 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing LLM-Based Data Annotation with Error Decomposition
Jan 17, 2026Large language models offer a scalable alternative to human coding for data annotation tasks, enabling the scale-up of research across data-intensive domains. While LLMs are already achieving near-human accuracy on objective annotation tasks, their performance on subjective annotation tasks, such as those involving psychological constructs, is less consistent and more prone to errors. Standard evaluation practices typically collapse all annotation errors into a single alignment metric, but this simplified approach may obscure different kinds of errors that affect final analytical conclusions in different ways. Here, we propose a diagnostic evaluation paradigm that incorporates a human-in-the-loop step to separate task-inherent ambiguity from model-driven inaccuracies and assess annotation quality in terms of their potential downstream impacts. We refine this paradigm on ordinal annotation tasks, which are common in subjective annotation. The refined paradigm includes: (1) a diagnostic taxonomy that categorizes LLM annotation errors along two dimensions: source (model-specific vs. task-inherent) and type (boundary ambiguity vs. conceptual misidentification); (2) a lightweight human annotation test to estimate task-inherent ambiguity from LLM annotations; and (3) a computational method to decompose observed LLM annotation errors following our taxonomy. We validate this paradigm on four educational annotation tasks, demonstrating both its conceptual validity and practical utility. Theoretically, our work provides empirical evidence for why excessively high alignment is unrealistic in specific annotation tasks and why single alignment metrics inadequately reflect the quality of LLM annotations. In practice, our paradigm can be a low-cost diagnostic tool that assesses the suitability of a given task for LLM annotation and provides actionable insights for further technical optimization.
AI-exposed jobs deteriorated before ChatGPT
Jan 05, 2026Public debate links worsening job prospects for AI-exposed occupations to the release of ChatGPT in late 2022. Using monthly U.S. unemployment insurance records, we measure occupation- and location-specific unemployment risk and find that risk rose in AI-exposed occupations beginning in early 2022, months before ChatGPT. Analyzing millions of LinkedIn profiles, we show that graduate cohorts from 2021 onward entered AI-exposed jobs at lower rates than earlier cohorts, with gaps opening before late 2022. Finally, from millions of university syllabi, we find that graduates taking more AI-exposed curricula had higher first-job pay and shorter job searches after ChatGPT. Together, these results point to forces pre-dating generative AI and to the ongoing value of LLM-relevant education.
Fairness Hub Technical Briefs: Definition and Detection of Distribution Shift
May 23, 2024Distribution shift is a common situation in machine learning tasks, where the data used for training a model is different from the data the model is applied to in the real world. This issue arises across multiple technical settings: from standard prediction tasks, to time-series forecasting, and to more recent applications of large language models (LLMs). This mismatch can lead to performance reductions, and can be related to a multiplicity of factors: sampling issues and non-representative data, changes in the environment or policies, or the emergence of previously unseen scenarios. This brief focuses on the definition and detection of distribution shifts in educational settings. We focus on standard prediction problems, where the task is to learn a model that takes in a series of input (predictors) $X=(x_1,x_2,...,x_m)$ and produces an output $Y=f(X)$.
A national longitudinal dataset of skills taught in U.S. higher education curricula
Apr 19, 2024Higher education plays a critical role in driving an innovative economy by equipping students with knowledge and skills demanded by the workforce. While researchers and practitioners have developed data systems to track detailed occupational skills, such as those established by the U.S. Department of Labor (DOL), much less effort has been made to document skill development in higher education at a similar granularity. Here, we fill this gap by presenting a longitudinal dataset of skills inferred from over three million course syllabi taught at nearly three thousand U.S. higher education institutions. To construct this dataset, we apply natural language processing to extract from course descriptions detailed workplace activities (DWAs) used by the DOL to describe occupations. We then aggregate these DWAs to create skill profiles for institutions and academic majors. Our dataset offers a large-scale representation of college-educated workers and their role in the economy. To showcase the utility of this dataset, we use it to 1) compare the similarity of skills taught and skills in the workforce according to the US Bureau of Labor Statistics, 2) estimate gender differences in acquired skills based on enrollment data, 3) depict temporal trends in the skills taught in social science curricula, and 4) connect college majors' skill distinctiveness to salary differences of graduates. Overall, this dataset can enable new research on the source of skills in the context of workforce development and provide actionable insights for shaping the future of higher education to meet evolving labor demands especially in the face of new technologies.
