 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomating Human Tutor-Style Programming Feedback: Leveraging GPT-4 Tutor Model for Hint Generation and GPT-3.5 Student Model for Hint Validation
Oct 05, 2023



Generative AI and large language models hold great promise in enhancing programming education by automatically generating individualized feedback for students. We investigate the role of generative AI models in providing human tutor-style programming hints to help students resolve errors in their buggy programs. Recent works have benchmarked state-of-the-art models for various feedback generation scenarios; however, their overall quality is still inferior to human tutors and not yet ready for real-world deployment. In this paper, we seek to push the limits of generative AI models toward providing high-quality programming hints and develop a novel technique, GPT4Hints-GPT3.5Val. As a first step, our technique leverages GPT-4 as a ``tutor'' model to generate hints -- it boosts the generative quality by using symbolic information of failing test cases and fixes in prompts. As a next step, our technique leverages GPT-3.5, a weaker model, as a ``student'' model to further validate the hint quality -- it performs an automatic quality validation by simulating the potential utility of providing this feedback. We show the efficacy of our technique via extensive evaluation using three real-world datasets of Python programs covering a variety of concepts ranging from basic algorithms to regular expressions and data analysis using pandas library.
Cross-Institutional Transfer Learning for Educational Models: Implications for Model Performance, Fairness, and Equity
May 01, 2023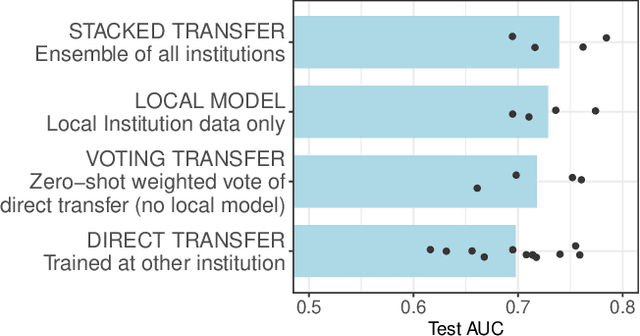
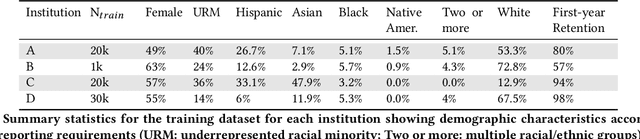
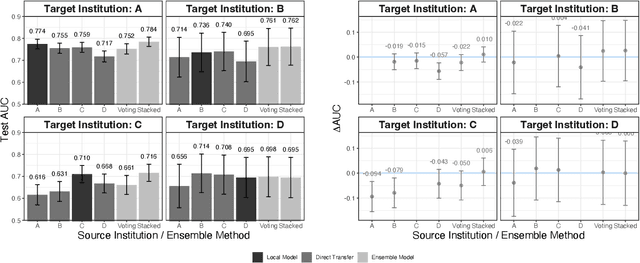
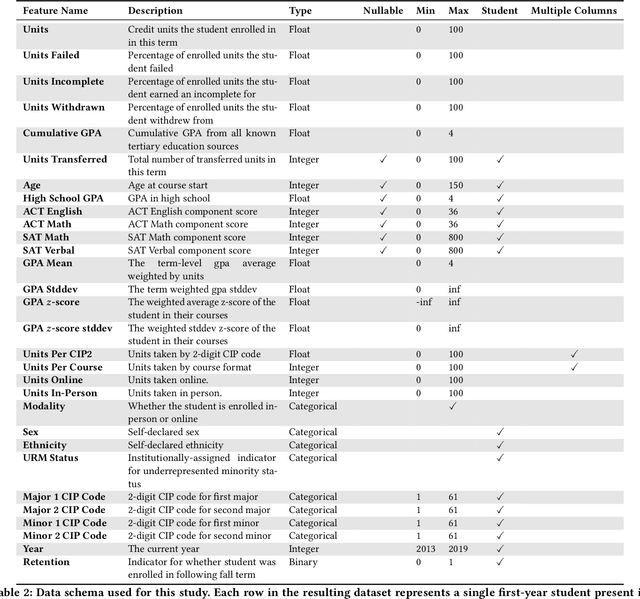
Modern machine learning increasingly supports paradigms that are multi-institutional (using data from multiple institutions during training) or cross-institutional (using models from multiple institutions for inference), but the empirical effects of these paradigms are not well understood. This study investigates cross-institutional learning via an empirical case study in higher education. We propose a framework and metrics for assessing the utility and fairness of student dropout prediction models that are transferred across institutions. We examine the feasibility of cross-institutional transfer under real-world data- and model-sharing constraints, quantifying model biases for intersectional student identities, characterizing potential disparate impact due to these biases, and investigating the impact of various cross-institutional ensembling approaches on fairness and overall model performance. We perform this analysis on data representing over 200,000 enrolled students annually from four universities without sharing training data between institutions. We find that a simple zero-shot cross-institutional transfer procedure can achieve similar performance to locally-trained models for all institutions in our study, without sacrificing model fairness. We also find that stacked ensembling provides no additional benefits to overall performance or fairness compared to either a local model or the zero-shot transfer procedure we tested. We find no evidence of a fairness-accuracy tradeoff across dozens of models and transfer schemes evaluated. Our auditing procedure also highlights the importance of intersectional fairness analysis, revealing performance disparities at the intersection of sensitive identity groups that are concealed under one-dimensional analysis.
* Code to reproduce our experiments is available at https://github.com/educational-technology-collective/cross-institutional-transfer-learning-facct-2023
MORF: A Framework for Predictive Modeling and Replication At Scale With Privacy-Restricted MOOC Data
Aug 21, 2018
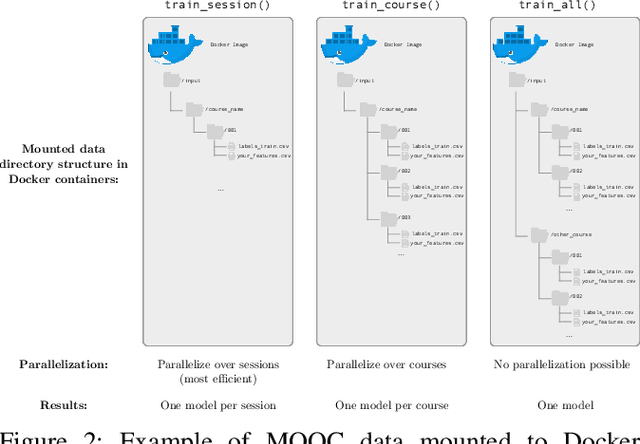

