 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRegret-Free Reinforcement Learning for LTL Specifications
Nov 18, 2024Reinforcement learning (RL) is a promising method to learn optimal control policies for systems with unknown dynamics. In particular, synthesizing controllers for safety-critical systems based on high-level specifications, such as those expressed in temporal languages like linear temporal logic (LTL), presents a significant challenge in control systems research. Current RL-based methods designed for LTL tasks typically offer only asymptotic guarantees, which provide no insight into the transient performance during the learning phase. While running an RL algorithm, it is crucial to assess how close we are to achieving optimal behavior if we stop learning. In this paper, we present the first regret-free online algorithm for learning a controller that addresses the general class of LTL specifications over Markov decision processes (MDPs) with a finite set of states and actions. We begin by proposing a regret-free learning algorithm to solve infinite-horizon reach-avoid problems. For general LTL specifications, we show that the synthesis problem can be reduced to a reach-avoid problem when the graph structure is known. Additionally, we provide an algorithm for learning the graph structure, assuming knowledge of a minimum transition probability, which operates independently of the main regret-free algorithm.
Reward Augmentation in Reinforcement Learning for Testing Distributed Systems
Sep 02, 2024Bugs in popular distributed protocol implementations have been the source of many downtimes in popular internet services. We describe a randomized testing approach for distributed protocol implementations based on reinforcement learning. Since the natural reward structure is very sparse, the key to successful exploration in reinforcement learning is reward augmentation. We show two different techniques that build on one another. First, we provide a decaying exploration bonus based on the discovery of new states -- the reward decays as the same state is visited multiple times. The exploration bonus captures the intuition from coverage-guided fuzzing of prioritizing new coverage points; in contrast to other schemes, we show that taking the maximum of the bonus and the Q-value leads to more effective exploration. Second, we provide waypoints to the algorithm as a sequence of predicates that capture interesting semantic scenarios. Waypoints exploit designer insight about the protocol and guide the exploration to ``interesting'' parts of the state space. Our reward structure ensures that new episodes can reliably get to deep interesting states even without execution caching. We have implemented our algorithm in Go. Our evaluation on three large benchmarks (RedisRaft, Etcd, and RSL) shows that our algorithm can significantly outperform baseline approaches in terms of coverage and bug finding.
Optimal Integrated Task and Path Planning and Its Application to Multi-Robot Pickup and Delivery
Mar 02, 2024We propose a generic multi-robot planning mechanism that combines an optimal task planner and an optimal path planner to provide a scalable solution for complex multi-robot planning problems. The Integrated planner, through the interaction of the task planner and the path planner, produces optimal collision-free trajectories for the robots. We illustrate our general algorithm on an object pick-and-drop planning problem in a warehouse scenario where a group of robots is entrusted with moving objects from one location to another in the workspace. We solve the task planning problem by reducing it into an SMT-solving problem and employing the highly advanced SMT solver Z3 to solve it. To generate collision-free movement of the robots, we extend the state-of-the-art algorithm Conflict Based Search with Precedence Constraints with several domain-specific constraints. We evaluate our integrated task and path planner extensively on various instances of the object pick-and-drop planning problem and compare its performance with a state-of-the-art multi-robot classical planner. Experimental results demonstrate that our planning mechanism can deal with complex planning problems and outperforms a state-of-the-art classical planner both in terms of computation time and the quality of the generated plan.
Satisfiability Checking of Multi-Variable TPTL with Unilateral Intervals Is PSPACE-Complete
Sep 01, 2023We investigate the decidability of the ${0,\infty}$ fragment of Timed Propositional Temporal Logic (TPTL). We show that the satisfiability checking of TPTL$^{0,\infty}$ is PSPACE-complete. Moreover, even its 1-variable fragment (1-TPTL$^{0,\infty}$) is strictly more expressive than Metric Interval Temporal Logic (MITL) for which satisfiability checking is EXPSPACE complete. Hence, we have a strictly more expressive logic with computationally easier satisfiability checking. To the best of our knowledge, TPTL$^{0,\infty}$ is the first multi-variable fragment of TPTL for which satisfiability checking is decidable without imposing any bounds/restrictions on the timed words (e.g. bounded variability, bounded time, etc.). The membership in PSPACE is obtained by a reduction to the emptiness checking problem for a new "non-punctual" subclass of Alternating Timed Automata with multiple clocks called Unilateral Very Weak Alternating Timed Automata (VWATA$^{0,\infty}$) which we prove to be in PSPACE. We show this by constructing a simulation equivalent non-deterministic timed automata whose number of clocks is polynomial in the size of the given VWATA$^{0,\infty}$.
