 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSynthesizing High-Quality Programming Tasks with LLM-based Expert and Student Agents
Apr 10, 2025Generative AI is transforming computing education by enabling the automatic generation of personalized content and feedback. We investigate its capabilities in providing high-quality programming tasks to students. Despite promising advancements in task generation, a quality gap remains between AI-generated and expert-created tasks. The AI-generated tasks may not align with target programming concepts, could be incomprehensible for students to solve, or may contain critical issues such as incorrect tests. Existing works often require interventions from human teachers for validation. We address these challenges by introducing PyTaskSyn, a novel synthesis technique that first generates a programming task and then decides whether it meets certain quality criteria to be given to students. The key idea is to break this process into multiple stages performed by expert and student agents simulated using both strong and weaker generative models. Through extensive evaluation, we show that PyTaskSyn significantly improves task quality compared to baseline techniques and showcases the importance of each specialized agent type in our validation pipeline. Additionally, we conducted user studies using our publicly available web application and show that PyTaskSyn can deliver high-quality programming tasks comparable to expert-designed ones while reducing workload and costs, and being more engaging than programming tasks that are available in online resources.
Prompt Programming: A Platform for Dialogue-based Computational Problem Solving with Generative AI Models
Mar 06, 2025Computing students increasingly rely on generative AI tools for programming assistance, often without formal instruction or guidance. This highlights a need to teach students how to effectively interact with AI models, particularly through natural language prompts, to generate and critically evaluate code for solving computational tasks. To address this, we developed a novel platform for prompt programming that enables authentic dialogue-based interactions, supports problems involving multiple interdependent functions, and offers on-request execution of generated code. Data analysis from over 900 students in an introductory programming course revealed high engagement, with the majority of prompts occurring within multi-turn dialogues. Problems with multiple interdependent functions encouraged iterative refinement, with progression graphs highlighting several common strategies. Students were highly selective about the code they chose to test, suggesting that on-request execution of generated code promoted critical thinking. Given the growing importance of learning dialogue-based programming with AI, we provide this tool as a publicly accessible resource, accompanied by a corpus of programming problems for educational use.
BugSpotter: Automated Generation of Code Debugging Exercises
Nov 25, 2024
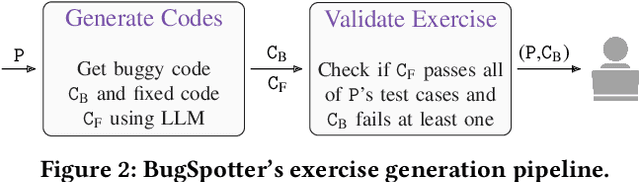

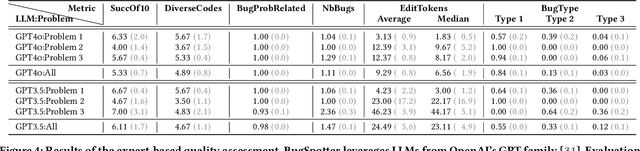
Debugging is an essential skill when learning to program, yet its instruction and emphasis often vary widely across introductory courses. In the era of code-generating large language models (LLMs), the ability for students to reason about code and identify errors is increasingly important. However, students frequently resort to trial-and-error methods to resolve bugs without fully understanding the underlying issues. Developing the ability to identify and hypothesize the cause of bugs is crucial but can be time-consuming to teach effectively through traditional means. This paper introduces BugSpotter, an innovative tool that leverages an LLM to generate buggy code from a problem description and verify the synthesized bugs via a test suite. Students interact with BugSpotter by designing failing test cases, where the buggy code's output differs from the expected result as defined by the problem specification. This not only provides opportunities for students to enhance their debugging skills, but also to practice reading and understanding problem specifications. We deployed BugSpotter in a large classroom setting and compared the debugging exercises it generated to exercises hand-crafted by an instructor for the same problems. We found that the LLM-generated exercises produced by BugSpotter varied in difficulty and were well-matched to the problem specifications. Importantly, the LLM-generated exercises were comparable to those manually created by instructors with respect to student performance, suggesting that BugSpotter could be an effective and efficient aid for learning debugging.
Automated Generation of Code Debugging Exercises
Nov 21, 2024Debugging is an essential skill when learning to program, yet its instruction and emphasis often vary widely across introductory courses. In the era of code-generating large language models (LLMs), the ability for students to reason about code and identify errors is increasingly important. However, students frequently resort to trial-and-error methods to resolve bugs without fully understanding the underlying issues. Developing the ability to identify and hypothesize the cause of bugs is crucial but can be time-consuming to teach effectively through traditional means. This paper introduces BugSpotter, an innovative tool that leverages an LLM to generate buggy code from a problem description and verify the synthesized bugs via a test suite. Students interact with BugSpotter by designing failing test cases, where the buggy code's output differs from the expected result as defined by the problem specification. This not only provides opportunities for students to enhance their debugging skills, but also to practice reading and understanding problem specifications. We deployed BugSpotter in a large classroom setting and compared the debugging exercises it generated to exercises hand-crafted by an instructor for the same problems. We found that the LLM-generated exercises produced by BugSpotter varied in difficulty and were well-matched to the problem specifications. Importantly, the LLM-generated exercises were comparable to those manually created by instructors with respect to student performance, suggesting that BugSpotter could be an effective and efficient aid for learning debugging.
Benchmarking Generative Models on Computational Thinking Tests in Elementary Visual Programming
Jun 14, 2024Generative models have demonstrated human-level proficiency in various benchmarks across domains like programming, natural sciences, and general knowledge. Despite these promising results on competitive benchmarks, they still struggle with seemingly simple problem-solving tasks typically carried out by elementary-level students. How do state-of-the-art models perform on standardized tests designed to assess computational thinking and problem-solving skills at schools? In this paper, we curate a novel benchmark involving computational thinking tests grounded in elementary visual programming domains. Our initial results show that state-of-the-art models like GPT-4o and Llama3 barely match the performance of an average school student. To further boost the performance of these models, we fine-tune them using a novel synthetic data generation methodology. The key idea is to develop a comprehensive dataset using symbolic methods that capture different skill levels, ranging from recognition of visual elements to multi-choice quizzes to synthesis-style tasks. We showcase how various aspects of symbolic information in synthetic data help improve fine-tuned models' performance. We will release the full implementation and datasets to facilitate further research on enhancing computational thinking in generative models.
Automating Human Tutor-Style Programming Feedback: Leveraging GPT-4 Tutor Model for Hint Generation and GPT-3.5 Student Model for Hint Validation
Oct 05, 2023



