 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHilbert-Augmented Reinforcement Learning for Scalable Multi-Robot Coverage and Exploration
Feb 23, 2026We present a coverage framework that integrates Hilbert space-filling priors into decentralized multi-robot learning and execution. We augment DQN and PPO with Hilbert-based spatial indices to structure exploration and reduce redundancy in sparse-reward environments, and we evaluate scalability in multi-robot grid coverage. We further describe a waypoint interface that converts Hilbert orderings into curvature-bounded, time-parameterized SE(2) trajectories (planar (x, y, θ)), enabling onboard feasibility on resource-constrained robots. Experiments show improvements in coverage efficiency, redundancy, and convergence speed over DQN/PPO baselines. In addition, we validate the approach on a Boston Dynamics Spot legged robot, executing the generated trajectories in indoor environments and observing reliable coverage with low redundancy. These results indicate that geometric priors improve autonomy and scalability for swarm and legged robotics.
Integrating Frequency-Domain Representations with Low-Rank Adaptation in Vision-Language Models
Mar 08, 2025



Situational awareness applications rely heavily on real-time processing of visual and textual data to provide actionable insights. Vision language models (VLMs) have become essential tools for interpreting complex environments by connecting visual inputs with natural language descriptions. However, these models often face computational challenges, especially when required to perform efficiently in real environments. This research presents a novel vision language model (VLM) framework that leverages frequency domain transformations and low-rank adaptation (LoRA) to enhance feature extraction, scalability, and efficiency. Unlike traditional VLMs, which rely solely on spatial-domain representations, our approach incorporates Discrete Fourier Transform (DFT) based low-rank features while retaining pretrained spatial weights, enabling robust performance in noisy or low visibility scenarios. We evaluated the proposed model on caption generation and Visual Question Answering (VQA) tasks using benchmark datasets with varying levels of Gaussian noise. Quantitative results demonstrate that our model achieves evaluation metrics comparable to state-of-the-art VLMs, such as CLIP ViT-L/14 and SigLIP. Qualitative analysis further reveals that our model provides more detailed and contextually relevant responses, particularly for real-world images captured by a RealSense camera mounted on an Unmanned Ground Vehicle (UGV).
TinyVQA: Compact Multimodal Deep Neural Network for Visual Question Answering on Resource-Constrained Devices
Apr 04, 2024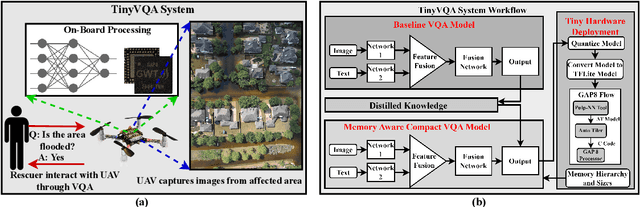
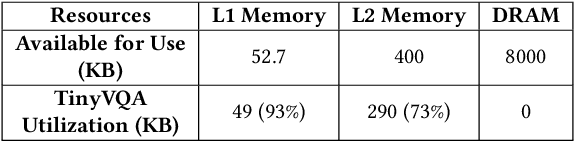
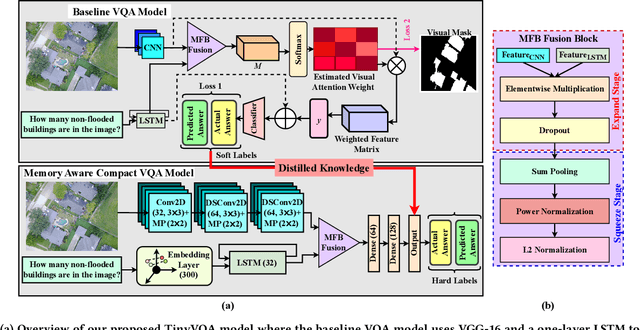
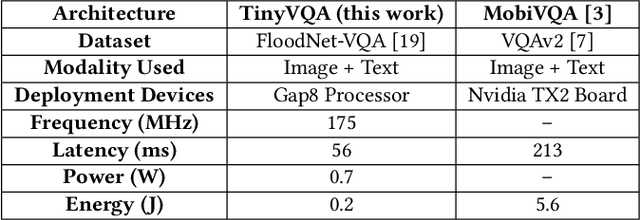
Traditional machine learning models often require powerful hardware, making them unsuitable for deployment on resource-limited devices. Tiny Machine Learning (tinyML) has emerged as a promising approach for running machine learning models on these devices, but integrating multiple data modalities into tinyML models still remains a challenge due to increased complexity, latency, and power consumption. This paper proposes TinyVQA, a novel multimodal deep neural network for visual question answering tasks that can be deployed on resource-constrained tinyML hardware. TinyVQA leverages a supervised attention-based model to learn how to answer questions about images using both vision and language modalities. Distilled knowledge from the supervised attention-based VQA model trains the memory aware compact TinyVQA model and low bit-width quantization technique is employed to further compress the model for deployment on tinyML devices. The TinyVQA model was evaluated on the FloodNet dataset, which is used for post-disaster damage assessment. The compact model achieved an accuracy of 79.5%, demonstrating the effectiveness of TinyVQA for real-world applications. Additionally, the model was deployed on a Crazyflie 2.0 drone, equipped with an AI deck and GAP8 microprocessor. The TinyVQA model achieved low latencies of 56 ms and consumes 693 mW power while deployed on the tiny drone, showcasing its suitability for resource-constrained embedded systems.
