 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobust Black-box Testing of Deep Neural Networks using Co-Domain Coverage
Aug 13, 2024Rigorous testing of machine learning models is necessary for trustworthy deployments. We present a novel black-box approach for generating test-suites for robust testing of deep neural networks (DNNs). Most existing methods create test inputs based on maximizing some "coverage" criterion/metric such as a fraction of neurons activated by the test inputs. Such approaches, however, can only analyze each neuron's behavior or each layer's output in isolation and are unable to capture their collective effect on the DNN's output, resulting in test suites that often do not capture the various failure modes of the DNN adequately. These approaches also require white-box access, i.e., access to the DNN's internals (node activations). We present a novel black-box coverage criterion called Co-Domain Coverage (CDC), which is defined as a function of the model's output and thus takes into account its end-to-end behavior. Subsequently, we develop a new fuzz testing procedure named CoDoFuzz, which uses CDC to guide the fuzzing process to generate a test suite for a DNN. We extensively compare the test suite generated by CoDoFuzz with those generated using several state-of-the-art coverage-based fuzz testing methods for the DNNs trained on six publicly available datasets. Experimental results establish the efficiency and efficacy of CoDoFuzz in generating the largest number of misclassified inputs and the inputs for which the model lacks confidence in its decision.
Counter-example guided Imitation Learning of Feedback Controllers from Temporal Logic Specifications
Mar 25, 2024We present a novel method for imitation learning for control requirements expressed using Signal Temporal Logic (STL). More concretely we focus on the problem of training a neural network to imitate a complex controller. The learning process is guided by efficient data aggregation based on counter-examples and a coverage measure. Moreover, we introduce a method to evaluate the performance of the learned controller via parameterization and parameter estimation of the STL requirements. We demonstrate our approach with a flying robot case study.
Online Concurrent Multi-Robot Coverage Path Planning
Mar 15, 2024Recently, centralized receding horizon online multi-robot coverage path planning algorithms have shown remarkable scalability in thoroughly exploring large, complex, unknown workspaces with many robots. In a horizon, the path planning and the path execution interleave, meaning when the path planning occurs for robots with no paths, the robots with outstanding paths do not execute, and subsequently, when the robots with new or outstanding paths execute to reach respective goals, path planning does not occur for those robots yet to get new paths, leading to wastage of both the robotic and the computation resources. As a remedy, we propose a centralized algorithm that is not horizon-based. It plans paths at any time for a subset of robots with no paths, i.e., who have reached their previously assigned goals, while the rest execute their outstanding paths, thereby enabling concurrent planning and execution. We formally prove that the proposed algorithm ensures complete coverage of an unknown workspace and analyze its time complexity. To demonstrate scalability, we evaluate our algorithm to cover eight large $2$D grid benchmark workspaces with up to 512 aerial and ground robots, respectively. A comparison with a state-of-the-art horizon-based algorithm shows its superiority in completing the coverage with up to 1.6x speedup. For validation, we perform ROS + Gazebo simulations in six 2D grid benchmark workspaces with 10 quadcopters and TurtleBots, respectively. We also successfully conducted one outdoor experiment with three quadcopters and one indoor with two TurtleBots.
Optimal Integrated Task and Path Planning and Its Application to Multi-Robot Pickup and Delivery
Mar 02, 2024We propose a generic multi-robot planning mechanism that combines an optimal task planner and an optimal path planner to provide a scalable solution for complex multi-robot planning problems. The Integrated planner, through the interaction of the task planner and the path planner, produces optimal collision-free trajectories for the robots. We illustrate our general algorithm on an object pick-and-drop planning problem in a warehouse scenario where a group of robots is entrusted with moving objects from one location to another in the workspace. We solve the task planning problem by reducing it into an SMT-solving problem and employing the highly advanced SMT solver Z3 to solve it. To generate collision-free movement of the robots, we extend the state-of-the-art algorithm Conflict Based Search with Precedence Constraints with several domain-specific constraints. We evaluate our integrated task and path planner extensively on various instances of the object pick-and-drop planning problem and compare its performance with a state-of-the-art multi-robot classical planner. Experimental results demonstrate that our planning mechanism can deal with complex planning problems and outperforms a state-of-the-art classical planner both in terms of computation time and the quality of the generated plan.