Generative AI and large language models hold great promise in enhancing programming education by automatically generating individualized feedback for students. We investigate the role of generative AI models in providing human tutor-style programming hints to help students resolve errors in their buggy programs. Recent works have benchmarked state-of-the-art models for various feedback generation scenarios; however, their overall quality is still inferior to human tutors and not yet ready for real-world deployment. In this paper, we seek to push the limits of generative AI models toward providing high-quality programming hints and develop a novel technique, GPT4Hints-GPT3.5Val. As a first step, our technique leverages GPT-4 as a ``tutor'' model to generate hints -- it boosts the generative quality by using symbolic information of failing test cases and fixes in prompts. As a next step, our technique leverages GPT-3.5, a weaker model, as a ``student'' model to further validate the hint quality -- it performs an automatic quality validation by simulating the potential utility of providing this feedback. We show the efficacy of our technique via extensive evaluation using three real-world datasets of Python programs covering a variety of concepts ranging from basic algorithms to regular expressions and data analysis using pandas library.
Generative AI for Programming Education: Benchmarking ChatGPT, GPT-4, and Human Tutors
Jun 30, 2023



Generative AI and large language models hold great promise in enhancing computing education by powering next-generation educational technologies for introductory programming. Recent works have studied these models for different scenarios relevant to programming education; however, these works are limited for several reasons, as they typically consider already outdated models or only specific scenario(s). Consequently, there is a lack of a systematic study that benchmarks state-of-the-art models for a comprehensive set of programming education scenarios. In our work, we systematically evaluate two models, ChatGPT (based on GPT-3.5) and GPT-4, and compare their performance with human tutors for a variety of scenarios. We evaluate using five introductory Python programming problems and real-world buggy programs from an online platform, and assess performance using expert-based annotations. Our results show that GPT-4 drastically outperforms ChatGPT (based on GPT-3.5) and comes close to human tutors' performance for several scenarios. These results also highlight settings where GPT-4 still struggles, providing exciting future directions on developing techniques to improve the performance of these models.
Neural Task Synthesis for Visual Programming
Jun 01, 2023



Generative neural models hold great promise in enhancing programming education by synthesizing new content for students. We seek to design neural models that can automatically generate programming tasks for a given specification in the context of visual programming domains. Despite the recent successes of large generative models like GPT-4, our initial results show that these models are ineffective in synthesizing visual programming tasks and struggle with logical and spatial reasoning. We propose a novel neuro-symbolic technique, NeurTaskSyn, that can synthesize programming tasks for a specification given in the form of desired programming concepts exercised by its solution code and constraints on the visual task. NeurTaskSyn has two components: the first component is trained via imitation learning procedure to generate possible solution codes, and the second component is trained via reinforcement learning procedure to guide an underlying symbolic execution engine that generates visual tasks for these codes. We demonstrate the effectiveness of NeurTaskSyn through an extensive empirical evaluation and a qualitative study on reference tasks taken from the Hour of Code: Classic Maze challenge by Code-dot-org and the Intro to Programming with Karel course by CodeHS-dot-com.