Big data repositories from online learning platforms such as Massive Open Online Courses (MOOCs) represent an unprecedented opportunity to advance research on education at scale and impact a global population of learners. To date, such research has been hindered by poor reproducibility and a lack of replication, largely due to three types of barriers: experimental, inferential, and data. We present a novel system for large-scale computational research, the MOOC Replication Framework (MORF), to jointly address these barriers. We discuss MORF's architecture, an open-source platform-as-a-service (PaaS) which includes a simple, flexible software API providing for multiple modes of research (predictive modeling or production rule analysis) integrated with a high-performance computing environment. All experiments conducted on MORF use executable Docker containers which ensure complete reproducibility while allowing for the use of any software or language which can be installed in the linux-based Docker container. Each experimental artifact is assigned a DOI and made publicly available. MORF has the potential to accelerate and democratize research on its massive data repository, which currently includes over 200 MOOCs, as demonstrated by initial research conducted on the platform. We also highlight ways in which MORF represents a solution template to a more general class of problems faced by computational researchers in other domains.
Dropout Model Evaluation in MOOCs
Feb 16, 2018


The field of learning analytics needs to adopt a more rigorous approach for predictive model evaluation that matches the complex practice of model-building. In this work, we present a procedure to statistically test hypotheses about model performance which goes beyond the state-of-the-practice in the community to analyze both algorithms and feature extraction methods from raw data. We apply this method to a series of algorithms and feature sets derived from a large sample of Massive Open Online Courses (MOOCs). While a complete comparison of all potential modeling approaches is beyond the scope of this paper, we show that this approach reveals a large gap in dropout prediction performance between forum-, assignment-, and clickstream-based feature extraction methods, where the latter is significantly better than the former two, which are in turn indistinguishable from one another. This work has methodological implications for evaluating predictive or AI-based models of student success, and practical implications for the design and targeting of at-risk student models and interventions.