 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePALoRA: Projection-Adaptive LoRA for Preserving Reasoning in Large Language Models
May 23, 2026Efficiently updating Large Language Models (LLMs) with new or evolving factual knowledge remains a central challenge, as even parameter-efficient adaptation can erode previously acquired reasoning abilities. This tension reflects a plasticity-stability dilemma: models must incorporate new knowledge while preserving skill-critical representations. In this work, we study this trade-off through the spectral structure of multilayer perceptron weight matrices. We show, both theoretically and empirically, that information essential for reasoning is not localized only in dominant singular directions, but is instead distributed across the singular spectrum. Motivated by this observation, we introduce PALoRA, a two-stage framework for knowledge injection with reduced interference. PALoRA first trains a Singular Value Fine-Tuning (SVF) expert on a reasoning dataset and uses its learned singular scaling vector as a frozen geometric probe to identify components that are critical for the target skill. It then performs factual knowledge injection with Low-Rank Adaptation (LoRA) under a structural orthogonality constraint, ensuring that updates avoid the identified skill-relevant subspace. Across Llama 3.1 8B and Mistral 7B, and across mathematical, coding, and scientific reasoning benchmarks, PALoRA preserves on average 95% of the SVF expert's reasoning performance while maintaining competitive factual recall. It consistently improves skill retention over prior spectral Parameter-Efficient Fine-Tuning (PEFT) methods while adding less than 0.006% parameter overhead.
Evaluating Query Efficiency and Accuracy of Transfer Learning-based Model Extraction Attack in Federated Learning
May 25, 2025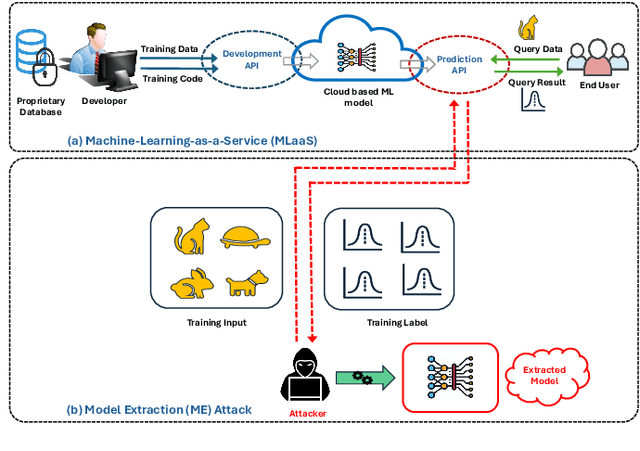
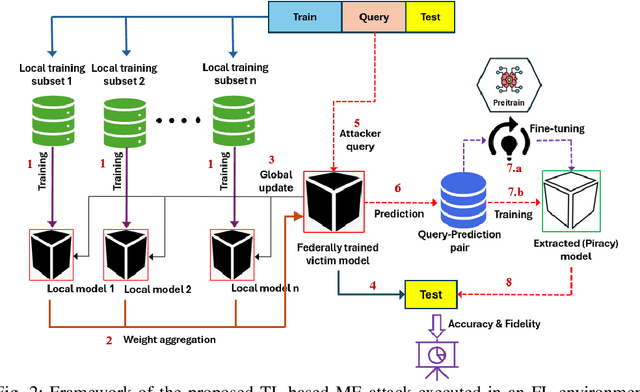
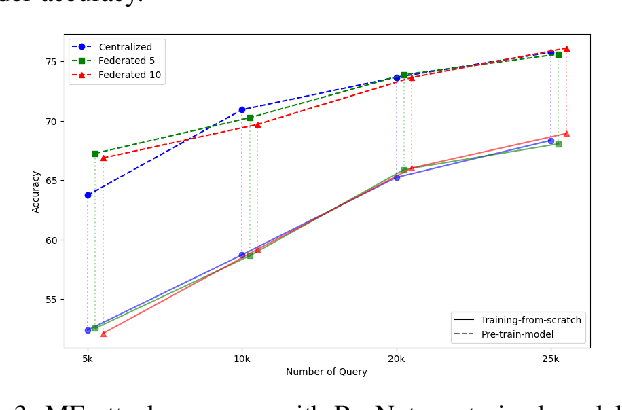
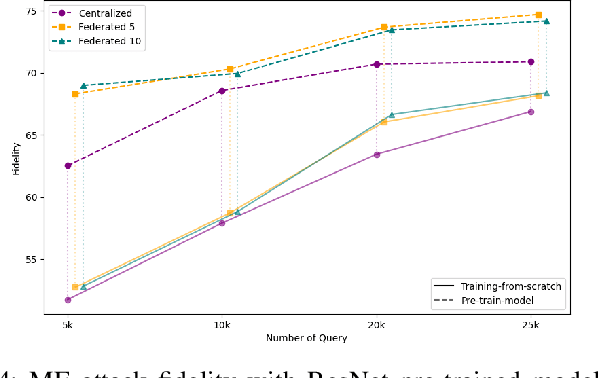
Federated Learning (FL) is a collaborative learning framework designed to protect client data, yet it remains highly vulnerable to Intellectual Property (IP) threats. Model extraction (ME) attacks pose a significant risk to Machine Learning as a Service (MLaaS) platforms, enabling attackers to replicate confidential models by querying black-box (without internal insight) APIs. Despite FL's privacy-preserving goals, its distributed nature makes it particularly susceptible to such attacks. This paper examines the vulnerability of FL-based victim models to two types of model extraction attacks. For various federated