 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpatio-Temporal Forecasting of PM2.5 via Spatial-Diffusion guided Encoder-Decoder Architecture
Dec 18, 2024



In many problem settings that require spatio-temporal forecasting, the values in the time-series not only exhibit spatio-temporal correlations but are also influenced by spatial diffusion across locations. One such example is forecasting the concentration of fine particulate matter (PM2.5) in the atmosphere which is influenced by many complex factors, the most important ones being diffusion due to meteorological factors as well as transport across vast distances over a period of time. We present a novel Spatio-Temporal Graph Neural Network architecture, that specifically captures these dependencies to forecast the PM2.5 concentration. Our model is based on an encoder-decoder architecture where the encoder and decoder parts leverage gated recurrent units (GRU) augmented with a graph neural network (TransformerConv) to account for spatial diffusion. Our model can also be seen as a generalization of various existing models for time-series or spatio-temporal forecasting. We demonstrate the model's effectiveness on two real-world PM2.5 datasets: (1) data collected by us using a recently deployed network of low-cost PM$_{2.5}$ sensors from 511 locations spanning the entirety of the Indian state of Bihar over a period of one year, and (2) another publicly available dataset that covers severely polluted regions from China for a period of 4 years. Our experimental results show our model's impressive ability to account for both spatial as well as temporal dependencies precisely.
Federated Learning with Uncertainty and Personalization via Efficient Second-order Optimization
Nov 27, 2024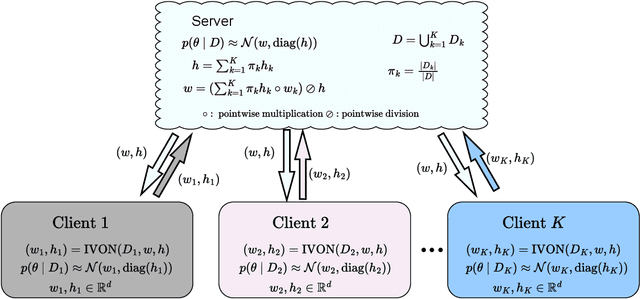
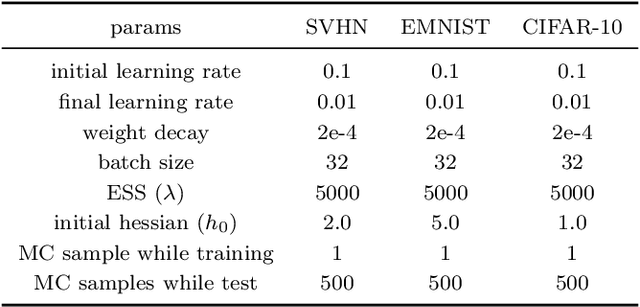


Federated Learning (FL) has emerged as a promising method to collaboratively learn from decentralized and heterogeneous data available at different clients without the requirement of data ever leaving the clients. Recent works on FL have advocated taking a Bayesian approach to FL as it offers a principled way to account for the model and predictive uncertainty by learning a posterior distribution for the client and/or server models. Moreover, Bayesian FL also naturally enables personalization in FL to handle data heterogeneity across the different clients by having each client learn its own distinct personalized model. In particular, the hierarchical Bayesian approach enables all the clients to learn their personalized models while also taking into account the commonalities via a prior distribution provided by the server. However, despite their promise, Bayesian approaches for FL can be computationally expensive and can have high communication costs as well because of the requirement of computing and sending the posterior distributions. We present a novel Bayesian FL method using an efficient second-order optimization approach, with a computational cost that is similar to first-order optimization methods like Adam, but also provides the various benefits of the Bayesian approach for FL (e.g., uncertainty, personalization), while also being significantly more efficient and accurate than SOTA Bayesian FL methods (both for standard as well as personalized FL settings). Our method achieves improved predictive accuracies as well as better uncertainty estimates as compared to the baselines which include both optimization based as well as Bayesian FL methods.