Temporal and Between-Group Variability in College Dropout Prediction
Jan 12, 2024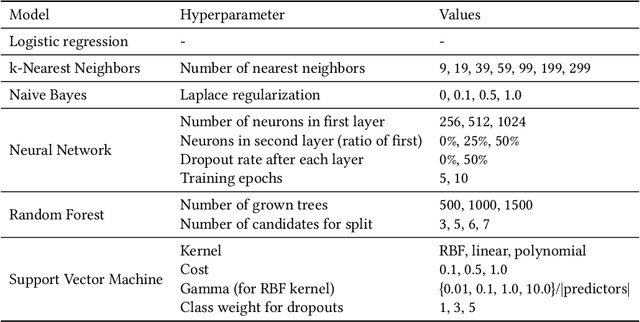


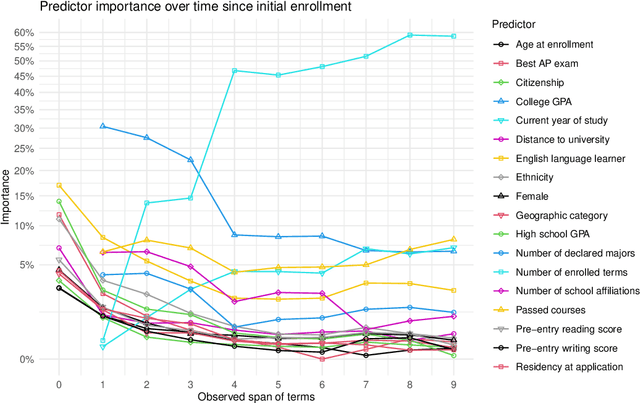
Large-scale administrative data is a common input in early warning systems for college dropout in higher education. Still, the terminology and methodology vary significantly across existing studies, and the implications of different modeling decisions are not fully understood. This study provides a systematic evaluation of contributing factors and predictive performance of machine learning models over time and across different student groups. Drawing on twelve years of administrative data at a large public university in the US, we find that dropout prediction at the end of the second year has a 20% higher AUC than at the time of enrollment in a Random Forest model. Also, most predictive factors at the time of enrollment, including demographics and high school performance, are quickly superseded in predictive importance by college performance and in later stages by enrollment behavior. Regarding variability across student groups, college GPA has more predictive value for students from traditionally disadvantaged backgrounds than their peers. These results can help researchers and administrators understand the comparative value of different data sources when building early warning systems and optimizing decisions under specific policy goals.
Fairness Hub Technical Briefs: AUC Gap
Sep 25, 2023To measure bias, we encourage teams to consider using AUC Gap: the absolute difference between the highest and lowest test AUC for subgroups (e.g., gender, race, SES, prior knowledge). It is agnostic to the AI/ML algorithm used and it captures the disparity in model performance for any number of subgroups, which enables non-binary fairness assessments such as for intersectional identity groups. The teams use a wide range of AI/ML models in pursuit of a common goal of doubling math achievement in low-income middle schools. Ensuring that the models, which are trained on datasets collected in many different contexts, do not introduce or amplify biases is important for achieving the goal. We offer here a versatile and easy-to-compute measure of model bias for all the teams in order to create a common benchmark and an analytical basis for sharing what strategies have worked for different teams.