An Edge-Cloud Integrated Framework for Flexible and Dynamic Stream Analytics
May 11, 2022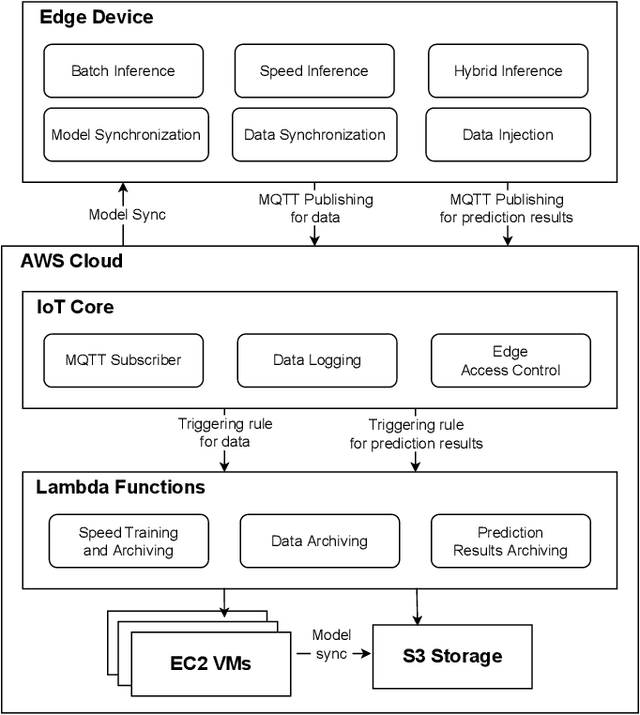
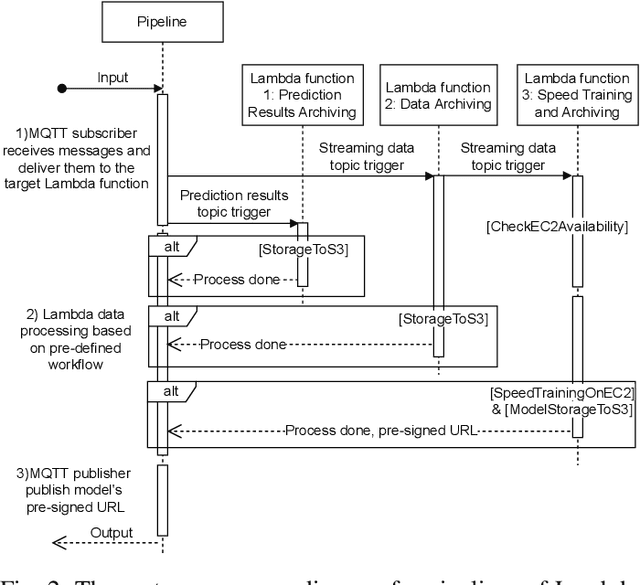
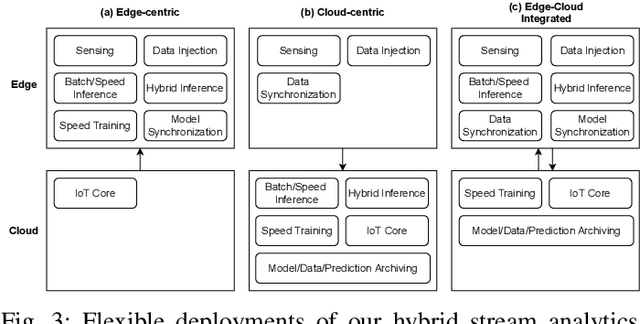
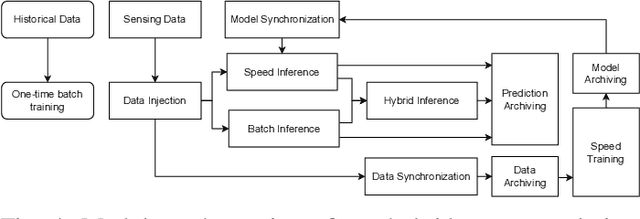
With the popularity of Internet of Things (IoT), edge computing and cloud computing, more and more stream analytics applications are being developed including real-time trend prediction and object detection on top of IoT sensing data. One popular type of stream analytics is the recurrent neural network (RNN) deep learning model based time series or sequence data prediction and forecasting. Different from traditional analytics that assumes data to be processed are available ahead of time and will not change, stream analytics deals with data that are being generated continuously and data trend/distribution could change (aka concept drift), which will cause prediction/forecasting accuracy to drop over time. One other challenge is to find the best resource provisioning for stream analytics to achieve good overall latency. In this paper, we study how to best leverage edge and cloud resources to achieve better accuracy and latency for RNN-based stream analytics. We propose a novel edge-cloud integrated framework for hybrid stream analytics that support low latency inference on the edge and high capacity training on the cloud. We study the flexible deployment of our hybrid learning framework, namely edge-centric, cloud-centric and edge-cloud integrated. Further, our hybrid learning framework can dynamically combine inference results from an RNN model pre-trained based on historical data and another RNN model re-trained periodically based on the most recent data. Using real-world and simulated stream datasets, our experiments show the proposed edge-cloud deployment is the best among all three deployment types in terms of latency. For accuracy, the experiments show our dynamic learning approach performs the best among all learning approaches for all three concept drift scenarios.