RISSOLE: Parameter-efficient Diffusion Models via Block-wise Generation and Retrieval-Guidance
Sep 02, 2024



Diffusion-based models demonstrate impressive generation capabilities. However, they also have a massive number of parameters, resulting in enormous model sizes, thus making them unsuitable for deployment on resource-constraint devices. Block-wise generation can be a promising alternative for designing compact-sized (parameter-efficient) deep generative models since the model can generate one block at a time instead of generating the whole image at once. However, block-wise generation is also considerably challenging because ensuring coherence across generated blocks can be non-trivial. To this end, we design a retrieval-augmented generation (RAG) approach and leverage the corresponding blocks of the images retrieved by the RAG module to condition the training and generation stages of a block-wise denoising diffusion model. Our conditioning schemes ensure coherence across the different blocks during training and, consequently, during generation. While we showcase our approach using the latent diffusion model (LDM) as the base model, it can be used with other variants of denoising diffusion models. We validate the solution of the coherence problem through the proposed approach by reporting substantive experiments to demonstrate our approach's effectiveness in compact model size and excellent generation quality.
Robust Black-box Testing of Deep Neural Networks using Co-Domain Coverage
Aug 13, 2024Rigorous testing of machine learning models is necessary for trustworthy deployments. We present a novel black-box approach for generating test-suites for robust testing of deep neural networks (DNNs). Most existing methods create test inputs based on maximizing some "coverage" criterion/metric such as a fraction of neurons activated by the test inputs. Such approaches, however, can only analyze each neuron's behavior or each layer's output in isolation and are unable to capture their collective effect on the DNN's output, resulting in test suites that often do not capture the various failure modes of the DNN adequately. These approaches also require white-box access, i.e., access to the DNN's internals (node activations). We present a novel black-box coverage criterion called Co-Domain Coverage (CDC), which is defined as a function of the model's output and thus takes into account its end-to-end behavior. Subsequently, we develop a new fuzz testing procedure named CoDoFuzz, which uses CDC to guide the fuzzing process to generate a test suite for a DNN. We extensively compare the test suite generated by CoDoFuzz with those generated using several state-of-the-art coverage-based fuzz testing methods for the DNNs trained on six publicly available datasets. Experimental results establish the efficiency and efficacy of CoDoFuzz in generating the largest number of misclassified inputs and the inputs for which the model lacks confidence in its decision.
VERSE: Virtual-Gradient Aware Streaming Lifelong Learning with Anytime Inference
Sep 15, 2023
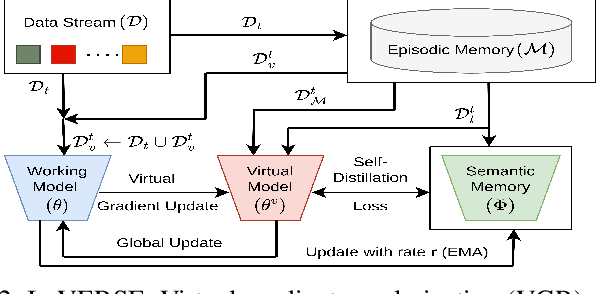
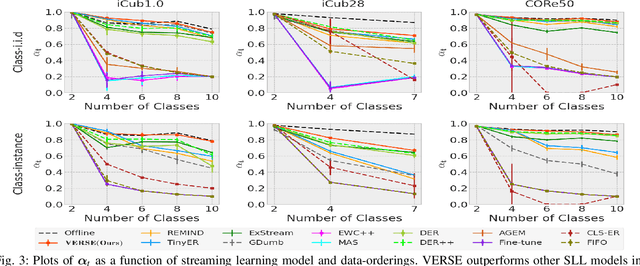
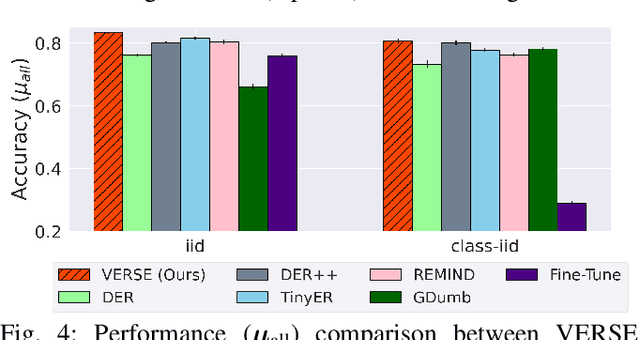
Lifelong learning, also referred to as continual learning, is the problem of training an AI agent continuously while also preventing it from forgetting its previously acquired knowledge. Most of the existing methods primarily focus on lifelong learning within a static environment and lack the ability to mitigate forgetting in a quickly-changing dynamic environment. Streaming lifelong learning is a challenging setting of lifelong learning with the goal of continuous learning in a dynamic non-stationary environment without forgetting. We introduce a novel approach to lifelong learning, which is streaming, requires a single pass over the data, can learn in a class-incremental manner, and can be evaluated on-the-fly (anytime inference). To accomplish these, we propose virtual gradients for continual representation learning to prevent catastrophic forgetting and leverage an exponential-moving-average-based semantic memory to further enhance performance. Extensive experiments on diverse datasets demonstrate our method's efficacy and superior performance over existing methods.
