 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond a Single Extractor: Re-thinking HTML-to-Text Extraction for LLM Pretraining
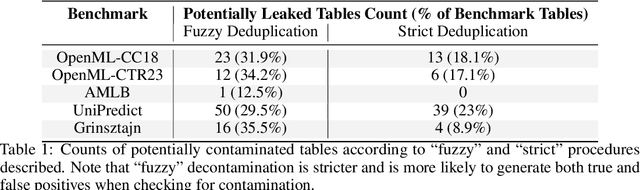
Feb 23, 2026One of the first pre-processing steps for constructing web-scale LLM pretraining datasets involves extracting text from HTML. Despite the immense diversity of web content, existing open-source datasets predominantly apply a single fixed extractor to all webpages. In this work, we investigate whether this practice leads to suboptimal coverage and utilization of Internet data. We first show that while different extractors may lead to similar model performance on standard language understanding tasks, the pages surviving a fixed filtering pipeline can differ substantially. This suggests a simple intervention: by taking a Union over different extractors, we can increase the token yield of DCLM-Baseline by up to 71% while maintaining benchmark performance. We further show that for structured content such as tables and code blocks, extractor choice can significantly impact downstream task performance, with differences of up to 10 percentage points (p.p.) on WikiTQ and 3 p.p. on HumanEval.
OLMoASR: Open Models and Data for Training Robust Speech Recognition Models
Aug 28, 2025Improvements in training data scale and quality have led to significant advances, yet its influence in speech recognition remains underexplored. In this paper, we present a large-scale dataset, OLMoASR-Pool, and series of models, OLMoASR, to study and develop robust zero-shot speech recognition models. Beginning from OLMoASR-Pool, a collection of 3M hours of English audio and 17M transcripts, we design text heuristic filters to remove low-quality or mistranscribed data. Our curation pipeline produces a new dataset containing 1M hours of high-quality audio-transcript pairs, which we call OLMoASR-Mix. We use OLMoASR-Mix to train the OLMoASR-Mix suite of models, ranging from 39M (tiny.en) to 1.5B (large.en) parameters. Across all model scales, OLMoASR achieves comparable average performance to OpenAI's Whisper on short and long-form speech recognition benchmarks. Notably, OLMoASR-medium.en attains a 12.8\% and 11.0\% word error rate (WER) that is on par with Whisper's largest English-only model Whisper-medium.en's 12.4\% and 10.5\% WER for short and long-form recognition respectively (at equivalent parameter count). OLMoASR-Pool, OLMoASR models, and filtering, training and evaluation code will be made publicly available to further research on robust speech processing.
Language Models Improve When Pretraining Data Matches Target Tasks
Jul 16, 2025Every data selection method inherently has a target. In practice, these targets often emerge implicitly through benchmark-driven iteration: researchers develop selection strategies, train models, measure benchmark performance, then refine accordingly. This raises a natural question: what happens when we make this optimization explicit? To explore this, we propose benchmark-targeted ranking (BETR), a simple method that selects pretraining documents based on similarity to benchmark training examples. BETR embeds benchmark examples and a sample of pretraining documents in a shared space, scores this sample by similarity to benchmarks, then trains a lightweight classifier to predict these scores for the full corpus. We compare data selection methods by training over 500 models spanning $10^{19}$ to $10^{22}$ FLOPs and fitting scaling laws to them. From this, we find that simply aligning pretraining data to evaluation benchmarks using BETR achieves a 2.1x compute multiplier over DCLM-Baseline (4.7x over unfiltered data) and improves performance on 9 out of 10 tasks across all scales. BETR also generalizes well: when targeting a diverse set of benchmarks disjoint from our evaluation suite, it still matches or outperforms baselines. Our scaling analysis further reveals a clear trend: larger models require less aggressive filtering. Overall, our findings show that directly matching pretraining data to target tasks precisely shapes model capabilities and highlight that optimal selection strategies must adapt to model scale.