TinyM$^2$Net: A Flexible System Algorithm Co-designed Multimodal Learning Framework for Tiny Devices
Feb 09, 2022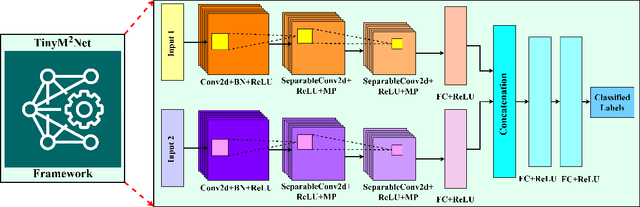


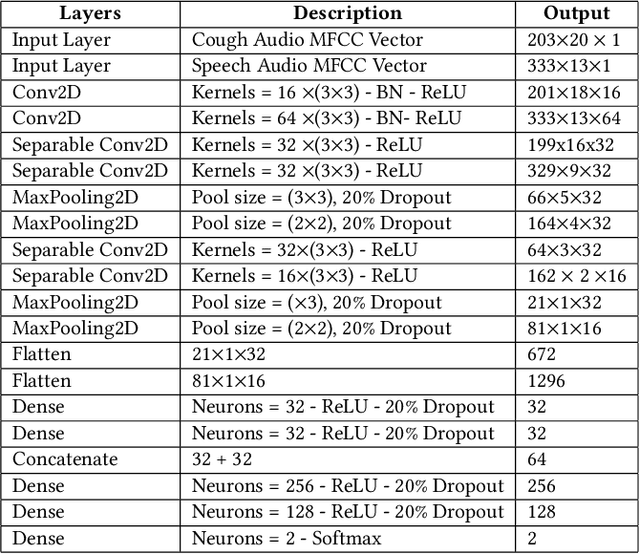
With the emergence of Artificial Intelligence (AI), new attention has been given to implement AI algorithms on resource constrained tiny devices to expand the application domain of IoT. Multimodal Learning has recently become very popular with the classification task due to its impressive performance for both image and audio event classification. This paper presents TinyM$^2$Net -- a flexible system algorithm co-designed multimodal learning framework for resource constrained tiny devices. The framework was designed to be evaluated on two different case-studies: COVID-19 detection from multimodal audio recordings and battle field object detection from multimodal images and audios. In order to compress the model to implement on tiny devices, substantial network architecture optimization and mixed precision quantization were performed (mixed 8-bit and 4-bit). TinyM$^2$Net shows that even a tiny multimodal learning model can improve the classification performance than that of any unimodal frameworks. The most compressed TinyM$^2$Net achieves 88.4% COVID-19 detection accuracy (14.5% improvement from unimodal base model) and 96.8\% battle field object detection accuracy (3.9% improvement from unimodal base model). Finally, we test our TinyM$^2$Net models on a Raspberry Pi 4 to see how they perform when deployed to a resource constrained tiny device.