A Probabilistic Framework for Lifelong Test-Time Adaptation
Dec 19, 2022



Test-time adaptation is the problem of adapting a source pre-trained model using test inputs from a target domain without access to source domain data. Most of the existing approaches address the setting in which the target domain is stationary. Moreover, these approaches are prone to making erroneous predictions with unreliable uncertainty estimates when distribution shifts occur. Hence, test-time adaptation in the face of non-stationary target domain shift becomes a problem of significant interest. To address these issues, we propose a principled approach, PETAL (Probabilistic lifElong Test-time Adaptation with seLf-training prior), which looks into this problem from a probabilistic perspective using a partly data-dependent prior. A student-teacher framework, where the teacher model is an exponential moving average of the student model naturally emerges from this probabilistic perspective. In addition, the knowledge from the posterior distribution obtained for the source task acts as a regularizer. To handle catastrophic forgetting in the long term, we also propose a data-driven model parameter resetting mechanism based on the Fisher information matrix (FIM). Moreover, improvements in experimental results suggest that FIM based data-driven parameter restoration contributes to reducing the error accumulation and maintaining the knowledge of recent domain by restoring only the irrelevant parameters. In terms of predictive error rate as well as uncertainty based metrics such as Brier score and negative log-likelihood, our method achieves better results than the current state-of-the-art for online lifelong test time adaptation across various benchmarks, such as CIFAR-10C, CIFAR-100C, ImageNetC, and ImageNet3DCC datasets.
Novel Class Discovery without Forgetting
Jul 21, 2022

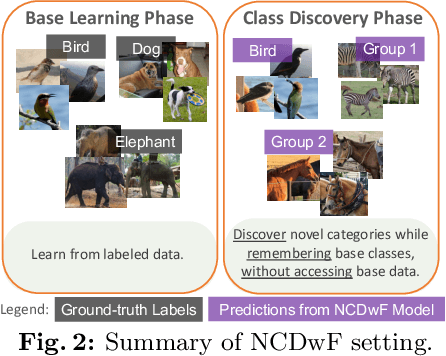
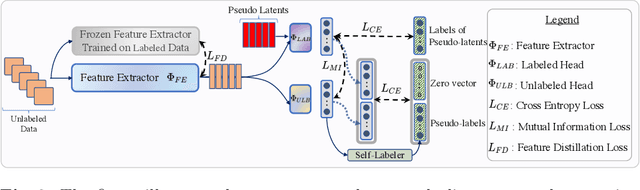
Humans possess an innate ability to identify and differentiate instances that they are not familiar with, by leveraging and adapting the knowledge that they have acquired so far. Importantly, they achieve this without deteriorating the performance on their earlier learning. Inspired by this, we identify and formulate a new, pragmatic problem setting of NCDwF: Novel Class Discovery without Forgetting, which tasks a machine learning model to incrementally discover novel categories of instances from unlabeled data, while maintaining its performance on the previously seen categories. We propose 1) a method to generate pseudo-latent representations which act as a proxy for (no longer available) labeled data, thereby alleviating forgetting, 2) a mutual-information based regularizer which enhances unsupervised discovery of novel classes, and 3) a simple Known Class Identifier which aids generalized inference when the testing data contains instances form both seen and unseen categories. We introduce experimental protocols based on CIFAR-10, CIFAR-100 and ImageNet-1000 to measure the trade-off between knowledge retention and novel class discovery. Our extensive evaluations reveal that existing models catastrophically forget previously seen categories while identifying novel categories, while our method is able to effectively balance between the competing objectives. We hope our work will attract further research into this newly identified pragmatic problem setting.
