 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIntelligence per Watt: Measuring Intelligence Efficiency of Local AI
Nov 14, 2025Large language model (LLM) queries are predominantly processed by frontier models in centralized cloud infrastructure. Rapidly growing demand strains this paradigm, and cloud providers struggle to scale infrastructure at pace. Two advances enable us to rethink this paradigm: small LMs (<=20B active parameters) now achieve competitive performance to frontier models on many tasks, and local accelerators (e.g., Apple M4 Max) run these models at interactive latencies. This raises the question: can local inference viably redistribute demand from centralized infrastructure? Answering this requires measuring whether local LMs can accurately answer real-world queries and whether they can do so efficiently enough to be practical on power-constrained devices (i.e., laptops). We propose intelligence per watt (IPW), task accuracy divided by unit of power, as a metric for assessing capability and efficiency of local inference across model-accelerator pairs. We conduct a large-scale empirical study across 20+ state-of-the-art local LMs, 8 accelerators, and a representative subset of LLM traffic: 1M real-world single-turn chat and reasoning queries. For each query, we measure accuracy, energy, latency, and power. Our analysis reveals $3$ findings. First, local LMs can accurately answer 88.7% of single-turn chat and reasoning queries with accuracy varying by domain. Second, from 2023-2025, IPW improved 5.3x and local query coverage rose from 23.2% to 71.3%. Third, local accelerators achieve at least 1.4x lower IPW than cloud accelerators running identical models, revealing significant headroom for optimization. These findings demonstrate that local inference can meaningfully redistribute demand from centralized infrastructure, with IPW serving as the critical metric for tracking this transition. We release our IPW profiling harness for systematic intelligence-per-watt benchmarking.
MINT-1T: Scaling Open-Source Multimodal Data by 10x: A Multimodal Dataset with One Trillion Tokens
Jun 17, 2024



Multimodal interleaved datasets featuring free-form interleaved sequences of images and text are crucial for training frontier large multimodal models (LMMs). Despite the rapid progression of open-source LMMs, there remains a pronounced scarcity of large-scale, diverse open-source multimodal interleaved datasets. In response, we introduce MINT-1T, the most extensive and diverse open-source Multimodal INTerleaved dataset to date. MINT-1T comprises one trillion text tokens and three billion images, a 10x scale-up from existing open-source datasets. Additionally, we include previously untapped sources such as PDFs and ArXiv papers. As scaling multimodal interleaved datasets requires substantial engineering effort, sharing the data curation process and releasing the dataset greatly benefits the community. Our experiments show that LMMs trained on MINT-1T rival the performance of models trained on the previous leading dataset, OBELICS. Our data and code will be released at https://github.com/mlfoundations/MINT-1T.
Conformalization of Sparse Generalized Linear Models
Jul 11, 2023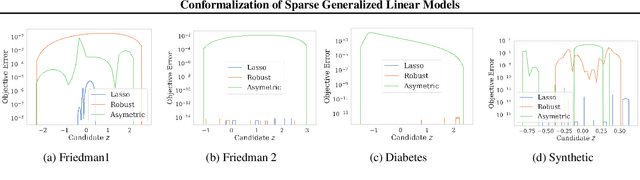


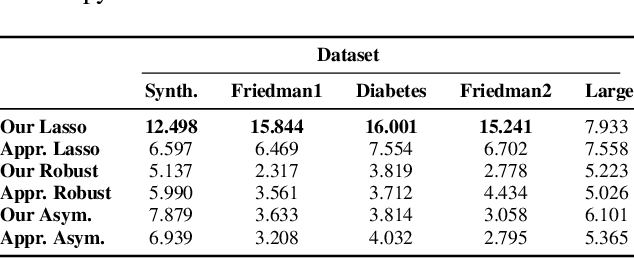
Given a sequence of observable variables $\{(x_1, y_1), \ldots, (x_n, y_n)\}$, the conformal prediction method estimates a confidence set for $y_{n+1}$ given $x_{n+1}$ that is valid for any finite sample size by merely assuming that the joint distribution of the data is permutation invariant. Although attractive, computing such a set is computationally infeasible in most regression problems. Indeed, in these cases, the unknown variable $y_{n+1}$ can take an infinite number of possible candidate values, and generating conformal sets requires retraining a predictive model for each candidate. In this paper, we focus on a sparse linear model with only a subset of variables for prediction and use numerical continuation techniques to approximate the solution path efficiently. The critical property we exploit is that the set of selected variables is invariant under a small perturbation of the input data. Therefore, it is sufficient to enumerate and refit the model only at the change points of the set of active features and smoothly interpolate the rest of the solution via a Predictor-Corrector mechanism. We show how our path-following algorithm accurately approximates conformal prediction sets and illustrate its performance using synthetic and real data examples.