Reproducible and Portable Big Data Analytics in the Cloud
Dec 17, 2021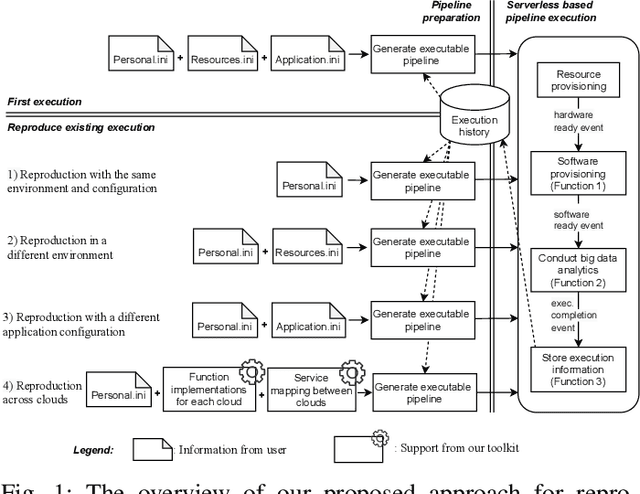
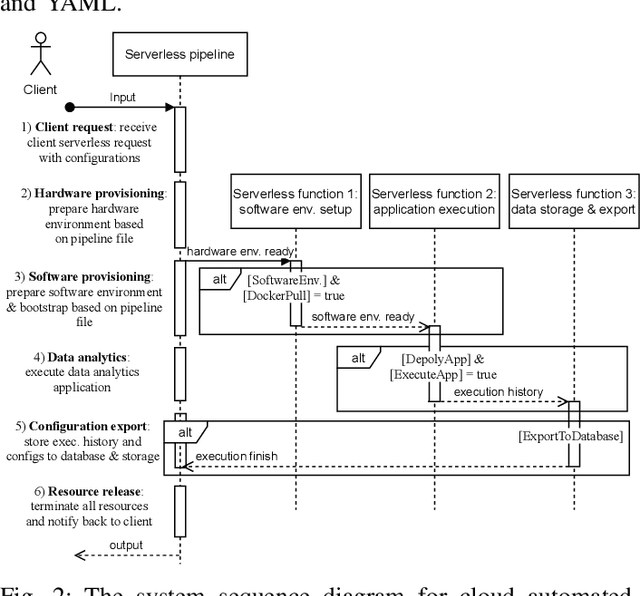
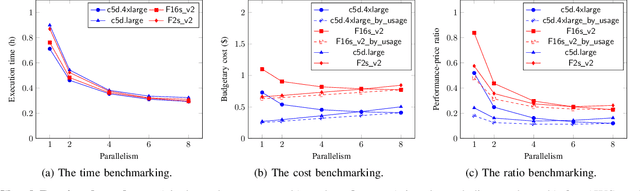
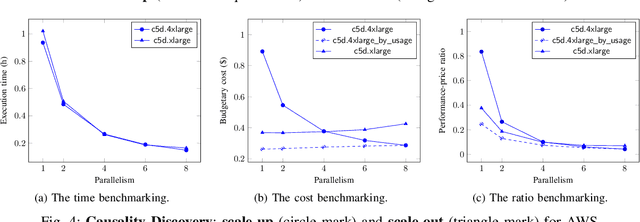
Cloud computing has become a major approach to enable reproducible computational experiments because of its support of on-demand hardware and software resource provisioning. Yet there are still two main difficulties in reproducing big data applications in the cloud. The first is how to automate end-to-end execution of big data analytics in the cloud including virtual distributed environment provisioning, network and security group setup, and big data analytics pipeline description and execution. The second is an application developed for one cloud, such as AWS or Azure, is difficult to reproduce in another cloud, a.k.a. vendor lock-in problem. To tackle these problems, we leverage serverless computing and containerization techniques for automatic scalable big data application execution and reproducibility, and utilize the adapter design pattern to enable application portability and reproducibility across different clouds. Based on the approach, we propose and develop an open-source toolkit that supports 1) on-demand distributed hardware and software environment provisioning, 2) automatic data and configuration storage for each execution, 3) flexible client modes based on user preferences, 4) execution history query, and 5) simple reproducibility of existing executions in the same environment or a different environment. We did extensive experiments on both AWS and Azure using three big data analytics applications that run on a virtual CPU/GPU cluster. Three main behaviors of our toolkit were benchmarked: i) execution overhead ratio for reproducibility support, ii) differences of reproducing the same application on AWS and Azure in terms of execution time, budgetary cost and cost-performance ratio, iii) differences between scale-out and scale-up approach for the same application on AWS and Azure.