Bayesian Federated Learning via Predictive Distribution Distillation
Jun 15, 2022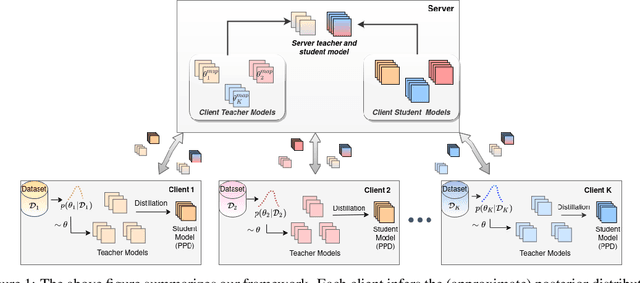
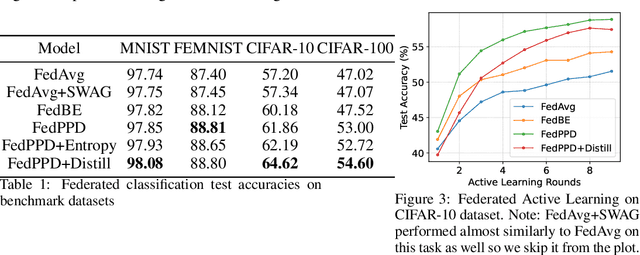
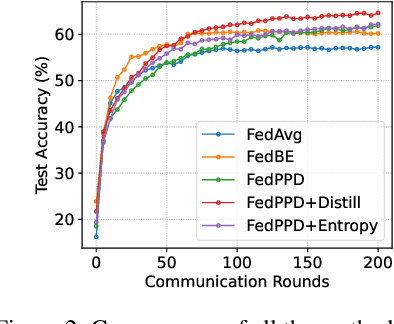
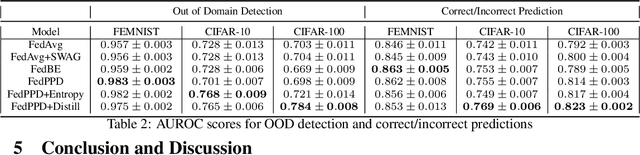
For most existing federated learning algorithms, each round consists of minimizing a loss function at each client to learn an optimal model at the client, followed by aggregating these client models at the server. Point estimation of the model parameters at the clients does not take into account the uncertainty in the models estimated at each client. In many situations, however, especially in limited data settings, it is beneficial to take into account the uncertainty in the client models for more accurate and robust predictions. Uncertainty also provides useful information for other important tasks, such as active learning and out-of-distribution (OOD) detection. We present a framework for Bayesian federated learning where each client infers the posterior predictive distribution using its training data and present various ways to aggregate these client-specific predictive distributions at the server. Since communicating and aggregating predictive distributions can be challenging and expensive, our approach is based on distilling each client's predictive distribution into a single deep neural network. This enables us to leverage advances in standard federated learning to Bayesian federated learning as well. Unlike some recent works that have tried to estimate model uncertainty of each client, our work also does not make any restrictive assumptions, such as the form of the client's posterior distribution. We evaluate our approach on classification in federated setting, as well as active learning and OOD detection in federated settings, on which our approach outperforms various existing federated learning baselines.
