 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTerminal-Bench: Benchmarking Agents on Hard, Realistic Tasks in Command Line Interfaces
Jan 17, 2026AI agents may soon become capable of autonomously completing valuable, long-horizon tasks in diverse domains. Current benchmarks either do not measure real-world tasks, or are not sufficiently difficult to meaningfully measure frontier models. To this end, we present Terminal-Bench 2.0: a carefully curated hard benchmark composed of 89 tasks in computer terminal environments inspired by problems from real workflows. Each task features a unique environment, human-written solution, and comprehensive tests for verification. We show that frontier models and agents score less than 65\% on the benchmark and conduct an error analysis to identify areas for model and agent improvement. We publish the dataset and evaluation harness to assist developers and researchers in future work at https://www.tbench.ai/ .
NitroGen: An Open Foundation Model for Generalist Gaming Agents
Jan 04, 2026We introduce NitroGen, a vision-action foundation model for generalist gaming agents that is trained on 40,000 hours of gameplay videos across more than 1,000 games. We incorporate three key ingredients: 1) an internet-scale video-action dataset constructed by automatically extracting player actions from publicly available gameplay videos, 2) a multi-game benchmark environment that can measure cross-game generalization, and 3) a unified vision-action model trained with large-scale behavior cloning. NitroGen exhibits strong competence across diverse domains, including combat encounters in 3D action games, high-precision control in 2D platformers, and exploration in procedurally generated worlds. It transfers effectively to unseen games, achieving up to 52% relative improvement in task success rates over models trained from scratch. We release the dataset, evaluation suite, and model weights to advance research on generalist embodied agents.
Reusing Pre-Training Data at Test Time is a Compute Multiplier
Nov 06, 2025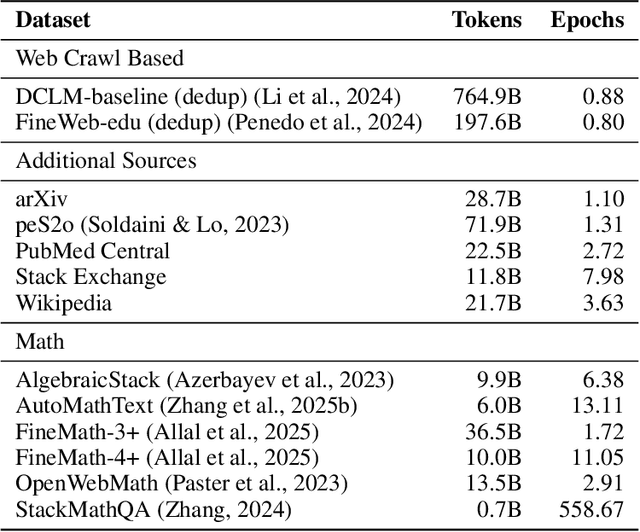
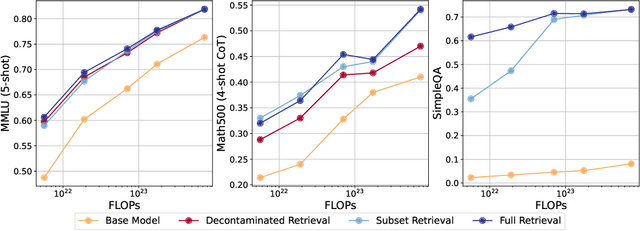
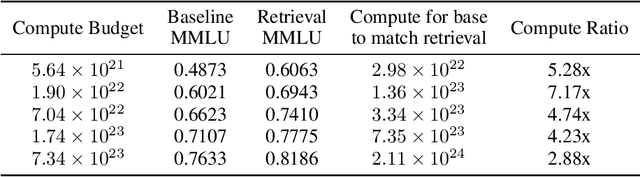
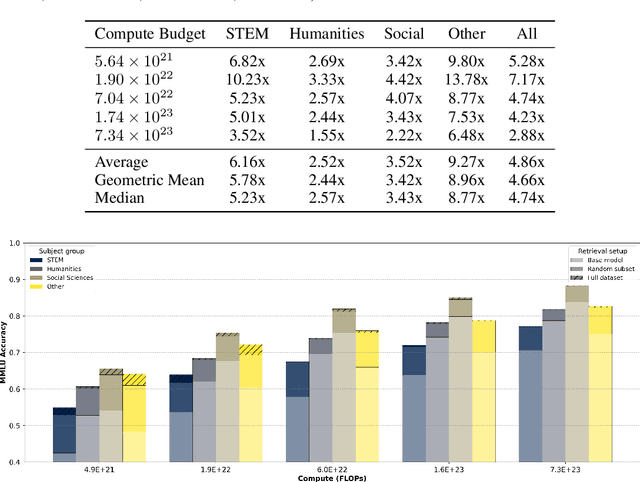
Large language models learn from their vast pre-training corpora, gaining the ability to solve an ever increasing variety of tasks; yet although researchers work to improve these datasets, there is little effort to understand how efficient the pre-training apparatus is at extracting ideas and knowledge from the data. In this work, we use retrieval augmented generation along with test-time compute as a way to quantify how much dataset value was left behind by the process of pre-training, and how this changes across scale. We demonstrate that pre-training then retrieving from standard and largely open-sourced datasets results in significant accuracy gains in MMLU, Math-500, and SimpleQA, which persist through decontamination. For MMLU we observe that retrieval acts as a ~5x compute multiplier versus pre-training alone. We show that these results can be further improved by leveraging additional compute at test time to parse the retrieved context, demonstrating a 10 percentage point improvement on MMLU for the public LLaMA 3.1 8B model. Overall, our results suggest that today's pre-training methods do not make full use of the information in existing pre-training datasets, leaving significant room for progress.