clients built under the NVFlare platform, we implemented ME attacks across two deep learning architectures and three image datasets. We evaluate the proposed ME attack performance using various metrics, including accuracy, fidelity, and KL divergence. The experiments show that for different FL clients, the accuracy and fidelity of the extracted model are closely related to the size of the attack query set. Additionally, we explore a transfer learning based approach where pretrained models serve as the starting point for the extraction process. The results indicate that the accuracy and fidelity of the fine-tuned pretrained extraction models are notably higher, particularly with smaller query sets, highlighting potential advantages for attackers.
Proceedings of 1st Workshop on Advancing Artificial Intelligence through Theory of Mind
Apr 28, 2025



This volume includes a selection of papers presented at the Workshop on Advancing Artificial Intelligence through Theory of Mind held at AAAI 2025 in Philadelphia US on 3rd March 2025. The purpose of this volume is to provide an open access and curated anthology for the ToM and AI research community.
ADROIT: A Self-Supervised Framework for Learning Robust Representations for Active Learning
Mar 10, 2025



Active learning aims to select optimal samples for labeling, minimizing annotation costs. This paper introduces a unified representation learning framework tailored for active learning with task awareness. It integrates diverse sources, comprising reconstruction, adversarial, self-supervised, knowledge-distillation, and classification losses into a unified VAE-based ADROIT approach. The proposed approach comprises three key components - a unified representation generator (VAE), a state discriminator, and a (proxy) task-learner or classifier. ADROIT learns a latent code using both labeled and unlabeled data, incorporating task-awareness by leveraging labeled data with the proxy classifier. Unlike previous approaches, the proxy classifier additionally employs a self-supervised loss on unlabeled data and utilizes knowledge distillation to align with the target task-learner. The state discriminator distinguishes between labeled and unlabeled data, facilitating the selection of informative unlabeled samples. The dynamic interaction between VAE and the state discriminator creates a competitive environment, with the VAE attempting to deceive the discriminator, while the state discriminator learns to differentiate between labeled and unlabeled inputs. Extensive evaluations on diverse datasets and ablation analysis affirm the effectiveness of the proposed model.