Markov Decision Processes with Time-Varying Geometric Discounting
Jul 19, 2023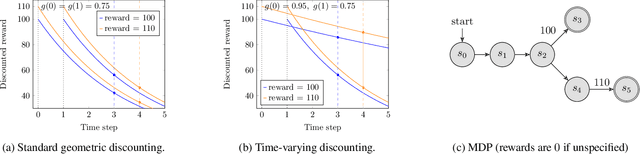

Canonical models of Markov decision processes (MDPs) usually consider geometric discounting based on a constant discount factor. While this standard modeling approach has led to many elegant results, some recent studies indicate the necessity of modeling time-varying discounting in certain applications. This paper studies a model of infinite-horizon MDPs with time-varying discount factors. We take a game-theoretic perspective -- whereby each time step is treated as an independent decision maker with their own (fixed) discount factor -- and we study the subgame perfect equilibrium (SPE) of the resulting game as well as the related algorithmic problems. We present a constructive proof of the existence of an SPE and demonstrate the EXPTIME-hardness of computing an SPE. We also turn to the approximate notion of $\epsilon$-SPE and show that an $\epsilon$-SPE exists under milder assumptions. An algorithm is presented to compute an $\epsilon$-SPE, of which an upper bound of the time complexity, as a function of the convergence property of the time-varying discount factor, is provided.
* 24 pages, 3 figures
Neural Abstraction-Based Controller Synthesis and Deployment
Jul 07, 2023Abstraction-based techniques are an attractive approach for synthesizing correct-by-construction controllers to satisfy high-level temporal requirements. A main bottleneck for successful application of these techniques is the memory requirement, both during controller synthesis and in controller deployment. We propose memory-efficient methods for mitigating the high memory demands of the abstraction-based techniques using neural network representations. To perform synthesis for reach-avoid specifications, we propose an on-the-fly algorithm that relies on compressed neural network representations of the forward and backward dynamics of the system. In contrast to usual applications of neural representations, our technique maintains soundness of the end-to-end process. To ensure this, we correct the output of the trained neural network such that the corrected output representations are sound with respect to the finite abstraction. For deployment, we provide a novel training algorithm to find a neural network representation of the synthesized controller and experimentally show that the controller can be correctly represented as a combination of a neural network and a look-up table that requires a substantially smaller memory. We demonstrate experimentally that our approach significantly reduces the memory requirements of abstraction-based methods. For the selected benchmarks, our approach reduces the memory requirements respectively for the synthesis and deployment by a factor of $1.31\times 10^5$ and $7.13\times 10^3$ on average, and up to $7.54\times 10^5$ and $3.18\times 10^4$. Although this reduction is at the cost of increased off-line computations to train the neural networks, all the steps of our approach are parallelizable and can be implemented on machines with higher number of processing units to reduce the required computational time.
Generative AI for Programming Education: Benchmarking ChatGPT, GPT-4, and Human Tutors
Jun 30, 2023



Generative AI and large language models hold great promise in enhancing computing education by powering next-generation educational technologies for introductory programming. Recent works have studied these models for different scenarios relevant to programming education; however, these works are limited for several reasons, as they typically consider already outdated models or only specific scenario(s). Consequently, there is a lack of a systematic study that benchmarks state-of-the-art models for a comprehensive set of programming education scenarios. In our work, we systematically evaluate two models, ChatGPT (based on GPT-3.5) and GPT-4, and compare their performance with human tutors for a variety of scenarios. We evaluate using five introductory Python programming problems and real-world buggy programs from an online platform, and assess performance using expert-based annotations. Our results show that GPT-4 drastically outperforms ChatGPT (based on GPT-3.5) and comes close to human tutors' performance for several scenarios. These results also highlight settings where GPT-4 still struggles, providing exciting future directions on developing techniques to improve the performance of these models.