OLMoASR: Open Models and Data for Training Robust Speech Recognition Models
Aug 28, 2025Improvements in training data scale and quality have led to significant advances, yet its influence in speech recognition remains underexplored. In this paper, we present a large-scale dataset, OLMoASR-Pool, and series of models, OLMoASR, to study and develop robust zero-shot speech recognition models. Beginning from OLMoASR-Pool, a collection of 3M hours of English audio and 17M transcripts, we design text heuristic filters to remove low-quality or mistranscribed data. Our curation pipeline produces a new dataset containing 1M hours of high-quality audio-transcript pairs, which we call OLMoASR-Mix. We use OLMoASR-Mix to train the OLMoASR-Mix suite of models, ranging from 39M (tiny.en) to 1.5B (large.en) parameters. Across all model scales, OLMoASR achieves comparable average performance to OpenAI's Whisper on short and long-form speech recognition benchmarks. Notably, OLMoASR-medium.en attains a 12.8\% and 11.0\% word error rate (WER) that is on par with Whisper's largest English-only model Whisper-medium.en's 12.4\% and 10.5\% WER for short and long-form recognition respectively (at equivalent parameter count). OLMoASR-Pool, OLMoASR models, and filtering, training and evaluation code will be made publicly available to further research on robust speech processing.
OpenThoughts: Data Recipes for Reasoning Models
Jun 05, 2025Reasoning models have made rapid progress on many benchmarks involving math, code, and science. Yet, there are still many open questions about the best training recipes for reasoning since state-of-the-art models often rely on proprietary datasets with little to no public information available. To address this, the goal of the OpenThoughts project is to create open-source datasets for training reasoning models. After initial explorations, our OpenThoughts2-1M dataset led to OpenThinker2-32B, the first model trained on public reasoning data to match DeepSeek-R1-Distill-32B on standard reasoning benchmarks such as AIME and LiveCodeBench. We then improve our dataset further by systematically investigating each step of our data generation pipeline with 1,000+ controlled experiments, which led to OpenThoughts3. Scaling the pipeline to 1.2M examples and using QwQ-32B as teacher yields our OpenThoughts3-7B model, which achieves state-of-the-art results: 53% on AIME 2025, 51% on LiveCodeBench 06/24-01/25, and 54% on GPQA Diamond - improvements of 15.3, 17.2, and 20.5 percentage points compared to the DeepSeek-R1-Distill-Qwen-7B. All of our datasets and models are available on https://openthoughts.ai.
Recycling the Web: A Method to Enhance Pre-training Data Quality and Quantity for Language Models
Jun 05, 2025Scaling laws predict that the performance of large language models improves with increasing model size and data size. In practice, pre-training has been relying on massive web crawls, using almost all data sources publicly available on the internet so far. However, this pool of natural data does not grow at the same rate as the compute supply. Furthermore, the availability of high-quality texts is even more limited: data filtering pipelines often remove up to 99% of the initial web scrapes to achieve state-of-the-art. To address the "data wall" of pre-training scaling, our work explores ways to transform and recycle data discarded in existing filtering processes. We propose REWIRE, REcycling the Web with guIded REwrite, a method to enrich low-quality documents so that they could become useful for training. This in turn allows us to increase the representation of synthetic data in the final pre-training set. Experiments at 1B, 3B and 7B scales of the DCLM benchmark show that mixing high-quality raw texts and our rewritten texts lead to 1.0, 1.3 and 2.5 percentage points improvement respectively across 22 diverse tasks, compared to training on only filtered web data. Training on the raw-synthetic data mix is also more effective than having access to 2x web data. Through further analysis, we demonstrate that about 82% of the mixed in texts come from transforming lower-quality documents that would otherwise be discarded. REWIRE also outperforms related approaches of generating synthetic data, including Wikipedia-style paraphrasing, question-answer synthesizing and knowledge extraction. These results suggest that recycling web texts holds the potential for being a simple and effective approach for scaling pre-training data.