A Conflict-Aware Optimal Goal Assignment Algorithm for Multi-Robot Systems
Feb 19, 2024The fundamental goal assignment problem for a multi-robot application aims to assign a unique goal to each robot while ensuring collision-free paths, minimizing the total movement cost. A plausible algorithmic solution to this NP-hard problem involves an iterative process that integrates a task planner to compute the goal assignment while ignoring the collision possibilities among the robots and a multi-agent path-finding algorithm to find the collision-free trajectories for a given assignment. This procedure involves a method for computing the next best assignment given the current best assignment. A naive way of computing the next best assignment, as done in the state-of-the-art solutions, becomes a roadblock to achieving scalability in solving the overall problem. To obviate this bottleneck, we propose an efficient conflict-guided method to compute the next best assignment. Additionally, we introduce two more optimizations to the algorithm -- first for avoiding the unconstrained path computations between robot-goal pairs wherever possible, and the second to prevent duplicate constrained path computations for multiple robot-goal pairs. We extensively evaluate our algorithm for up to a hundred robots on several benchmark workspaces. The results demonstrate that the proposed algorithm achieves nearly an order of magnitude speedup over the state-of-the-art algorithm, showcasing its efficacy in real-world scenarios.
Frugal Actor-Critic: Sample Efficient Off-Policy Deep Reinforcement Learning Using Unique Experiences
Feb 05, 2024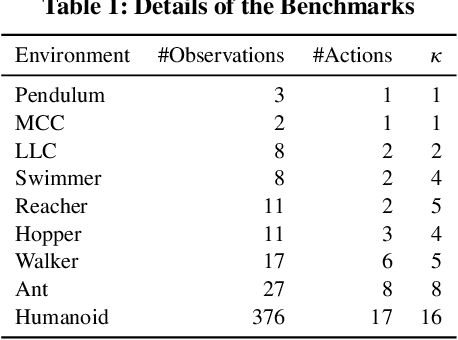
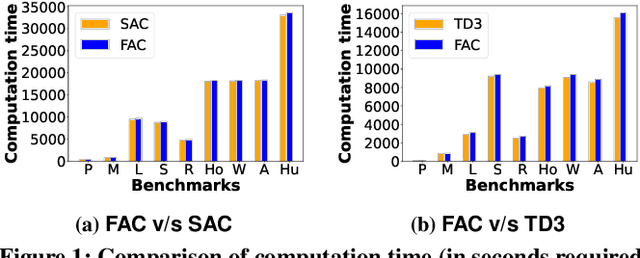
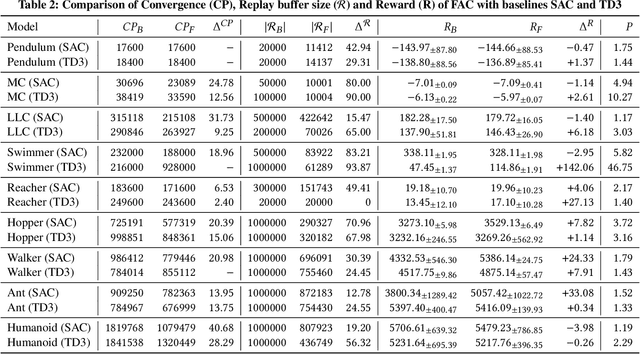
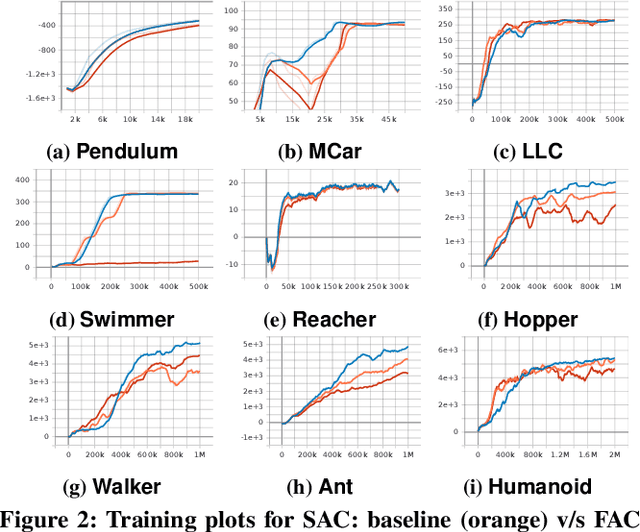
Efficient utilization of the replay buffer plays a significant role in the off-policy actor-critic reinforcement learning (RL) algorithms used for model-free control policy synthesis for complex dynamical systems. We propose a method for achieving sample efficiency, which focuses on selecting unique samples and adding them to the replay buffer during the exploration with the goal of reducing the buffer size and maintaining the independent and identically distributed (IID) nature of the samples. Our method is based on selecting an important subset of the set of state variables from the experiences encountered during the initial phase of random exploration, partitioning the state space into a set of abstract states based on the selected important state variables, and finally selecting the experiences with unique state-reward combination by using a kernel density estimator. We formally prove that the off-policy actor-critic algorithm incorporating the proposed method for unique experience accumulation converges faster than the vanilla off-policy actor-critic algorithm. Furthermore, we evaluate our method by comparing it with two state-of-the-art actor-critic RL algorithms on several continuous control benchmarks available in the Gym environment. Experimental results demonstrate that our method achieves a significant reduction in the size of the replay buffer for all the benchmarks while achieving either faster convergent or better reward accumulation compared to the baseline algorithms.