DataComp-LM: In search of the next generation of training sets for language models
Jun 18, 2024



We introduce DataComp for Language Models (DCLM), a testbed for controlled dataset experiments with the goal of improving language models. As part of DCLM, we provide a standardized corpus of 240T tokens extracted from Common Crawl, effective pretraining recipes based on the OpenLM framework, and a broad suite of 53 downstream evaluations. Participants in the DCLM benchmark can experiment with data curation strategies such as deduplication, filtering, and data mixing at model scales ranging from 412M to 7B parameters. As a baseline for DCLM, we conduct extensive experiments and find that model-based filtering is key to assembling a high-quality training set. The resulting dataset, DCLM-Baseline enables training a 7B parameter language model from scratch to 64% 5-shot accuracy on MMLU with 2.6T training tokens. Compared to MAP-Neo, the previous state-of-the-art in open-data language models, DCLM-Baseline represents a 6.6 percentage point improvement on MMLU while being trained with 40% less compute. Our baseline model is also comparable to Mistral-7B-v0.3 and Llama 3 8B on MMLU (63% & 66%), and performs similarly on an average of 53 natural language understanding tasks while being trained with 6.6x less compute than Llama 3 8B. Our results highlight the importance of dataset design for training language models and offer a starting point for further research on data curation.
Large Scale Transfer Learning for Tabular Data via Language Modeling
Jun 17, 2024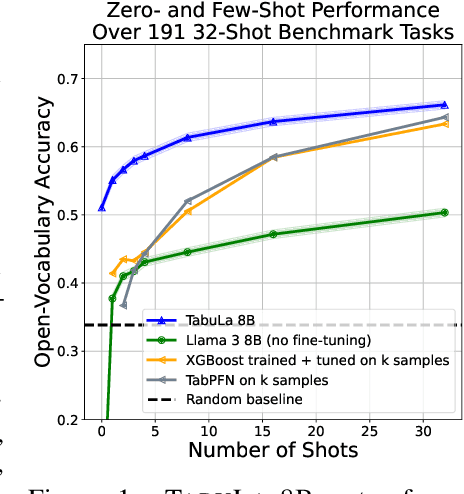


Tabular data -- structured, heterogeneous, spreadsheet-style data with rows and columns -- is widely used in practice across many domains. However, while recent foundation models have reduced the need for developing task-specific datasets and predictors in domains such as language modeling and computer vision, this transfer learning paradigm has not had similar impact in the tabular domain. In this work, we seek to narrow this gap and present TabuLa-8B, a language model for tabular prediction. We define a process for extracting a large, high-quality training dataset from the TabLib corpus, proposing methods for tabular data filtering and quality control. Using the resulting dataset, which comprises over 1.6B rows from 3.1M unique tables, we fine-tune a Llama 3-8B large language model (LLM) for tabular data prediction (classification and binned regression) using a novel packing and attention scheme for tabular prediction. Through evaluation across a test suite of 329 datasets, we find that TabuLa-8B has zero-shot accuracy on unseen tables that is over 15 percentage points (pp) higher than random guessing, a feat that is not possible with existing state-of-the-art tabular prediction models (e.g. XGBoost, TabPFN). In the few-shot setting (1-32 shots), without any fine-tuning on the target datasets, TabuLa-8B is 5-15 pp more accurate than XGBoost and TabPFN models that are explicitly trained on equal, or even up to 16x more data. We release our model, code, and data along with the publication of this paper.
Benchmarking Distribution Shift in Tabular Data with TableShift
Dec 14, 2023Robustness to distribution shift has become a growing concern for text and image models as they transition from research subjects to deployment in the real world. However, high-quality benchmarks for distribution shift in tabular machine learning tasks are still lacking despite the widespread real-world use of tabular data and differences in the models used for tabular data in comparison to text and images. As a consequence, the robustness of tabular models to distribution shift is poorly understood. To address this issue, we introduce TableShift, a distribution shift benchmark for tabular data. TableShift contains 15 binary classification tasks in total, each with an associated shift, and includes a diverse set of data sources, prediction targets, and distribution shifts. The benchmark covers domains including finance, education, public policy, healthcare, and civic participation, and is accessible using only a few lines of Python code via the TableShift API. We conduct a large-scale study comparing several state-of-the-art tabular data models alongside robust learning and domain generalization methods on the benchmark tasks. Our study demonstrates (1) a linear trend between in-distribution (ID) and out-of-distribution (OOD) accuracy; (2) domain robustness methods can reduce shift gaps but at the cost of reduced ID accuracy; (3) a strong relationship between shift gap (difference between ID and OOD performance) and shifts in the label distribution. The benchmark data, Python package, model implementations, and more information about TableShift are available at https://github.com/mlfoundations/tableshift and https://tableshift.org .
