 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNitroGen: An Open Foundation Model for Generalist Gaming Agents
Jan 04, 2026We introduce NitroGen, a vision-action foundation model for generalist gaming agents that is trained on 40,000 hours of gameplay videos across more than 1,000 games. We incorporate three key ingredients: 1) an internet-scale video-action dataset constructed by automatically extracting player actions from publicly available gameplay videos, 2) a multi-game benchmark environment that can measure cross-game generalization, and 3) a unified vision-action model trained with large-scale behavior cloning. NitroGen exhibits strong competence across diverse domains, including combat encounters in 3D action games, high-precision control in 2D platformers, and exploration in procedurally generated worlds. It transfers effectively to unseen games, achieving up to 52% relative improvement in task success rates over models trained from scratch. We release the dataset, evaluation suite, and model weights to advance research on generalist embodied agents.
BLIP3-KALE: Knowledge Augmented Large-Scale Dense Captions
Nov 12, 2024
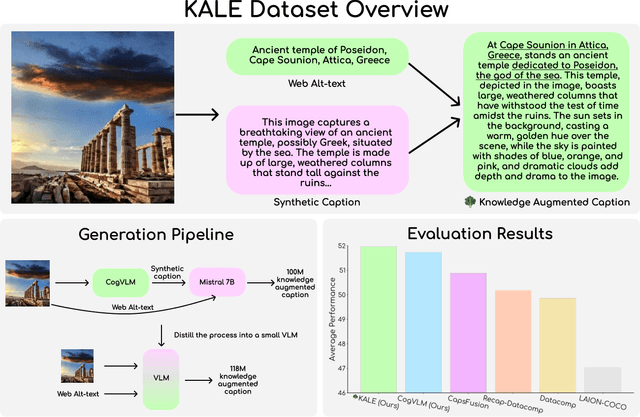
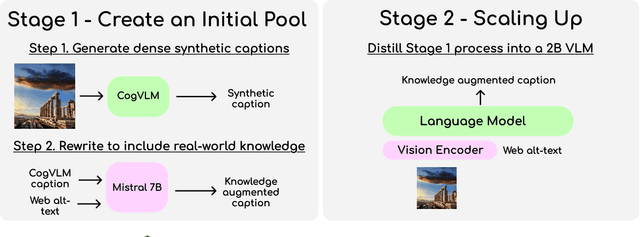

We introduce BLIP3-KALE, a dataset of 218 million image-text pairs that bridges the gap between descriptive synthetic captions and factual web-scale alt-text. KALE augments synthetic dense image captions with web-scale alt-text to generate factually grounded image captions. Our two-stage approach leverages large vision-language models and language models to create knowledge-augmented captions, which are then used to train a specialized VLM for scaling up the dataset. We train vision-language models on KALE and demonstrate improvements on vision-language tasks. Our experiments show the utility of KALE for training more capable and knowledgeable multimodal models. We release the KALE dataset at https://huggingface.co/datasets/Salesforce/blip3-kale
xGen-VideoSyn-1: High-fidelity Text-to-Video Synthesis with Compressed Representations
Aug 22, 2024



We present xGen-VideoSyn-1, a text-to-video (T2V) generation model capable of producing realistic scenes from textual descriptions. Building on recent advancements, such as OpenAI's Sora, we explore the latent diffusion model (LDM) architecture and introduce a video variational autoencoder (VidVAE). VidVAE compresses video data both spatially and temporally, significantly reducing the length of visual tokens and the computational demands associated with generating long-sequence videos. To further address the computational costs, we propose a divide-and-merge strategy that maintains temporal consistency across video segments. Our Diffusion Transformer (DiT) model incorporates spatial and temporal self-attention layers, enabling robust generalization across different timeframes and aspect ratios. We have devised a data processing pipeline from the very beginning and collected over 13M high-quality video-text pairs. The pipeline includes multiple steps such as clipping, text detection, motion estimation, aesthetics scoring, and dense captioning based on our in-house video-LLM model. Training the VidVAE and DiT models required approximately 40 and 642 H100 days, respectively. Our model supports over 14-second 720p video generation in an end-to-end way and demonstrates competitive performance against state-of-the-art T2V models.
xGen-MM (BLIP-3): A Family of Open Large Multimodal Models
Aug 16, 2024



This report introduces xGen-MM (also known as BLIP-3), a framework for developing Large Multimodal Models (LMMs). The framework comprises meticulously curated datasets, a training recipe, model architectures, and a resulting suite of LMMs. xGen-MM, short for xGen-MultiModal, expands the Salesforce xGen initiative on foundation AI models. Our models undergo rigorous evaluation across a range of tasks, including both single and multi-image benchmarks. Our pre-trained base model exhibits strong in-context learning capabilities and the instruction-tuned model demonstrates competitive performance among open-source LMMs with similar model sizes. In addition, we introduce a safety-tuned model with DPO, aiming to mitigate harmful behaviors such as hallucinations and improve safety. We open-source our models, curated large-scale datasets, and our fine-tuning codebase to facilitate further advancements in LMM research. Associated resources will be available on our project page above.
Certainly Uncertain: A Benchmark and Metric for Multimodal Epistemic and Aleatoric Awareness
Jul 02, 2024