Online On-Demand Multi-Robot Coverage Path Planning
Feb 28, 2023We present an online centralized path planning algorithm to cover a large, complex, unknown workspace with multiple homogeneous mobile robots. Our algorithm is horizon-based, synchronous, and on-demand. The recently proposed horizon-based synchronous algorithms compute the paths for all the robots in each horizon, significantly increasing the computation burden in large workspaces with many robots. As a remedy, we propose an algorithm that computes the paths for a subset of robots that have traversed previously computed paths entirely (thus on-demand) and reuses the previously computed paths for the other robots. We formally prove that the algorithm guarantees the complete coverage of the unknown workspace. Experimental results show that our algorithm scales to hundreds of robots in large workspaces and consistently outperforms a state-of-the-art online multi-robot centralized coverage path planning algorithm.We also perform ROS+Gazebo simulations in five $2$D grid benchmark workspaces with 10 Quadcopters and one real experiment with two Quadcopters in an outdoor experiment, to establish the practical feasibility of our algorithm.
STL-Based Synthesis of Feedback Controllers Using Reinforcement Learning
Dec 02, 2022
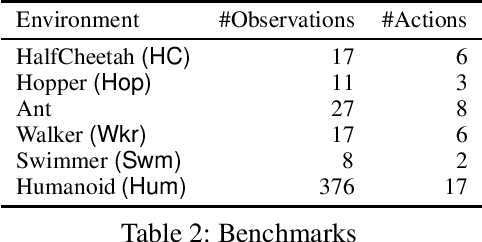

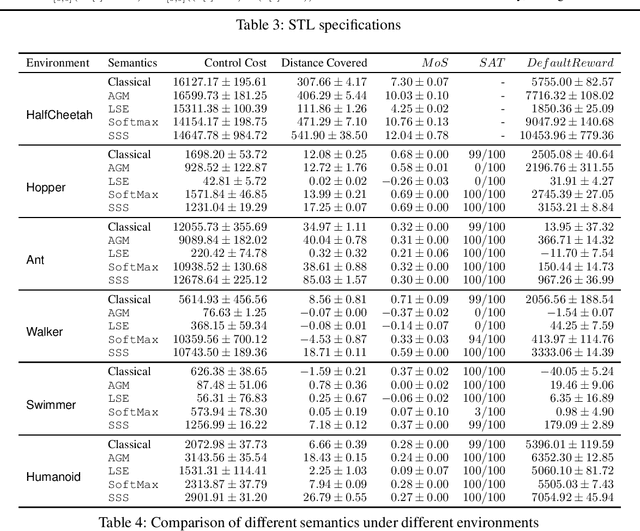
Deep Reinforcement Learning (DRL) has the potential to be used for synthesizing feedback controllers (agents) for various complex systems with unknown dynamics. These systems are expected to satisfy diverse safety and liveness properties best captured using temporal logic. In RL, the reward function plays a crucial role in specifying the desired behaviour of these agents. However, the problem of designing the reward function for an RL agent to satisfy complex temporal logic specifications has received limited attention in the literature. To address this, we provide a systematic way of generating rewards in real-time by using the quantitative semantics of Signal Temporal Logic (STL), a widely used temporal logic to specify the behaviour of cyber-physical systems. We propose a new quantitative semantics for STL having several desirable properties, making it suitable for reward generation. We evaluate our STL-based reinforcement learning mechanism on several complex continuous control benchmarks and compare our STL semantics with those available in the literature in terms of their efficacy in synthesizing the controller agent. Experimental results establish our new semantics to be the most suitable for synthesizing feedback controllers for complex continuous dynamical systems through reinforcement learning.
