 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDecentralised Resource Sharing in TinyML: Wireless Bilayer Gossip Parallel SGD for Collaborative Learning
Jan 08, 2025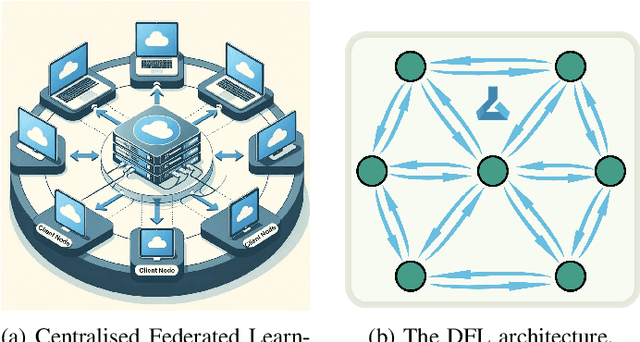
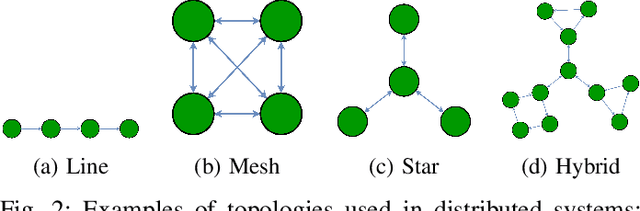
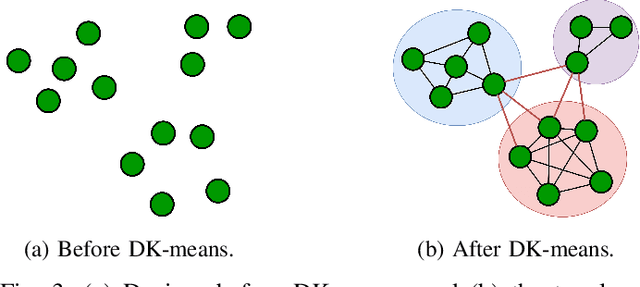
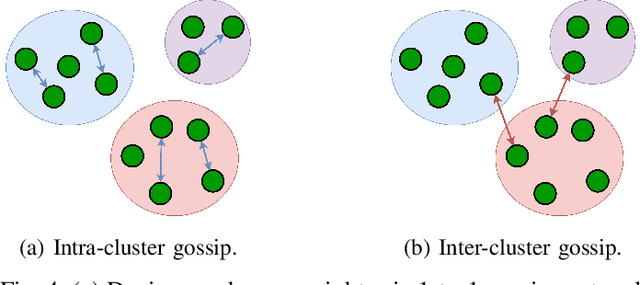
With the growing computational capabilities of microcontroller units (MCUs), edge devices can now support machine learning models. However, deploying decentralised federated learning (DFL) on such devices presents key challenges, including intermittent connectivity, limited communication range, and dynamic network topologies. This paper proposes a novel framework, bilayer Gossip Decentralised Parallel Stochastic Gradient Descent (GD PSGD), designed to address these issues in resource-constrained environments. The framework incorporates a hierarchical communication structure using Distributed Kmeans (DKmeans) clustering for geographic grouping and a gossip protocol for efficient model aggregation across two layers: intra-cluster and inter-cluster. We evaluate the framework's performance against the Centralised Federated Learning (CFL) baseline using the MCUNet model on the CIFAR-10 dataset under IID and Non-IID conditions. Results demonstrate that the proposed method achieves comparable accuracy to CFL on IID datasets, requiring only 1.8 additional rounds for convergence. On Non-IID datasets, the accuracy loss remains under 8\% for moderate data imbalance. These findings highlight the framework's potential to support scalable and privacy-preserving learning on edge devices with minimal performance trade-offs.