Decentralised Resource Sharing in TinyML: Wireless Bilayer Gossip Parallel SGD for Collaborative Learning
Jan 08, 2025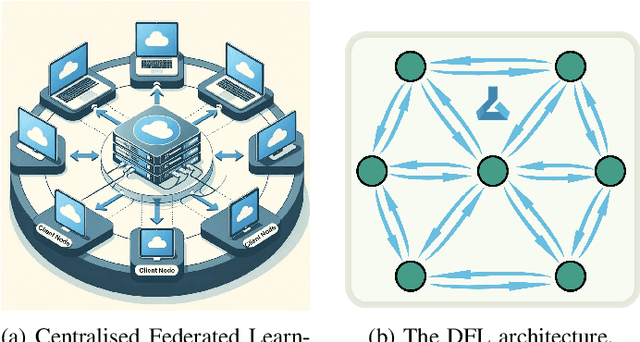
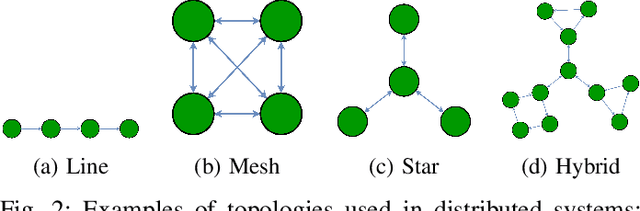
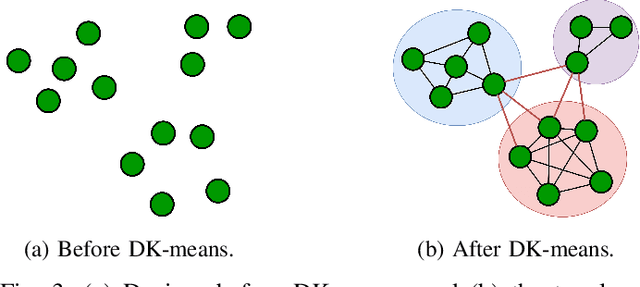
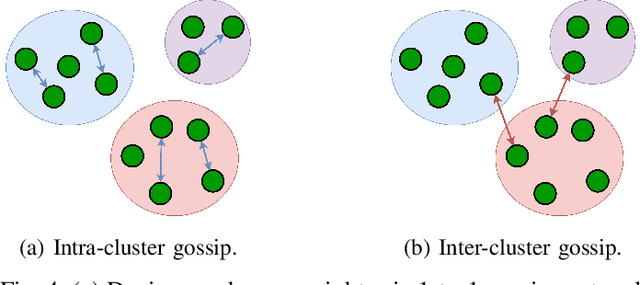
With the growing computational capabilities of microcontroller units (MCUs), edge devices can now support machine learning models. However, deploying decentralised federated learning (DFL) on such devices presents key challenges, including intermittent connectivity, limited communication range, and dynamic network topologies. This paper proposes a novel framework, bilayer Gossip Decentralised Parallel Stochastic Gradient Descent (GD PSGD), designed to address these issues in resource-constrained environments. The framework incorporates a hierarchical communication structure using Distributed Kmeans (DKmeans) clustering for geographic grouping and a gossip protocol for efficient model aggregation across two layers: intra-cluster and inter-cluster. We evaluate the framework's performance against the Centralised Federated Learning (CFL) baseline using the MCUNet model on the CIFAR-10 dataset under IID and Non-IID conditions. Results demonstrate that the proposed method achieves comparable accuracy to CFL on IID datasets, requiring only 1.8 additional rounds for convergence. On Non-IID datasets, the accuracy loss remains under 8\% for moderate data imbalance. These findings highlight the framework's potential to support scalable and privacy-preserving learning on edge devices with minimal performance trade-offs.