The ability to acknowledge the inevitable uncertainty in their knowledge and reasoning is a prerequisite for AI systems to be truly truthful and reliable. In this paper, we present a taxonomy of uncertainty specific to vision-language AI systems, distinguishing between epistemic uncertainty (arising from a lack of information) and aleatoric uncertainty (due to inherent unpredictability), and further explore finer categories within. Based on this taxonomy, we synthesize a benchmark dataset, CertainlyUncertain, featuring 178K visual question answering (VQA) samples as contrastive pairs. This is achieved by 1) inpainting images to make previously answerable questions into unanswerable ones; and 2) using image captions to prompt large language models for both answerable and unanswerable questions. Additionally, we introduce a new metric confidence-weighted accuracy, that is well correlated with both accuracy and calibration error, to address the shortcomings of existing metrics.
MINT-1T: Scaling Open-Source Multimodal Data by 10x: A Multimodal Dataset with One Trillion Tokens
Jun 17, 2024



Multimodal interleaved datasets featuring free-form interleaved sequences of images and text are crucial for training frontier large multimodal models (LMMs). Despite the rapid progression of open-source LMMs, there remains a pronounced scarcity of large-scale, diverse open-source multimodal interleaved datasets. In response, we introduce MINT-1T, the most extensive and diverse open-source Multimodal INTerleaved dataset to date. MINT-1T comprises one trillion text tokens and three billion images, a 10x scale-up from existing open-source datasets. Additionally, we include previously untapped sources such as PDFs and ArXiv papers. As scaling multimodal interleaved datasets requires substantial engineering effort, sharing the data curation process and releasing the dataset greatly benefits the community. Our experiments show that LMMs trained on MINT-1T rival the performance of models trained on the previous leading dataset, OBELICS. Our data and code will be released at https://github.com/mlfoundations/MINT-1T.
Catwalk: A Unified Language Model Evaluation Framework for Many Datasets
Dec 15, 2023The success of large language models has shifted the evaluation paradigms in natural language processing (NLP). The community's interest has drifted towards comparing NLP models across many tasks, domains, and datasets, often at an extreme scale. This imposes new engineering challenges: efforts in constructing datasets and models have been fragmented, and their formats and interfaces are incompatible. As a result, it often takes extensive (re)implementation efforts to make fair and controlled comparisons at scale. Catwalk aims to address these issues. Catwalk provides a unified interface to a broad range of existing NLP datasets and models, ranging from both canonical supervised training and fine-tuning, to more modern paradigms like in-context learning. Its carefully-designed abstractions allow for easy extensions to many others. Catwalk substantially lowers the barriers to conducting controlled experiments at scale. For example, we finetuned and evaluated over 64 models on over 86 datasets with a single command, without writing any code. Maintained by the AllenNLP team at the Allen Institute for Artificial Intelligence (AI2), Catwalk is an ongoing open-source effort: https://github.com/allenai/catwalk.
VisIT-Bench: A Benchmark for Vision-Language Instruction Following Inspired by Real-World Use
Aug 12, 2023We introduce VisIT-Bench (Visual InsTruction Benchmark), a benchmark for evaluation of instruction-following vision-language models for real-world use. Our starting point is curating 70 'instruction families' that we envision instruction tuned vision-language models should be able to address. Extending beyond evaluations like VQAv2 and COCO, tasks range from basic recognition to game playing and creative generation. Following curation, our dataset comprises 592 test queries, each with a human-authored instruction-conditioned caption. These descriptions surface instruction-specific factors, e.g., for an instruction asking about the accessibility of a storefront for wheelchair users, the instruction-conditioned caption describes ramps/potential obstacles. These descriptions enable 1) collecting human-verified reference outputs for each instance; and 2) automatic evaluation of candidate multimodal generations using a text-only LLM, aligning with human judgment. We quantify quality gaps between models and references using both human and automatic evaluations; e.g., the top-performing instruction-following model wins against the GPT-4 reference in just 27% of the comparison. VisIT-Bench is dynamic to participate, practitioners simply submit their model's response on the project website; Data, code and leaderboard is available at visit-bench.github.io.
OpenFlamingo: An Open-Source Framework for Training Large Autoregressive Vision-Language Models
Aug 07, 2023



We introduce OpenFlamingo, a family of autoregressive vision-language models ranging from 3B to 9B parameters. OpenFlamingo is an ongoing effort to produce an open-source replication of DeepMind's Flamingo models. On seven vision-language datasets, OpenFlamingo models average between 80 - 89% of corresponding Flamingo performance. This technical report describes our models, training data, hyperparameters, and evaluation suite. We share our models and code at https://github.com/mlfoundations/open_flamingo.
Are aligned neural networks adversarially aligned?
Jun 26, 2023



Large language models are now tuned to align with the goals of their creators, namely to be "helpful and harmless." These models should respond helpfully to user questions, but refuse to answer requests that could cause harm. However, adversarial users can construct inputs which circumvent attempts at alignment. In this work, we study to what extent these models remain aligned, even when interacting with an adversarial user who constructs worst-case inputs (adversarial examples). These inputs are designed to cause the model to emit harmful content that would otherwise be prohibited. We show that existing NLP-based optimization attacks are insufficiently powerful to reliably attack aligned text models: even when current NLP-based attacks fail, we can find adversarial inputs with brute force. As a result, the failure of current attacks should not be seen as proof that aligned text models remain aligned under adversarial inputs. However the recent trend in large-scale ML models is multimodal models that allow users to provide images that influence the text that is generated. We show these models can be easily attacked, i.e., induced to perform arbitrary un-aligned behavior through adversarial perturbation of the input image. We conjecture that improved NLP attacks may demonstrate this same level of adversarial control over text-only models.