TinyM$^2$Net-V3: Memory-Aware Compressed Multimodal Deep Neural Networks for Sustainable Edge Deployment
May 20, 2024The advancement of sophisticated artificial intelligence (AI) algorithms has led to a notable increase in energy usage and carbon dioxide emissions, intensifying concerns about climate change. This growing problem has brought the environmental sustainability of AI technologies to the forefront, especially as they expand across various sectors. In response to these challenges, there is an urgent need for the development of sustainable AI solutions. These solutions must focus on energy-efficient embedded systems that are capable of handling diverse data types even in environments with limited resources, thereby ensuring both technological progress and environmental responsibility. Integrating complementary multimodal data into tiny machine learning models for edge devices is challenging due to increased complexity, latency, and power consumption. This work introduces TinyM$^2$Net-V3, a system that processes different modalities of complementary data, designs deep neural network (DNN) models, and employs model compression techniques including knowledge distillation and low bit-width quantization with memory-aware considerations to fit models within lower memory hierarchy levels, reducing latency and enhancing energy efficiency on resource-constrained devices. We evaluated TinyM$^2$Net-V3 in two multimodal case studies: COVID-19 detection using cough, speech, and breathing audios, and pose classification from depth and thermal images. With tiny inference models (6 KB and 58 KB), we achieved 92.95% and 90.7% accuracies, respectively. Our tiny machine learning models, deployed on resource limited hardware, demonstrated low latencies within milliseconds and very high power efficiency.
TinyVQA: Compact Multimodal Deep Neural Network for Visual Question Answering on Resource-Constrained Devices
Apr 04, 2024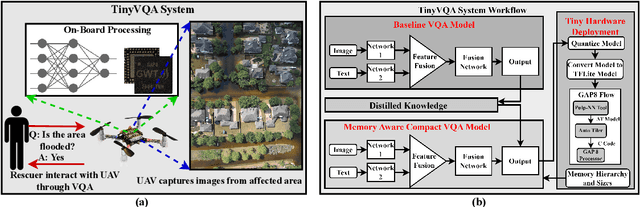
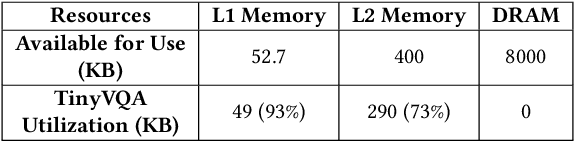
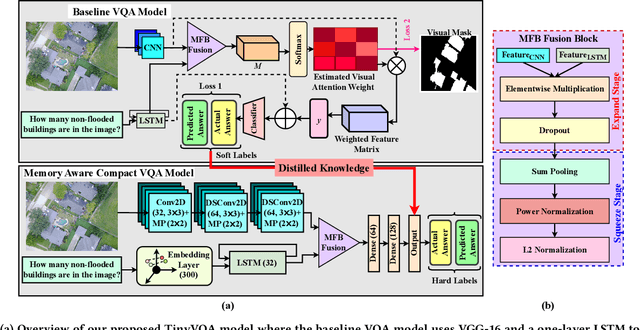
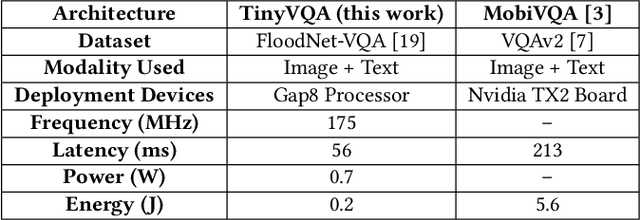
Traditional machine learning models often require powerful hardware, making them unsuitable for deployment on resource-limited devices. Tiny Machine Learning (tinyML) has emerged as a promising approach for running machine learning models on these devices, but integrating multiple data modalities into tinyML models still remains a challenge due to increased complexity, latency, and power consumption. This paper proposes TinyVQA, a novel multimodal deep neural network for visual question answering tasks that can be deployed on resource-constrained tinyML hardware. TinyVQA leverages a supervised attention-based model to learn how to answer questions about images using both vision and language modalities. Distilled knowledge from the supervised attention-based VQA model trains the memory aware compact TinyVQA model and low bit-width quantization technique is employed to further compress the model for deployment on tinyML devices. The TinyVQA model was evaluated on the FloodNet dataset, which is used for post-disaster damage assessment. The compact model achieved an accuracy of 79.5%, demonstrating the effectiveness of TinyVQA for real-world applications. Additionally, the model was deployed on a Crazyflie 2.0 drone, equipped with an AI deck and GAP8 microprocessor. The TinyVQA model achieved low latencies of 56 ms and consumes 693 mW power while deployed on the tiny drone, showcasing its suitability for resource-constrained embedded systems.