Privacy Drift: Evolving Privacy Concerns in Incremental Learning
Dec 06, 2024In the evolving landscape of machine learning (ML), Federated Learning (FL) presents a paradigm shift towards decentralized model training while preserving user data privacy. This paper introduces the concept of ``privacy drift", an innovative framework that parallels the well-known phenomenon of concept drift. While concept drift addresses the variability in model accuracy over time due to changes in the data, privacy drift encapsulates the variation in the leakage of private information as models undergo incremental training. By defining and examining privacy drift, this study aims to unveil the nuanced relationship between the evolution of model performance and the integrity of data privacy. Through rigorous experimentation, we investigate the dynamics of privacy drift in FL systems, focusing on how model updates and data distribution shifts influence the susceptibility of models to privacy attacks, such as membership inference attacks (MIA). Our results highlight a complex interplay between model accuracy and privacy safeguards, revealing that enhancements in model performance can lead to increased privacy risks. We provide empirical evidence from experiments on customized datasets derived from CIFAR-100 (Canadian Institute for Advanced Research, 100 classes), showcasing the impact of data and concept drift on privacy. This work lays the groundwork for future research on privacy-aware machine learning, aiming to achieve a delicate balance between model accuracy and data privacy in decentralized environments.
On the Ethical Considerations of Generative Agents
Nov 28, 2024The Generative Agents framework recently developed by Park et al. has enabled numerous new technical solutions and problem-solving approaches. Academic and industrial interest in generative agents has been explosive as a result of the effectiveness of generative agents toward emulating human behaviour. However, it is necessary to consider the ethical challenges and concerns posed by this technique and its usage. In this position paper, we discuss the extant literature that evaluate the ethical considerations regarding generative agents and similar generative tools, and identify additional concerns of significant importance. We also suggest guidelines and necessary future research on how to mitigate some of the ethical issues and systemic risks associated with generative agents.
RISSOLE: Parameter-efficient Diffusion Models via Block-wise Generation and Retrieval-Guidance
Sep 02, 2024



Diffusion-based models demonstrate impressive generation capabilities. However, they also have a massive number of parameters, resulting in enormous model sizes, thus making them unsuitable for deployment on resource-constraint devices. Block-wise generation can be a promising alternative for designing compact-sized (parameter-efficient) deep generative models since the model can generate one block at a time instead of generating the whole image at once. However, block-wise generation is also considerably challenging because ensuring coherence across generated blocks can be non-trivial. To this end, we design a retrieval-augmented generation (RAG) approach and leverage the corresponding blocks of the images retrieved by the RAG module to condition the training and generation stages of a block-wise denoising diffusion model. Our conditioning schemes ensure coherence across the different blocks during training and, consequently, during generation. While we showcase our approach using the latent diffusion model (LDM) as the base model, it can be used with other variants of denoising diffusion models. We validate the solution of the coherence problem through the proposed approach by reporting substantive experiments to demonstrate our approach's effectiveness in compact model size and excellent generation quality.
