 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFairness Hub Technical Briefs: Definition and Detection of Distribution Shift
May 23, 2024Distribution shift is a common situation in machine learning tasks, where the data used for training a model is different from the data the model is applied to in the real world. This issue arises across multiple technical settings: from standard prediction tasks, to time-series forecasting, and to more recent applications of large language models (LLMs). This mismatch can lead to performance reductions, and can be related to a multiplicity of factors: sampling issues and non-representative data, changes in the environment or policies, or the emergence of previously unseen scenarios. This brief focuses on the definition and detection of distribution shifts in educational settings. We focus on standard prediction problems, where the task is to learn a model that takes in a series of input (predictors) $X=(x_1,x_2,...,x_m)$ and produces an output $Y=f(X)$.
Fairness Hub Technical Briefs: AUC Gap
Sep 25, 2023To measure bias, we encourage teams to consider using AUC Gap: the absolute difference between the highest and lowest test AUC for subgroups (e.g., gender, race, SES, prior knowledge). It is agnostic to the AI/ML algorithm used and it captures the disparity in model performance for any number of subgroups, which enables non-binary fairness assessments such as for intersectional identity groups. The teams use a wide range of AI/ML models in pursuit of a common goal of doubling math achievement in low-income middle schools. Ensuring that the models, which are trained on datasets collected in many different contexts, do not introduce or amplify biases is important for achieving the goal. We offer here a versatile and easy-to-compute measure of model bias for all the teams in order to create a common benchmark and an analytical basis for sharing what strategies have worked for different teams.
Cross-Institutional Transfer Learning for Educational Models: Implications for Model Performance, Fairness, and Equity
May 01, 2023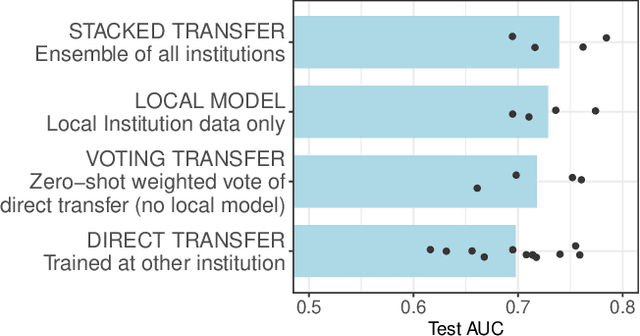
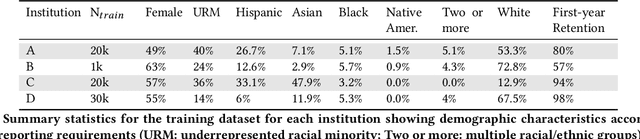
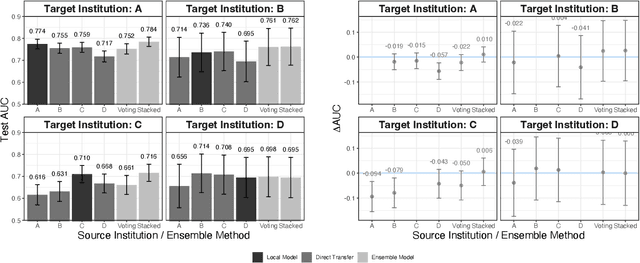
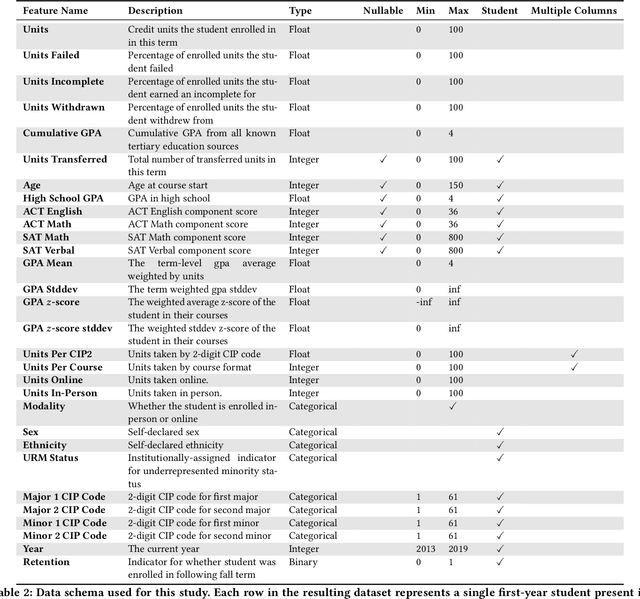
Modern machine learning increasingly supports paradigms that are multi-institutional (using data from multiple institutions during training) or cross-institutional (using models from multiple institutions for inference), but the empirical effects of these paradigms are not well understood. This study investigates cross-institutional learning via an empirical case study in higher education. We propose a framework and metrics for assessing the utility and fairness of student dropout prediction models that are transferred across institutions. We examine the feasibility of cross-institutional transfer under real-world data- and model-sharing constraints, quantifying model biases for intersectional student identities, characterizing potential disparate impact due to these biases, and investigating the impact of various cross-institutional ensembling approaches on fairness and overall model performance. We perform this analysis on data representing over 200,000 enrolled students annually from four universities without sharing training data between institutions. We find that a simple zero-shot cross-institutional transfer procedure can achieve similar performance to locally-trained models for all institutions in our study, without sacrificing model fairness. We also find that stacked ensembling provides no additional benefits to overall performance or fairness compared to either a local model or the zero-shot transfer procedure we tested. We find no evidence of a fairness-accuracy tradeoff across dozens of models and transfer schemes evaluated. Our auditing procedure also highlights the importance of intersectional fairness analysis, revealing performance disparities at the intersection of sensitive identity groups that are concealed under one-dimensional analysis.
* Code to reproduce our experiments is available at https://github.com/educational-technology-collective/cross-institutional-transfer-learning-facct-2023