SWE-smith: Scaling Data for Software Engineering Agents
Apr 30, 2025Despite recent progress in Language Models (LMs) for software engineering, collecting training data remains a significant pain point. Existing datasets are small, with at most 1,000s of training instances from 11 or fewer GitHub repositories. The procedures to curate such datasets are often complex, necessitating hundreds of hours of human labor; companion execution environments also take up several terabytes of storage, severely limiting their scalability and usability. To address this pain point, we introduce SWE-smith, a novel pipeline for generating software engineering training data at scale. Given any Python codebase, SWE-smith constructs a corresponding execution environment, then automatically synthesizes 100s to 1,000s of task instances that break existing test(s) in the codebase. Using SWE-smith, we create a dataset of 50k instances sourced from 128 GitHub repositories, an order of magnitude larger than all previous works. We train SWE-agent-LM-32B, achieving 40.2% Pass@1 resolve rate on the SWE-bench Verified benchmark, state of the art among open source models. We open source SWE-smith (collection procedure, task instances, trajectories, models) to lower the barrier of entry for research in LM systems for automated software engineering. All assets available at https://swesmith.com.
Datasets, Documents, and Repetitions: The Practicalities of Unequal Data Quality
Mar 10, 2025Data filtering has become a powerful tool for improving model performance while reducing computational cost. However, as large language model compute budgets continue to grow, the limited data volume provided by heavily filtered and deduplicated datasets will become a practical constraint. In efforts to better understand how to proceed, we study model performance at various compute budgets and across multiple pre-training datasets created through data filtering and deduplication. We find that, given appropriate modifications to the training recipe, repeating existing aggressively filtered datasets for up to ten epochs can outperform training on the ten times larger superset for a single epoch across multiple compute budget orders of magnitude. While this finding relies on repeating the dataset for many epochs, we also investigate repeats within these datasets at the document level. We find that not all documents within a dataset are equal, and we can create better datasets relative to a token budget by explicitly manipulating the counts of individual documents. We conclude by arguing that even as large language models scale, data filtering remains an important direction of research.
Should VLMs be Pre-trained with Image Data?
Mar 10, 2025Pre-trained LLMs that are further trained with image data perform well on vision-language tasks. While adding images during a second training phase effectively unlocks this capability, it is unclear how much of a gain or loss this two-step pipeline gives over VLMs which integrate images earlier into the training process. To investigate this, we train models spanning various datasets, scales, image-text ratios, and amount of pre-training done before introducing vision tokens. We then fine-tune these models and evaluate their downstream performance on a suite of vision-language and text-only tasks. We find that pre-training with a mixture of image and text data allows models to perform better on vision-language tasks while maintaining strong performance on text-only evaluations. On an average of 6 diverse tasks, we find that for a 1B model, introducing visual tokens 80% of the way through pre-training results in a 2% average improvement over introducing visual tokens to a fully pre-trained model.
Project Alexandria: Towards Freeing Scientific Knowledge from Copyright Burdens via LLMs
Feb 26, 2025

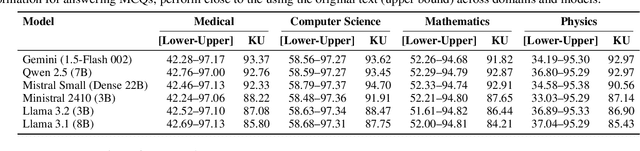

Paywalls, licenses and copyright rules often restrict the broad dissemination and reuse of scientific knowledge. We take the position that it is both legally and technically feasible to extract the scientific knowledge in scholarly texts. Current methods, like text embeddings, fail to reliably preserve factual content, and simple paraphrasing may not be legally sound. We urge the community to adopt a new idea: convert scholarly documents into Knowledge Units using LLMs. These units use structured data capturing entities, attributes and relationships without stylistic content. We provide evidence that Knowledge Units: (1) form a legally defensible framework for sharing knowledge from copyrighted research texts, based on legal analyses of German copyright law and U.S. Fair Use doctrine, and (2) preserve most (~95%) factual knowledge from original text, measured by MCQ performance on facts from the original copyrighted text across four research domains. Freeing scientific knowledge from copyright promises transformative benefits for scientific research and education by allowing language models to reuse important facts from copyrighted text. To support this, we share open-source tools for converting research documents into Knowledge Units. Overall, our work posits the feasibility of democratizing access to scientific knowledge while respecting copyright.