CCS-GAN: COVID-19 CT-scan classification with very few positive training images
Oct 01, 2021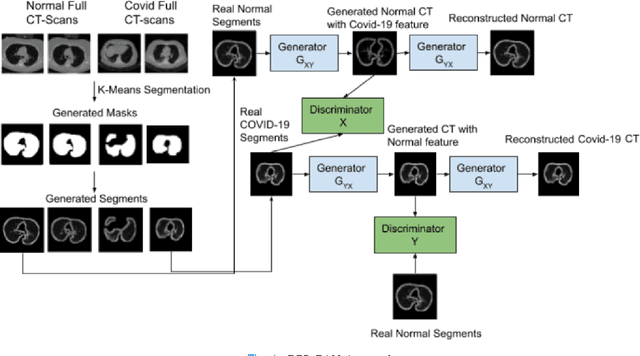

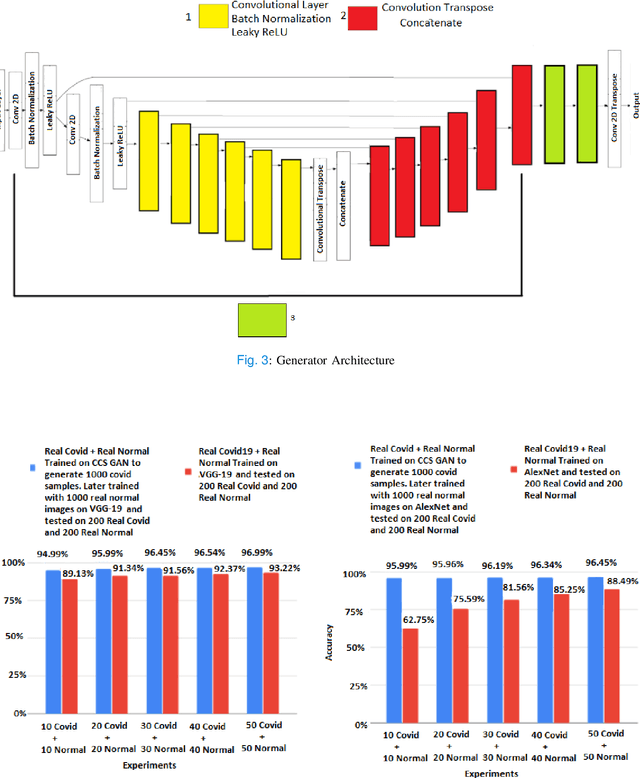
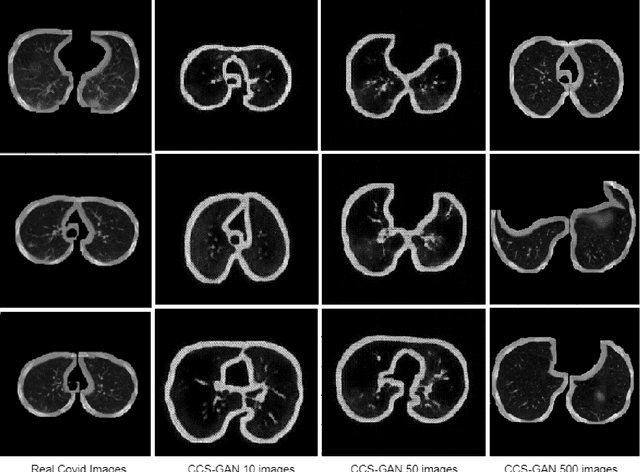
We present a novel algorithm that is able to classify COVID-19 pneumonia from CT Scan slices using a very small sample of training images exhibiting COVID-19 pneumonia in tandem with a larger number of normal images. This algorithm is able to achieve high classification accuracy using as few as 10 positive training slices (from 10 positive cases), which to the best of our knowledge is one order of magnitude fewer than the next closest published work at the time of writing. Deep learning with extremely small positive training volumes is a very difficult problem and has been an important topic during the COVID-19 pandemic, because for quite some time it was difficult to obtain large volumes of COVID-19 positive images for training. Algorithms that can learn to screen for diseases using few examples are an important area of research. We present the Cycle Consistent Segmentation Generative Adversarial Network (CCS-GAN). CCS-GAN combines style transfer with pulmonary segmentation and relevant transfer learning from negative images in order to create a larger volume of synthetic positive images for the purposes of improving diagnostic classification performance. The performance of a VGG-19 classifier plus CCS-GAN was trained using a small sample of positive image slices ranging from at most 50 down to as