Spacing Loss for Discovering Novel Categories
Apr 22, 2022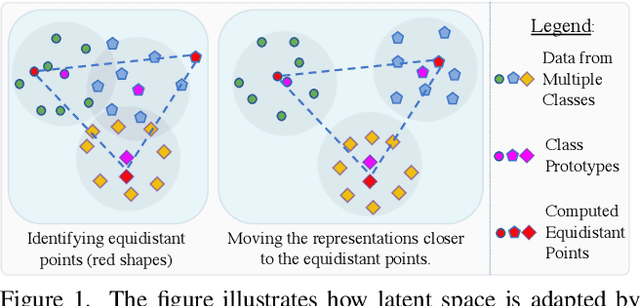
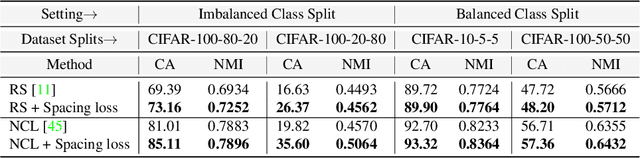
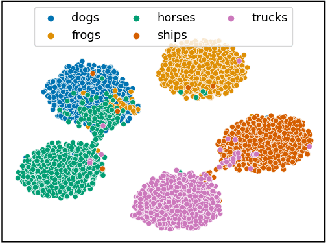
Novel Class Discovery (NCD) is a learning paradigm, where a machine learning model is tasked to semantically group instances from unlabeled data, by utilizing labeled instances from a disjoint set of classes. In this work, we first characterize existing NCD approaches into single-stage and two-stage methods based on whether they require access to labeled and unlabeled data together while discovering new classes. Next, we devise a simple yet powerful loss function that enforces separability in the latent space using cues from multi-dimensional scaling, which we refer to as Spacing Loss. Our proposed formulation can either operate as a standalone method or can be plugged into existing methods to enhance them. We validate the efficacy of Spacing Loss with thorough experimental evaluation across multiple settings on CIFAR-10 and CIFAR-100 datasets.
Semi-Supervised Super-Resolution
Apr 19, 2022
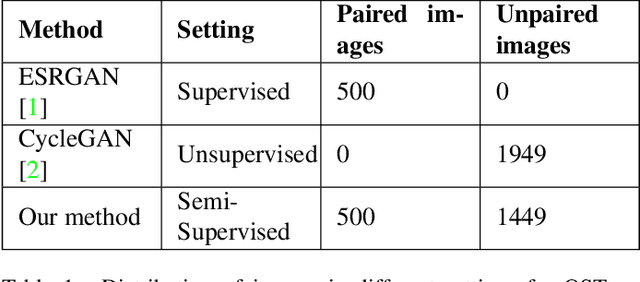
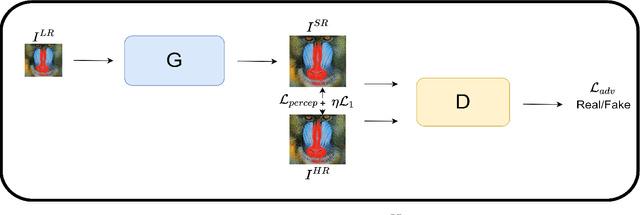
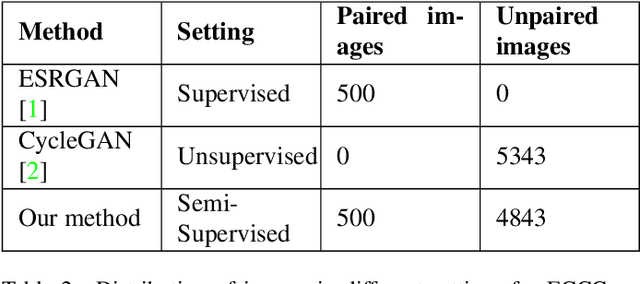
Super-Resolution is the technique to improve the quality of a low-resolution photo by boosting its plausible resolution. The computer vision community has extensively explored the area of Super-Resolution. However, previous Super-Resolution methods require vast amounts of data for training which becomes problematic in domains where very few low-resolution, high-resolution pairs might be available. One such area is statistical downscaling, where super-resolution is increasingly being used to obtain high-resolution climate information from low-resolution data. Acquiring high-resolution climate data is extremely expensive and challenging. To reduce the cost of generating high-resolution climate information, Super-Resolution algorithms should be able to train with a limited number of low-resolution, high-resolution pairs. This paper tries to solve the aforementioned problem by introducing a semi-supervised way to perform super-resolution that can generate sharp, high-resolution images with as few as 500 paired examples. The proposed semi-supervised technique can be used as a plug-and-play module with any supervised GAN-based Super-Resolution method to enhance its performance. We quantitatively and qualitatively analyze the performance of the proposed model and compare it with completely supervised methods as well as other unsupervised techniques. Comprehensive evaluations show the superiority of our method over other methods on different metrics. We also offer the applicability of our approach in statistical downscaling to obtain high-resolution climate images.