DT*: Temporal Logic Path Planning in a Dynamic Environment
Mar 04, 2021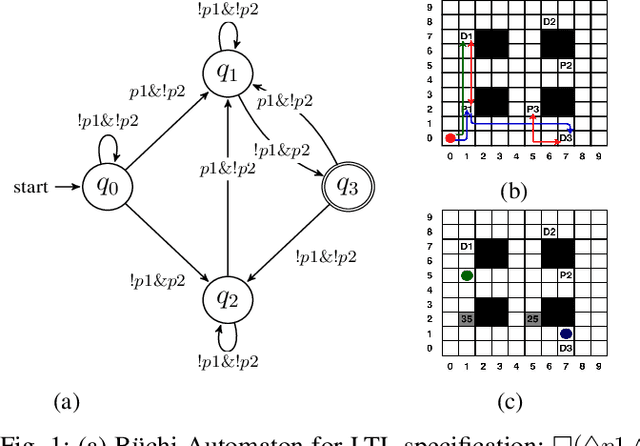
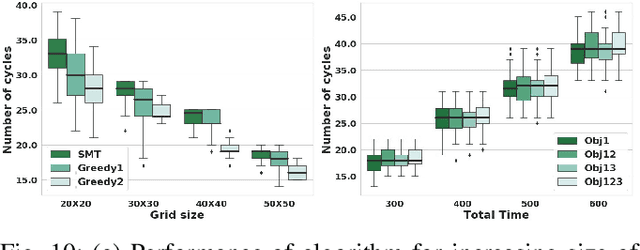
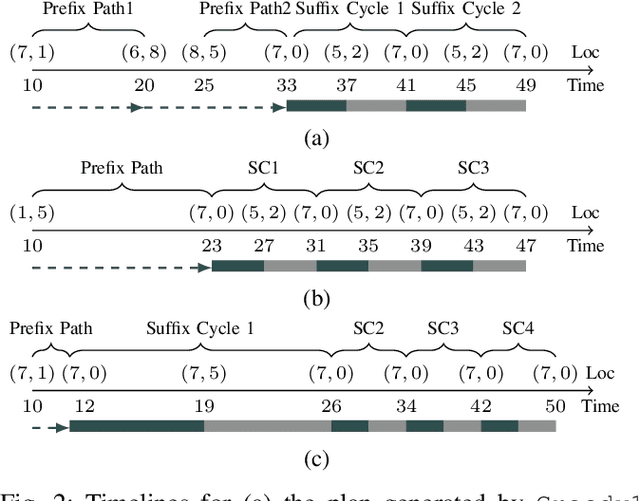
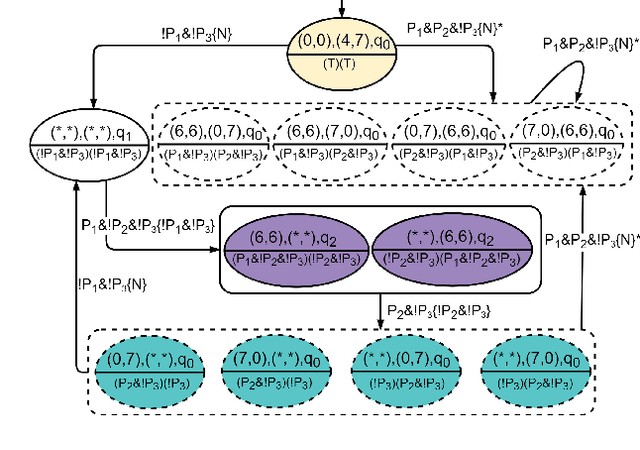
Path planning for a robot is one of the major problems in the area of robotics. When a robot is given a task in the form of a Linear Temporal Logic (LTL) specification such that the task needs to be carried out repetitively, we want the robot to follow the shortest cyclic path so that the number of times the robot completes the mission within a given duration gets maximized. In this paper, we address the LTL path planning problem in a dynamic environment where the newly arrived dynamic obstacles may invalidate some of the available paths at any arbitrary point in time. We present DT*, an SMT-based receding horizon planning strategy that solves an optimization problem repetitively based on the current status of the workspace to lead the robot to follow the best available path in the current situation. We implement our algorithm using the Z3 SMT solver and evaluate it extensively on an LTL specification capturing a pick-and-drop application in a warehouse environment. We compare our SMT-based algorithm with two carefully crafted greedy algorithms. Our experimental results show that the proposed algorithm can deal with the dynamism in the workspace in LTL path planning effectively.