few as 10 COVID-19 positive CT-scan images. CCS-GAN achieves high accuracy with few positive images and thereby greatly reduces the barrier of acquiring large training volumes in order to train a diagnostic classifier for COVID-19.
Toward Generating Synthetic CT Volumes using a 3D-Conditional Generative Adversarial Network
Apr 02, 2021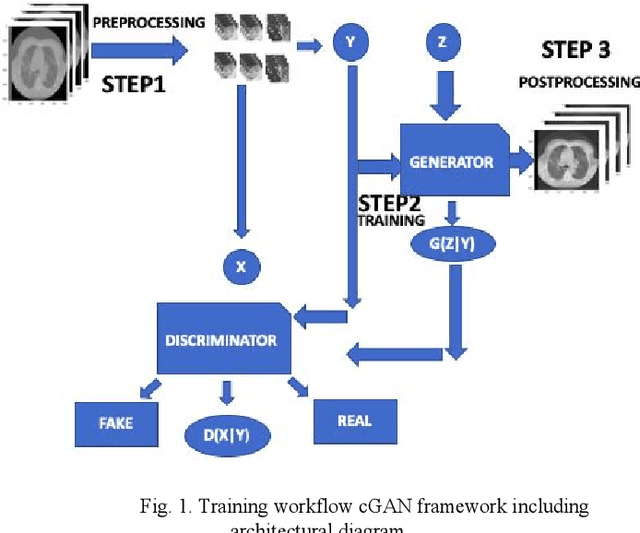
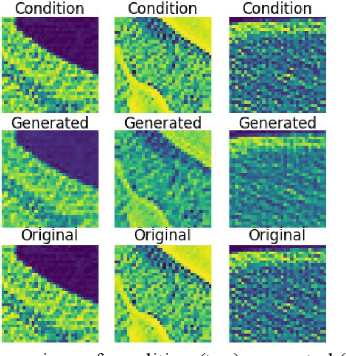
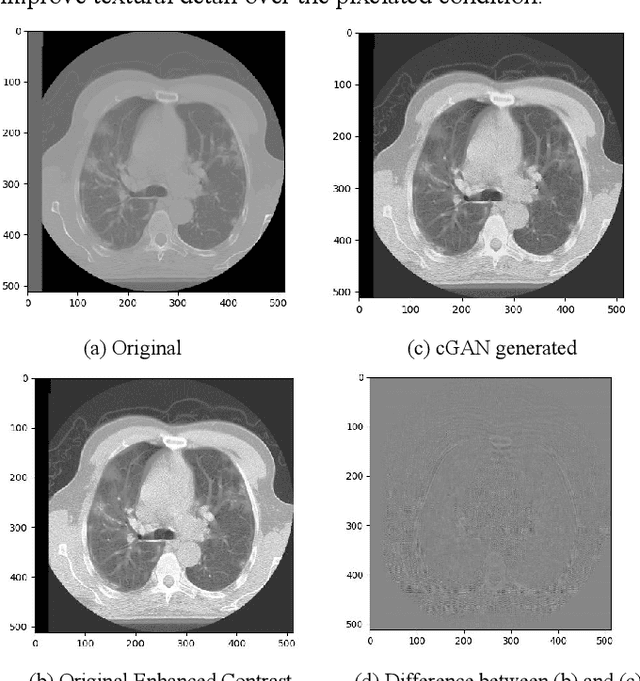
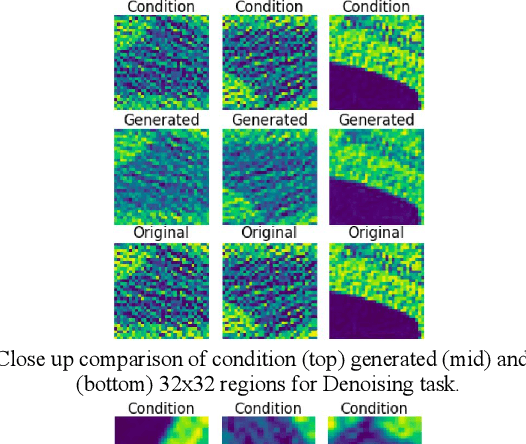
We present a novel conditional Generative Adversarial Network (cGAN) architecture that is capable of generating 3D Computed Tomography scans in voxels from noisy and/or pixelated approximations and with the potential to generate full synthetic 3D scan volumes. We believe conditional cGAN to be a tractable approach to generate 3D CT volumes, even though the problem of generating full resolution deep fakes is presently impractical due to GPU memory limitations. We present results for autoencoder, denoising, and depixelating tasks which are trained and tested on two novel COVID19 CT datasets. Our evaluation metrics, Peak Signal to Noise ratio (PSNR) range from 12.53 - 46.46 dB, and the Structural Similarity index ( SSIM) range from 0.89 to 1.
Generating Realistic COVID19 X-rays with a Mean Teacher + Transfer Learning GAN
Sep 26, 2020
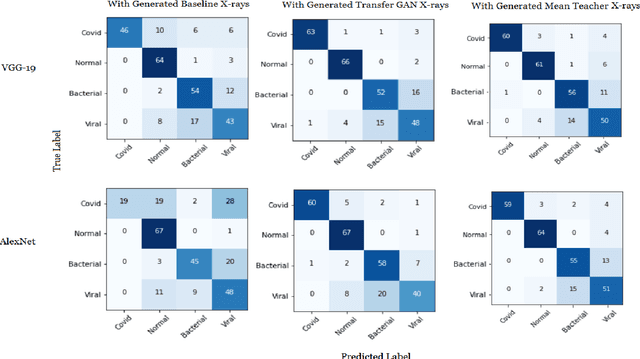
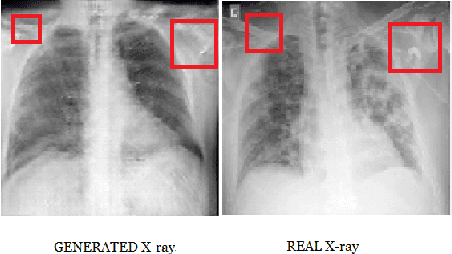
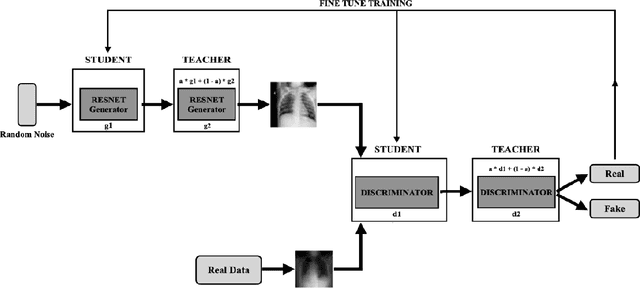