Generalization Bounds for Magnitude-Based Pruning via Sparse Matrix Sketching
May 30, 2023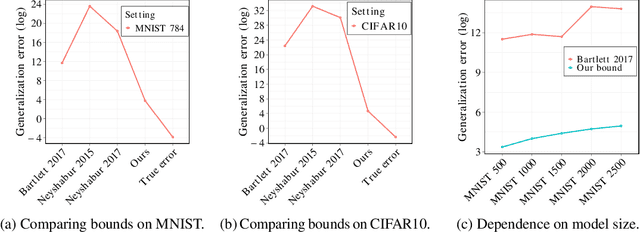
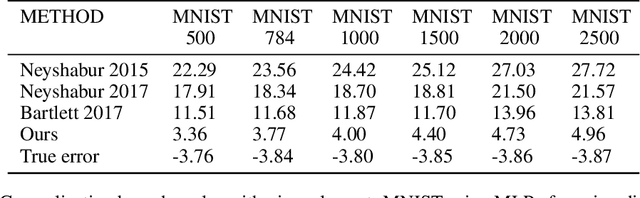
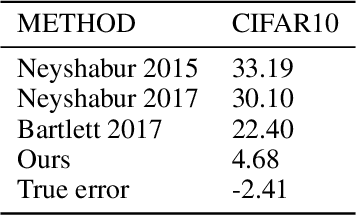
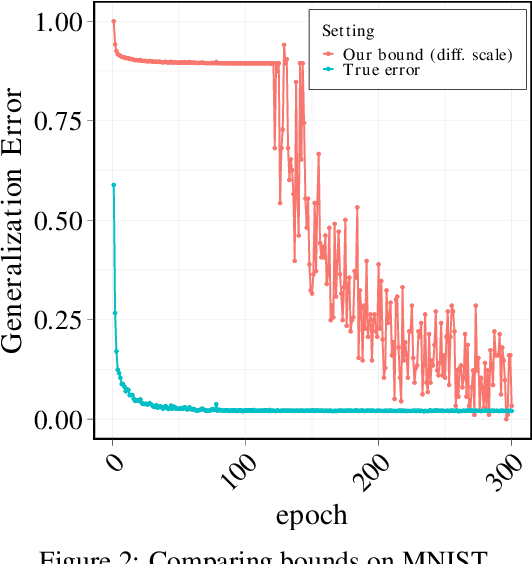
In this paper, we derive a novel bound on the generalization error of Magnitude-Based pruning of overparameterized neural networks. Our work builds on the bounds in Arora et al. [2018] where the error depends on one, the approximation induced by pruning, and two, the number of parameters in the pruned model, and improves upon standard norm-based generalization bounds. The pruned estimates obtained using our new Magnitude-Based compression algorithm are close to the unpruned functions with high probability, which improves the first criteria. Using Sparse Matrix Sketching, the space of the pruned matrices can be efficiently represented in the space of dense matrices of much smaller dimensions, thereby lowering the second criterion. This leads to stronger generalization bound than many state-of-the-art methods, thereby breaking new ground in the algorithm development for pruning and bounding generalization error of overparameterized models. Beyond this, we extend our results to obtain generalization bound for Iterative Pruning [Frankle and Carbin, 2018]. We empirically verify the success of this new method on ReLU-activated Feed Forward Networks on the MNIST and CIFAR10 datasets.
Solving Robust MDPs through No-Regret Dynamics
May 30, 2023Reinforcement Learning is a powerful framework for training agents to navigate different situations, but it is susceptible to changes in environmental dynamics. However, solving Markov Decision Processes that are robust to changes is difficult due to nonconvexity and size of action or state spaces. While most works have analyzed this problem by taking different assumptions on the problem, a general and efficient theoretical analysis is still missing. However, we generate a simple framework for improving robustness by solving a minimax iterative optimization problem where a policy player and an environmental dynamics player are playing against each other. Leveraging recent results in online nonconvex learning and techniques from improving policy gradient methods, we yield an algorithm that maximizes the robustness of the Value Function on the order of $\mathcal{O}\left(\frac{1}{T^{\frac{1}{2}}}\right)$ where $T$ is the number of iterations of the algorithm.