MT* : Multi-Robot Path Planning for Temporal Logic Specifications
Mar 04, 2021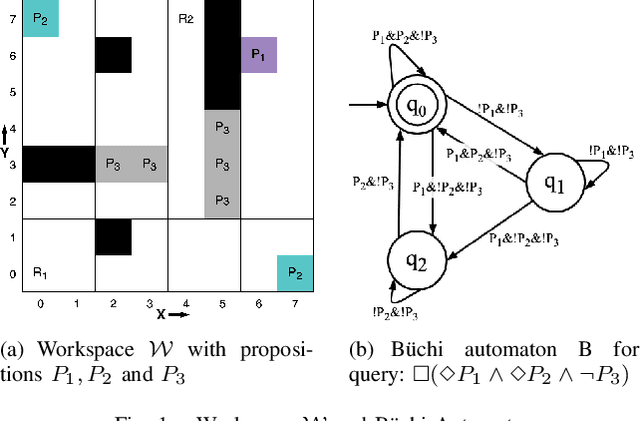
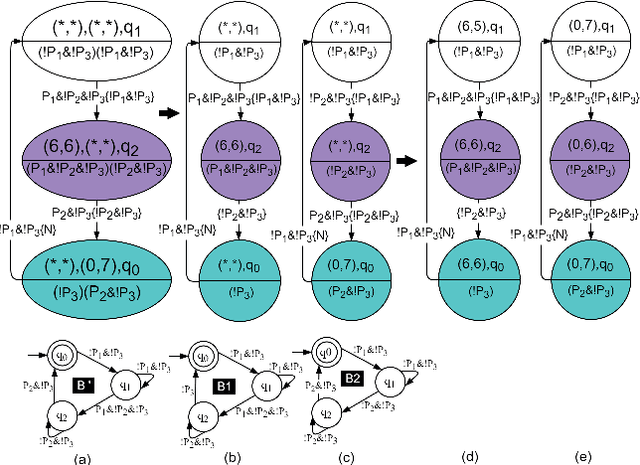
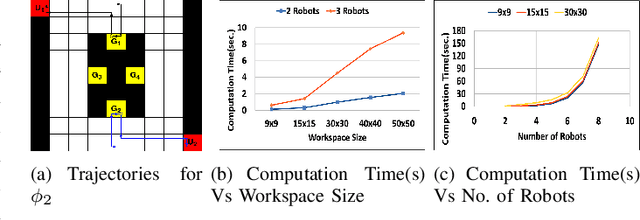
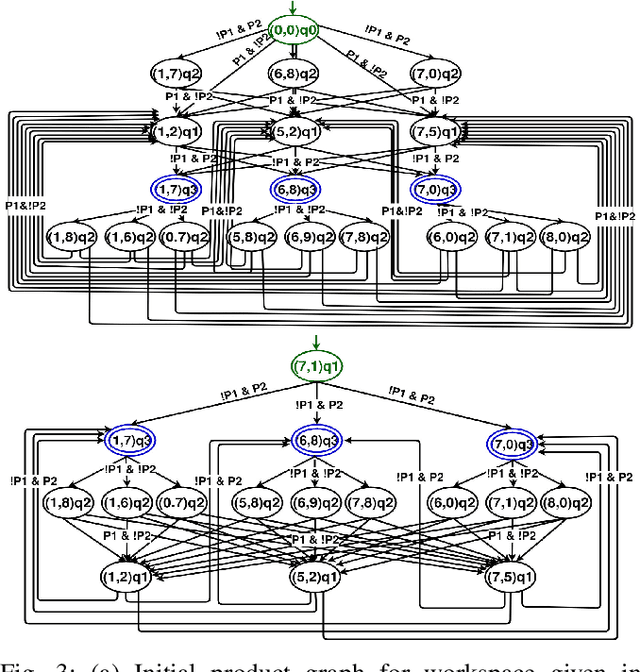
We address the path planning problem for a team of robots satisfying a complex high-level mission specification given in the form of an Linear Temporal Logic (LTL) formula. The state-of-the-art approach to this problem employs the automata-theoretic model checking technique to solve this problem. This approach involves computation of a product graph of the Buchi automaton generated from the LTL specification and a joint transition system which captures the collective motion of the robots and then computation of the shortest path using Dijkstra's shortest path algorithm. We propose MT*, an algorithm that reduces the computation burden for generating such plans for multi-robot systems significantly. Our approach generates a reduced version of the product graph without computing the complete joint transition system, which is computationally expensive. It then divides the complete mission specification among the participating robots and generates the trajectories for the individual robots independently. Our approach demonstrates substantial speedup in terms of computation time over the state-of-the-art approach, and unlike the state of the art approach, scales well with both the number of robots and the size of the workspace