COVID-19 is a novel infectious disease responsible for over 800K deaths worldwide as of August 2020. The need for rapid testing is a high priority and alternative testing strategies including X-ray image classification are a promising area of research. However, at present, public datasets for COVID19 x-ray images have low data volumes, making it challenging to develop accurate image classifiers. Several recent papers have made use of Generative Adversarial Networks (GANs) in order to increase the training data volumes. But realistic synthetic COVID19 X-rays remain challenging to generate. We present a novel Mean Teacher + Transfer GAN (MTT-GAN) that generates COVID19 chest X-ray images of high quality. In order to create a more accurate GAN, we employ transfer learning from the Kaggle Pneumonia X-Ray dataset, a highly relevant data source orders of magnitude larger than public COVID19 datasets. Furthermore, we employ the Mean Teacher algorithm as a constraint to improve stability of training. Our qualitative analysis shows that the MTT-GAN generates X-ray images that are greatly superior to a baseline GAN and visually comparable to real X-rays. Although board-certified radiologists can distinguish MTT-GAN fakes from real COVID19 X-rays. Quantitative analysis shows that MTT-GAN greatly improves the accuracy of both a binary COVID19 classifier as well as a multi-class Pneumonia classifier as compared to a baseline GAN. Our classification accuracy is favourable as compared to recently reported results in the literature for similar binary and multi-class COVID19 screening tasks.