Sequential Principal-Agent Problems with Communication: Efficient Computation and Learning
Jun 06, 2023
We study a sequential decision making problem between a principal and an agent with incomplete information on both sides. In this model, the principal and the agent interact in a stochastic environment, and each is privy to observations about the state not available to the other. The principal has the power of commitment, both to elicit information from the agent and to provide signals about her own information. The principal and the agent communicate their signals to each other, and select their actions independently based on this communication. Each player receives a payoff based on the state and their joint actions, and the environment moves to a new state. The interaction continues over a finite time horizon, and both players act to optimize their own total payoffs over the horizon. Our model encompasses as special cases stochastic games of incomplete information and POMDPs, as well as sequential Bayesian persuasion and mechanism design problems. We study both computation of optimal policies and learning in our setting. While the general problems are computationally intractable, we study algorithmic solutions under a conditional independence assumption on the underlying state-observation distributions. We present an polynomial-time algorithm to compute the principal's optimal policy up to an additive approximation. Additionally, we show an efficient learning algorithm in the case where the transition probabilities are not known beforehand. The algorithm guarantees sublinear regret for both players.
Online Reinforcement Learning with Uncertain Episode Lengths
Feb 07, 2023
Existing episodic reinforcement algorithms assume that the length of an episode is fixed across time and known a priori. In this paper, we consider a general framework of episodic reinforcement learning when the length of each episode is drawn from a distribution. We first establish that this problem is equivalent to online reinforcement learning with general discounting where the learner is trying to optimize the expected discounted sum of rewards over an infinite horizon, but where the discounting function is not necessarily geometric. We show that minimizing regret with this new general discounting is equivalent to minimizing regret with uncertain episode lengths. We then design a reinforcement learning algorithm that minimizes regret with general discounting but acts for the setting with uncertain episode lengths. We instantiate our general bound for different types of discounting, including geometric and polynomial discounting. We also show that we can obtain similar regret bounds even when the uncertainty over the episode lengths is unknown, by estimating the unknown distribution over time. Finally, we compare our learning algorithms with existing value-iteration based episodic RL algorithms in a grid-world environment.
Multiparty Motion Coordination: From Choreographies to Robotics Programs
Oct 12, 2020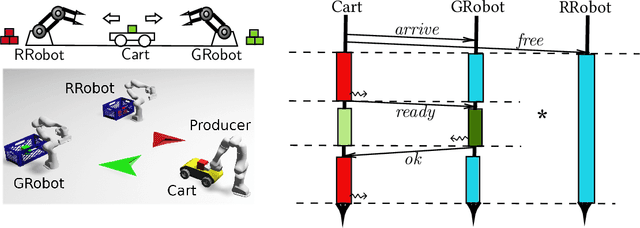



We present a programming model and typing discipline for complex multi-robot coordination programming. Our model encompasses both synchronisation through message passing and continuous-time dynamic motion primitives in physical space. We specify \emph{continuous-time motion primitives} in an assume-guarantee logic that ensures compatibility of motion primitives as well as collision freedom. We specify global behaviour of programs in a \emph{choreographic} type system that extends multiparty session types with jointly executed motion primitives, predicated refinements, as well as a \emph{separating conjunction} that allows reasoning about subsets of interacting robots. We describe a notion of \emph{well-formedness} for global types that ensures motion and communication can be correctly synchronised and provide algorithms for checking well-formedness, projecting a type, and local type checking. A well-typed program is \emph{communication safe}, \emph{motion compatible}, and \emph{collision free}. Our type system provides a compositional approach to ensuring these properties. We have implemented our model on top of the ROS framework. This allows us to program multi-robot coordination scenarios on top of commercial and custom robotics hardware platforms. We show through case studies that we can model and statically verify quite complex manoeuvres involving multiple manipulators and mobile robots---such examples are beyond the scope of previous approaches.