 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrugal Actor-Critic: Sample Efficient Off-Policy Deep Reinforcement Learning Using Unique Experiences
Feb 05, 2024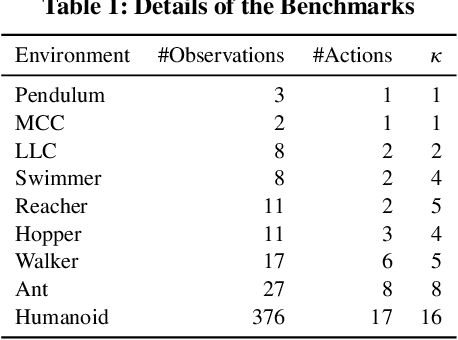
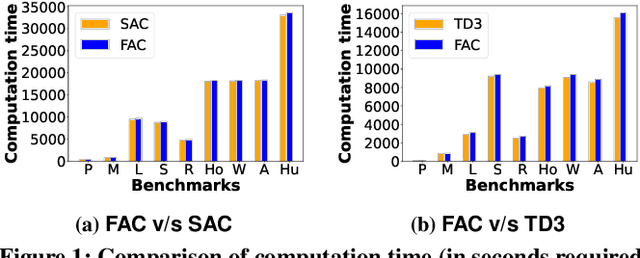
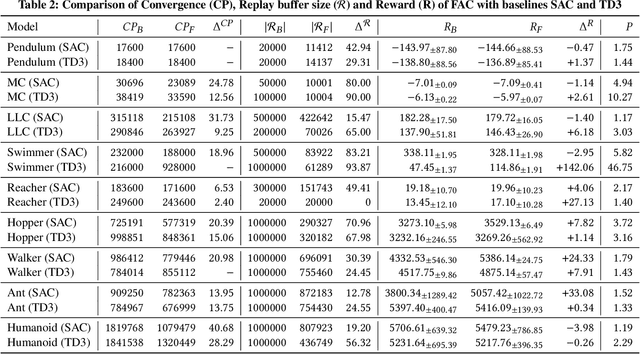
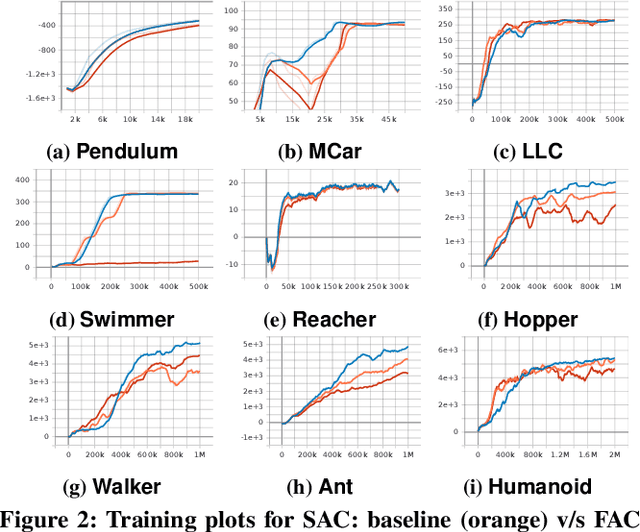
Efficient utilization of the replay buffer plays a significant role in the off-policy actor-critic reinforcement learning (RL) algorithms used for model-free control policy synthesis for complex dynamical systems. We propose a method for achieving sample efficiency, which focuses on selecting unique samples and adding them to the replay buffer during the exploration with the goal of reducing the buffer size and maintaining the independent and identically distributed (IID) nature of the samples. Our method is based on selecting an important subset of the set of state variables from the experiences encountered during the initial phase of random exploration, partitioning the state space into a set of abstract states based on the selected important state variables, and finally selecting the experiences with unique state-reward combination by using a kernel density estimator. We formally prove that the off-policy actor-critic algorithm incorporating the proposed method for unique experience accumulation converges faster than the vanilla off-policy actor-critic algorithm. Furthermore, we evaluate our method by comparing it with two state-of-the-art actor-critic RL algorithms on several continuous control benchmarks available in the Gym environment. Experimental results demonstrate that our method achieves a significant reduction in the size of the replay buffer for all the benchmarks while achieving either faster convergent or better reward accumulation compared to the baseline algorithms.
STL-Based Synthesis of Feedback Controllers Using Reinforcement Learning
Dec 02, 2022

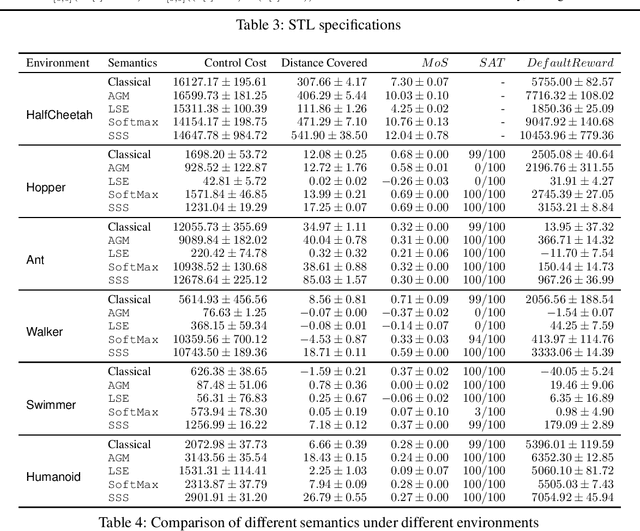
Deep Reinforcement Learning (DRL) has the potential to be used for synthesizing feedback controllers (agents) for various complex systems with unknown dynamics. These systems are expected to satisfy diverse safety and liveness properties best captured using temporal logic. In RL, the reward function plays a crucial role in specifying the desired behaviour of these agents. However, the problem of designing the reward function for an RL agent to satisfy complex temporal logic specifications has received limited attention in the literature. To address this, we provide a systematic way of generating rewards in real-time by using the quantitative semantics of Signal Temporal Logic (STL), a widely used temporal logic to specify the behaviour of cyber-physical systems. We propose a new quantitative semantics for STL having several desirable properties, making it suitable for reward generation. We evaluate our STL-based reinforcement learning mechanism on several complex continuous control benchmarks and compare our STL semantics with those available in the literature in terms of their efficacy in synthesizing the controller agent. Experimental results establish our new semantics to be the most suitable for synthesizing feedback controllers for complex continuous dynamical systems through reinforcement learning.