AutoCogniSys: IoT Assisted Context-Aware Automatic Cognitive Health Assessment
Mar 17, 2020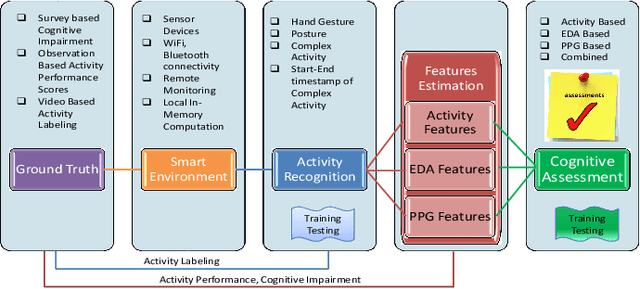
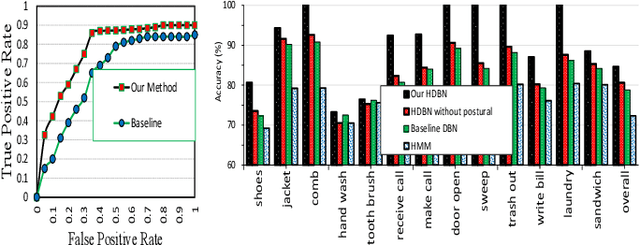
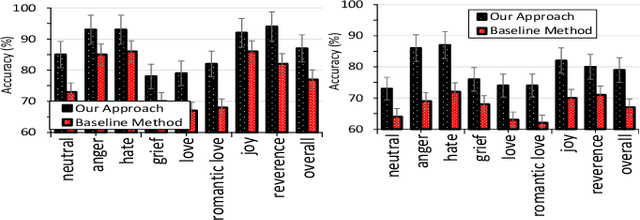
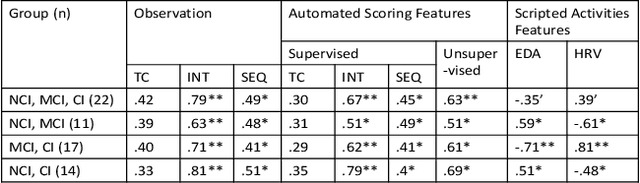
Cognitive impairment has become epidemic in older adult population. The recent advent of tiny wearable and ambient devices, a.k.a Internet of Things (IoT) provides ample platforms for continuous functional and cognitive health assessment of older adults. In this paper, we design, implement and evaluate AutoCogniSys, a context-aware automated cognitive health assessment system, combining the sensing powers of wearable physiological (Electrodermal Activity, Photoplethysmography) and physical (Accelerometer, Object) sensors in conjunction with ambient sensors. We design appropriate signal processing and machine learning techniques, and develop an automatic cognitive health assessment system in a natural older adults living environment. We validate our approaches using two datasets: (i) a naturalistic sensor data streams related to Activities of Daily Living and mental arousal of 22 older adults recruited in a retirement community center, individually living in their own apartments using a customized inexpensive IoT system (IRB #HP-00064387) and (ii) a publicly available dataset for emotion detection. The performance of AutoCogniSys attests max. 93\% of accuracy in assessing cognitive health of older adults.