LLark: A Multimodal Foundation Model for Music
Oct 11, 2023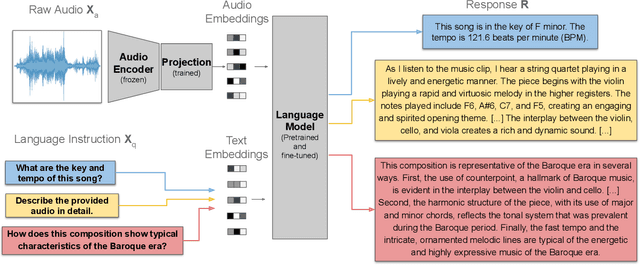
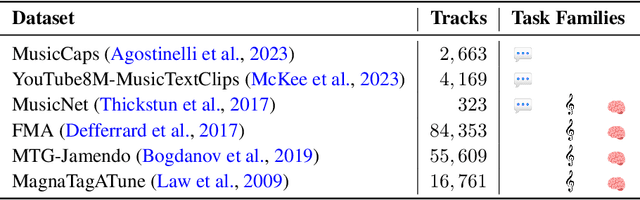
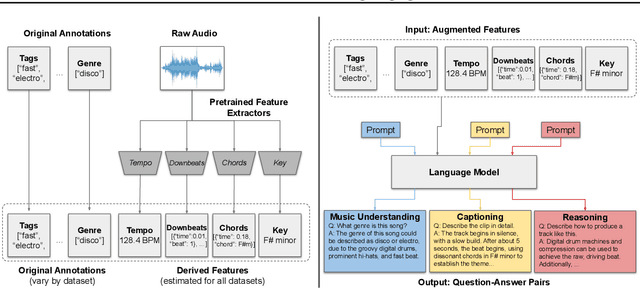
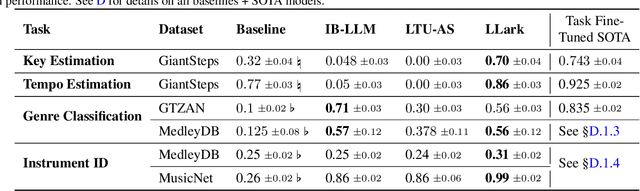
Music has a unique and complex structure which is challenging for both expert humans and existing AI systems to understand, and presents unique challenges relative to other forms of audio. We present LLark, an instruction-tuned multimodal model for music understanding. We detail our process for dataset creation, which involves augmenting the annotations of diverse open-source music datasets and converting them to a unified instruction-tuning format. We propose a multimodal architecture for LLark, integrating a pretrained generative model for music with a pretrained language model. In evaluations on three types of tasks (music understanding, captioning, and reasoning), we show that our model matches or outperforms existing baselines in zero-shot generalization for music understanding, and that humans show a high degree of agreement with the model's responses in captioning and reasoning tasks. LLark is trained entirely from open-source music data and models, and we make our training code available along with the release of this paper. Additional results and audio examples are at https://bit.ly/llark, and our source code is available at https://github.com/spotify-research/llark .
VisIT-Bench: A Benchmark for Vision-Language Instruction Following Inspired by Real-World Use
Aug 12, 2023We introduce VisIT-Bench (Visual InsTruction Benchmark), a benchmark for evaluation of instruction-following vision-language models for real-world use. Our starting point is curating 70 'instruction families' that we envision instruction tuned vision-language models should be able to address. Extending beyond evaluations like VQAv2 and COCO, tasks range from basic recognition to game playing and creative generation. Following curation, our dataset comprises 592 test queries, each with a human-authored instruction-conditioned caption. These descriptions surface instruction-specific factors, e.g., for an instruction asking about the accessibility of a storefront for wheelchair users, the instruction-conditioned caption describes ramps/potential obstacles. These descriptions enable 1) collecting human-verified reference outputs for each instance; and 2) automatic evaluation of candidate multimodal generations using a text-only LLM, aligning with human judgment. We quantify quality gaps between models and references using both human and automatic evaluations; e.g., the top-performing instruction-following model wins against the GPT-4 reference in just 27% of the comparison. VisIT-Bench is dynamic to participate, practitioners simply submit their model's response on the project website; Data, code and leaderboard is available at visit-bench.github.io.