TinyM$^2$Net: A Flexible System Algorithm Co-designed Multimodal Learning Framework for Tiny Devices
Feb 09, 2022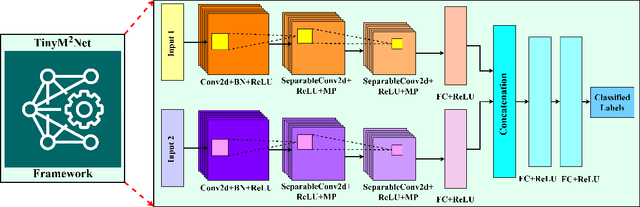


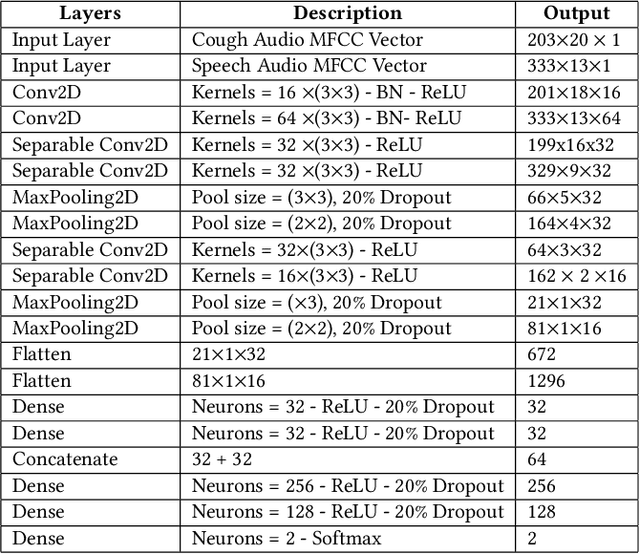
With the emergence of Artificial Intelligence (AI), new attention has been given to implement AI algorithms on resource constrained tiny devices to expand the application domain of IoT. Multimodal Learning has recently become very popular with the classification task due to its impressive performance for both image and audio event classification. This paper presents TinyM$^2$Net -- a flexible system algorithm co-designed multimodal learning framework for resource constrained tiny devices. The framework was designed to be evaluated on two different case-studies: COVID-19 detection from multimodal audio recordings and battle field object detection from multimodal images and audios. In order to compress the model to implement on tiny devices, substantial network architecture optimization and mixed precision quantization were performed (mixed 8-bit and 4-bit). TinyM$^2$Net shows that even a tiny multimodal learning model can improve the classification performance than that of any unimodal frameworks. The most compressed TinyM$^2$Net achieves 88.4% COVID-19 detection accuracy (14.5% improvement from unimodal base model) and 96.8\% battle field object detection accuracy (3.9% improvement from unimodal base model). Finally, we test our TinyM$^2$Net models on a Raspberry Pi 4 to see how they perform when deployed to a resource constrained tiny device.
Neural Networks for Pulmonary Disease Diagnosis using Auditory and Demographic Information
Nov 26, 2020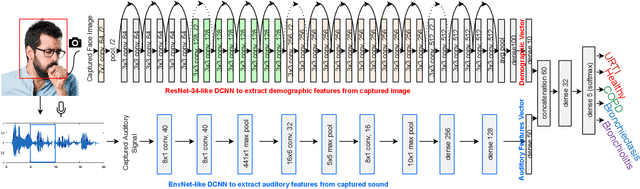
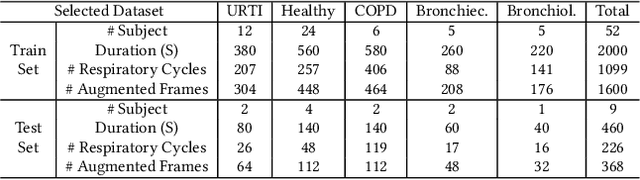


Pulmonary diseases impact millions of lives globally and annually. The recent outbreak of the pandemic of the COVID-19, a novel pulmonary infection, has more than ever brought the attention of the research community to the machine-aided diagnosis of respiratory problems. This paper is thus an effort to exploit machine learning for classification of respiratory problems and proposes a framework that employs as much correlated information (auditory and demographic information in this work) as a dataset provides to increase the sensitivity and specificity of a diagnosing system. First, we use deep convolutional neural networks (DCNNs) to process and classify a publicly released pulmonary auditory dataset, and then we take advantage of the existing demographic information within the dataset and show that the accuracy of the pulmonary classification increases by 5% when trained on the auditory information in conjunction with the demographic information. Since the demographic data can be extracted using computer vision, we suggest using another parallel DCNN to estimate the demographic information of the subject under test visioned by the processing computer. Lastly, as a proposition to bring the healthcare system to users' fingertips, we measure deployment characteristics of the auditory DCNN model onto processing components of an NVIDIA TX2 development board.