Cross-Institutional Transfer Learning for Educational Models: Implications for Model Performance, Fairness, and Equity
May 01, 2023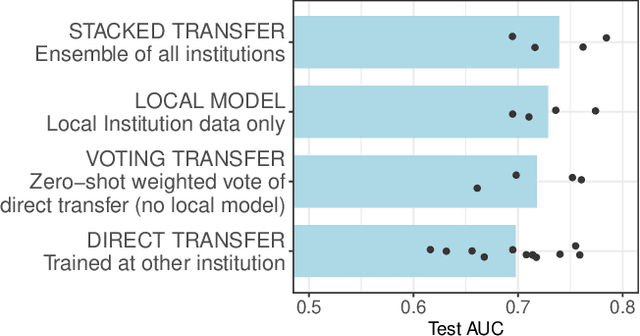
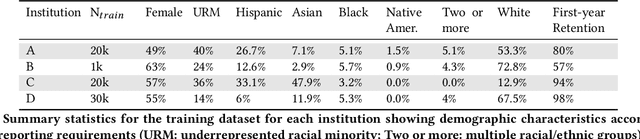
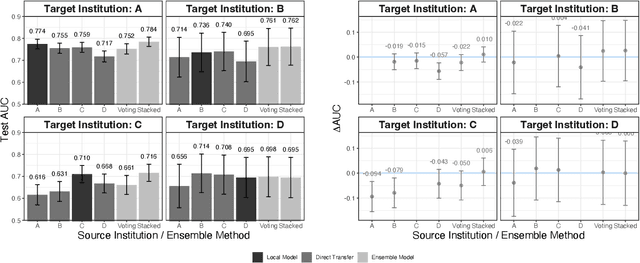
Modern machine learning increasingly supports paradigms that are multi-institutional (using data from multiple institutions during training) or cross-institutional (using models from multiple institutions for inference), but the empirical effects of these paradigms are not well understood. This study investigates cross-institutional learning via an empirical case study in higher education. We propose a framework and metrics for assessing the utility and fairness of student dropout prediction models that are transferred across institutions. We examine the feasibility of cross-institutional transfer under real-world data- and model-sharing constraints, quantifying model biases for intersectional student identities, characterizing potential disparate impact due to these biases, and investigating the impact of various cross-institutional ensembling approaches on fairness and overall model performance. We perform this analysis on data representing over 200,000 enrolled students annually from four universities without sharing training data between institutions. We find that a simple zero-shot cross-institutional transfer procedure can achieve similar performance to locally-trained models for all institutions in our study, without sacrificing model fairness. We also find that stacked ensembling provides no additional benefits to overall performance or fairness compared to either a local model or the zero-shot transfer procedure we tested. We find no evidence of a fairness-accuracy tradeoff across dozens of models and transfer schemes evaluated. Our auditing procedure also highlights the importance of intersectional fairness analysis, revealing performance disparities at the intersection of sensitive identity groups that are concealed under one-dimensional analysis.
* Code to reproduce our experiments is available at https://github.com/educational-technology-collective/cross-institutional-transfer-learning-facct-2023
A Robust Approach for the Decomposition of High-Energy-Consuming Industrial Loads with Deep Learning
Mar 11, 2022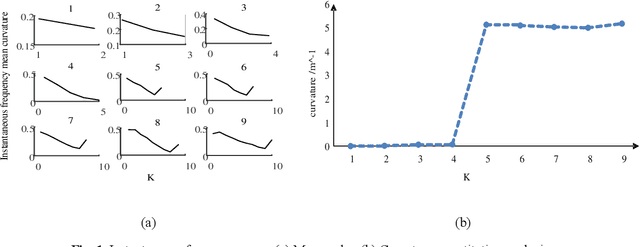

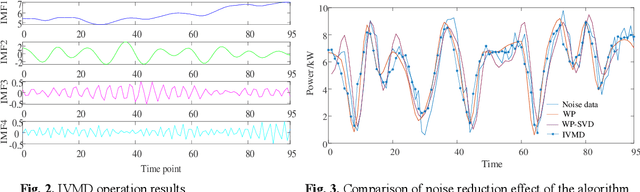

The knowledge of the users' electricity consumption pattern is an important coordinating mechanism between the utility company and the electricity consumers in terms of key decision makings. The load decomposition is therefore crucial to reveal the underlying relationship between the load consumption and its characteristics. However, load decomposition is conventionally performed on the residential and commercial loads, and adequate consideration has not been given to the high-energy-consuming industrial loads leading to inefficient results. This paper thus focuses on the load decomposition of the industrial park loads (IPL). The commonly used parameters in a conventional method are however inapplicable in high-energy-consuming industrial loads. Therefore, a more robust approach is developed comprising a three-algorithm model to achieve this goal on the IPL. First, the improved variational mode decomposition (IVMD) algorithm is introduced to denoise the training data of the IPL and improve its stability. Secondly, the convolutional neural network (CNN) and simple recurrent units (SRU) joint algorithms are used to achieve a non-intrusive and non-invasive decomposition process of the IPL using a double-layer deep learning network based on the IPL characteristics. Specifically, CNN is used to extract the IPL data characteristics while the improved long and short-term memory (LSTM) network, SRU, is adopted to develop the decomposition model and further train the load data. Through the robust decomposition process, the underlying relationship in the load consumption is extracted. The results obtained from the numerical examples show that this approach outperforms the state-of-the-art in the conventional decomposition process.