Accuracy-Privacy Trade-off in the Mitigation of Membership Inference Attack in Federated Learning
Jul 26, 2024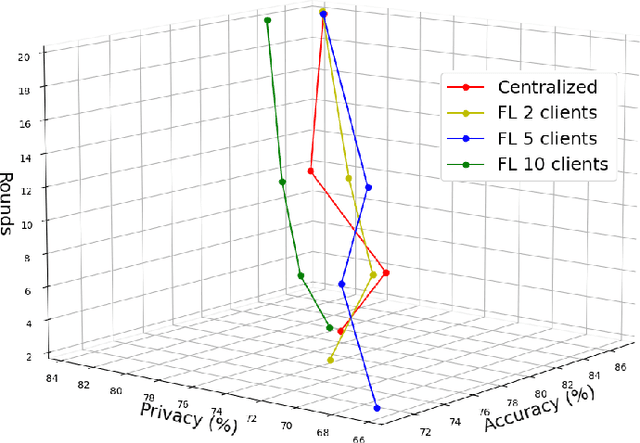
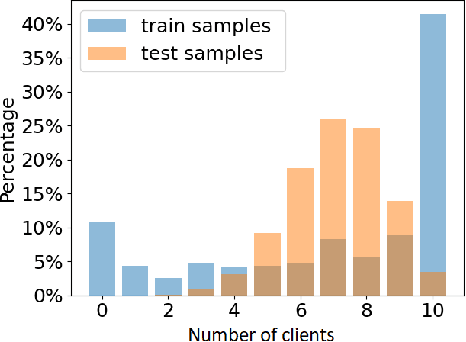
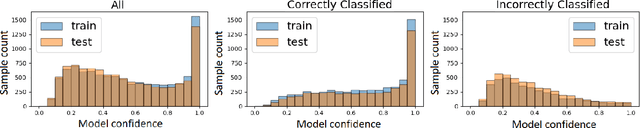
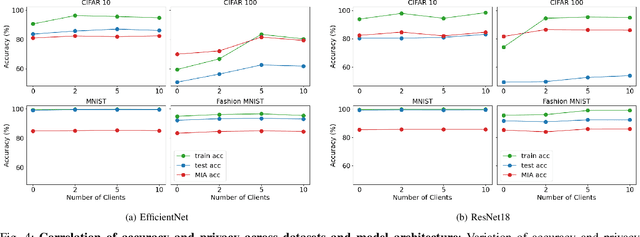
Over the last few years, federated learning (FL) has emerged as a prominent method in machine learning, emphasizing privacy preservation by allowing multiple clients to collaboratively build a model while keeping their training data private. Despite this focus on privacy, FL models are susceptible to various attacks, including membership inference attacks (MIAs), posing a serious threat to data confidentiality. In a recent study, Rezaei \textit{et al.} revealed the existence of an accuracy-privacy trade-off in deep ensembles and proposed a few fusion strategies to overcome it. In this paper, we aim to explore the relationship between deep ensembles and FL. Specifically, we investigate whether confidence-based metrics derived from deep ensembles apply to FL and whether there is a trade-off between accuracy and privacy in FL with respect to MIA. Empirical investigations illustrate a lack of a non-monotonic correlation between the number of clients and the accuracy-privacy trade-off. By experimenting with different numbers of federated clients, datasets, and confidence-metric-based fusion strategies, we identify and analytically justify the clear existence of the accuracy-privacy trade-off.
Neural networks for abstraction and reasoning: Towards broad generalization in machines
Feb 05, 2024



For half a century, artificial intelligence research has attempted to reproduce the human qualities of abstraction and reasoning - creating computer systems that can learn new concepts from a minimal set of examples, in settings where humans find this easy. While specific neural networks are able to solve an impressive range of problems, broad generalisation to situations outside their training data has proved elusive.In this work, we look at several novel approaches for solving the Abstraction & Reasoning Corpus (ARC), a dataset of abstract visual reasoning tasks introduced to test algorithms on broad generalization. Despite three international competitions with $100,000 in prizes, the best algorithms still fail to solve a majority of ARC tasks and rely on complex hand-crafted rules, without using machine learning at all. We revisit whether recent advances in neural networks allow progress on this task. First, we adapt the DreamCoder neurosymbolic reasoning solver to ARC. DreamCoder automatically writes programs in a bespoke domain-specific language to perform reasoning, using a neural network to mimic human intuition. We present the Perceptual Abstraction and Reasoning Language (PeARL) language, which allows DreamCoder to solve ARC tasks, and propose a new recognition model that allows us to significantly improve on the previous best implementation.We also propose a new encoding and augmentation scheme that allows large language models (LLMs) to solve ARC tasks, and find that the largest models can solve some ARC tasks. LLMs are able to solve a different group of problems to state-of-the-art solvers, and provide an interesting way to complement other approaches. We perform an ensemble analysis, combining models to achieve better results than any system alone. Finally, we publish the arckit Python library to make future research on ARC easier.