and methods that achieve state-of-the-art performance. First, we find that current vision-language datasets do not represent spatial relationships well enough; to alleviate this bottleneck, we create SPRIGHT, the first spatially-focused, large scale dataset, by re-captioning 6 million images from 4 widely used vision datasets. Through a 3-fold evaluation and analysis pipeline, we find that SPRIGHT largely improves upon existing datasets in capturing spatial relationships. To demonstrate its efficacy, we leverage only ~0.25% of SPRIGHT and achieve a 22% improvement in generating spatially accurate images while also improving the FID and CMMD scores. Secondly, we find that training on images containing a large number of objects results in substantial improvements in spatial consistency. Notably, we attain state-of-the-art on T2I-CompBench with a spatial score of 0.2133, by fine-tuning on <500 images. Finally, through a set of controlled experiments and ablations, we document multiple findings that we believe will enhance the understanding of factors that affect spatial consistency in text-to-image models. We publicly release our dataset and model to foster further research in this area.
Adversarial Bayesian Augmentation for Single-Source Domain Generalization
Jul 18, 2023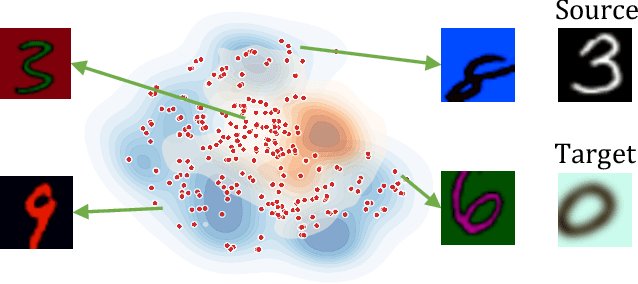
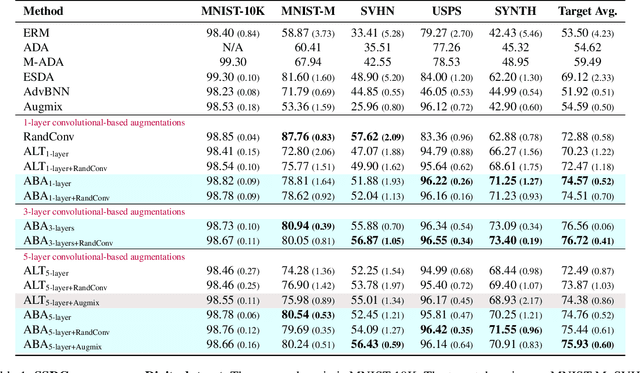

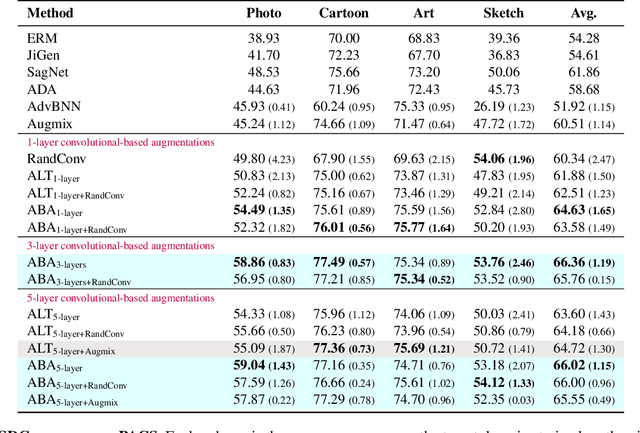
Generalizing to unseen image domains is a challenging problem primarily due to the lack of diverse training data, inaccessible target data, and the large domain shift that may exist in many real-world settings. As such data augmentation is a critical component of domain generalization methods that seek to address this problem. We present Adversarial Bayesian Augmentation (ABA), a novel algorithm that learns to generate image augmentations in the challenging single-source domain generalization setting. ABA draws on the strengths of adversarial learning and Bayesian neural networks to guide the generation of diverse data augmentations -- these synthesized image domains aid the classifier in generalizing to unseen domains. We demonstrate the strength of ABA on several types of domain shift including style shift, subpopulation shift, and shift in the medical imaging setting. ABA outperforms all previous state-of-the-art methods, including pre-specified augmentations, pixel-based and convolutional-based augmentations.
ConceptBed: Evaluating Concept Learning Abilities of Text-to-Image Diffusion Models
Jun 07, 2023The ability to understand visual concepts and replicate and compose these concepts from images is a central goal for computer vision. Recent advances in text-to-image (T2I) models have lead to high definition and realistic image quality generation by learning from large databases of images and their descriptions. However, the evaluation of T2I models has focused on photorealism and limited qualitative measures of visual understanding. To quantify the ability of T2I models in learning and synthesizing novel visual concepts, we introduce ConceptBed, a large-scale dataset that consists of 284 unique visual concepts, 5K unique concept compositions, and 33K composite text prompts. Along with the dataset, we propose an evaluation metric, Concept Confidence Deviation (CCD), that uses the confidence of oracle concept classifiers to measure the alignment between concepts generated by T2I generators and concepts contained in ground truth images. We evaluate visual concepts that are either objects, attributes, or styles, and also evaluate four dimensions of compositionality: counting, attributes, relations, and actions. Our human study shows that CCD is highly correlated with human understanding of concepts. Our results point to a trade-off between learning the concepts and preserving the compositionality which existing approaches struggle to overcome.