OpenFlamingo: An Open-Source Framework for Training Large Autoregressive Vision-Language Models
Aug 07, 2023



We introduce OpenFlamingo, a family of autoregressive vision-language models ranging from 3B to 9B parameters. OpenFlamingo is an ongoing effort to produce an open-source replication of DeepMind's Flamingo models. On seven vision-language datasets, OpenFlamingo models average between 80 - 89% of corresponding Flamingo performance. This technical report describes our models, training data, hyperparameters, and evaluation suite. We share our models and code at https://github.com/mlfoundations/open_flamingo.
Cross-Institutional Transfer Learning for Educational Models: Implications for Model Performance, Fairness, and Equity
May 01, 2023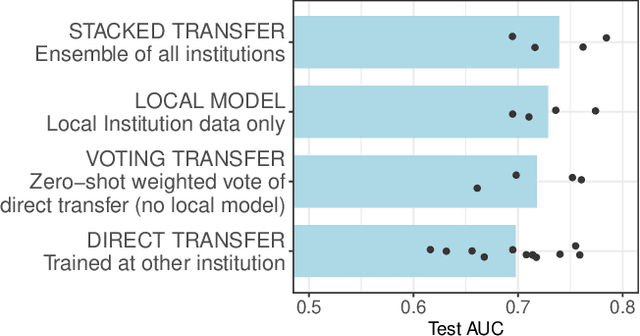
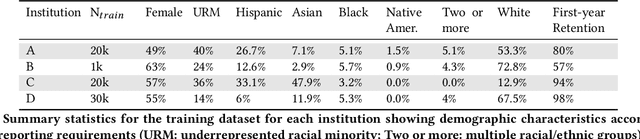
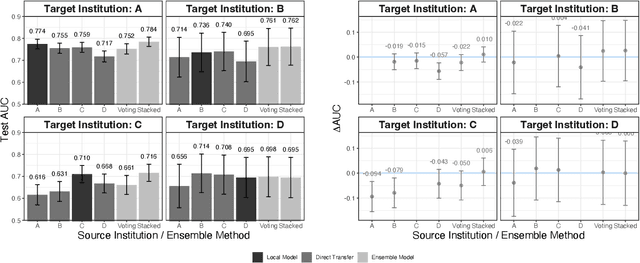
Modern machine learning increasingly supports paradigms that are multi-institutional (using data from multiple institutions during training) or cross-institutional (using models from multiple institutions for inference), but the empirical effects of these paradigms are not well understood. This study investigates cross-institutional learning via an empirical case study in higher education. We propose a framework and metrics for assessing the utility and fairness of student dropout prediction models that are transferred across institutions. We examine the feasibility of cross-institutional transfer under real-world data- and model-sharing constraints, quantifying model biases for intersectional student identities, characterizing potential disparate impact due to these biases, and investigating the impact of various cross-institutional ensembling approaches on fairness and overall model performance. We perform this analysis on data representing over 200,000 enrolled students annually from four universities without sharing training data between institutions. We find that a simple zero-shot cross-institutional transfer procedure can achieve similar performance to locally-trained models for all institutions in our study, without sacrificing model fairness. We also find that stacked ensembling provides no additional benefits to overall performance or fairness compared to either a local model or the zero-shot transfer procedure we tested. We find no evidence of a fairness-accuracy tradeoff across dozens of models and transfer schemes evaluated. Our auditing procedure also highlights the importance of intersectional fairness analysis, revealing performance disparities at the intersection of sensitive identity groups that are concealed under one-dimensional analysis.
* Code to reproduce our experiments is available at https://github.com/educational-technology-collective/cross-institutional-transfer-learning-facct-2023