 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving VTE Identification through Language Models from Radiology Reports: A Comparative Study of Mamba, Phi-3 Mini, and BERT
Aug 16, 2024



Venous thromboembolism (VTE) is a critical cardiovascular condition, encompassing deep vein thrombosis (DVT) and pulmonary embolism (PE). Accurate and timely identification of VTE is essential for effective medical care. This study builds upon our previous work, which addressed VTE detection using deep learning methods for DVT and a hybrid approach combining deep learning and rule-based classification for PE. Our earlier approaches, while effective, had two major limitations: they were complex and required expert involvement for feature engineering of the rule set. To overcome these challenges, we utilize the Mamba architecture-based classifier. This model achieves remarkable results, with a 97\% accuracy and F1 score on the DVT dataset and a 98\% accuracy and F1 score on the PE dataset. In contrast to the previous hybrid method on PE identification, the Mamba classifier eliminates the need for hand-engineered rules, significantly reducing model complexity while maintaining comparable performance. Additionally, we evaluated a lightweight Large Language Model (LLM), Phi-3 Mini, in detecting VTE. While this model delivers competitive results, outperforming the baseline BERT models, it proves to be computationally intensive due to its larger parameter set. Our evaluation shows that the Mamba-based model demonstrates superior performance and efficiency in VTE identification, offering an effective solution to the limitations of previous approaches.
Efficient Data-Sketches and Fine-Tuning for Early Detection of Distributional Drift in Medical Imaging
Aug 15, 2024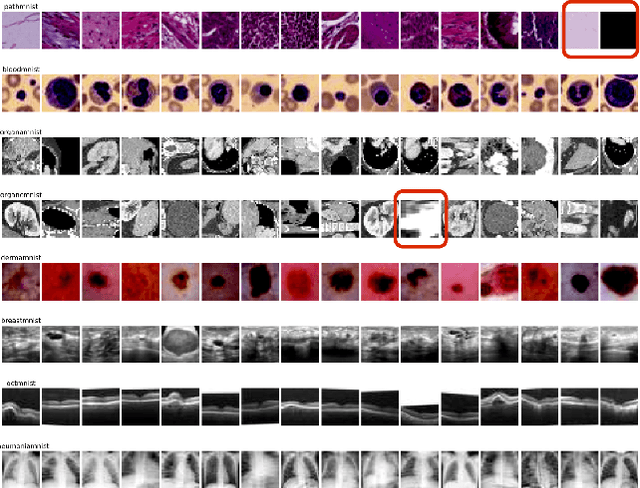
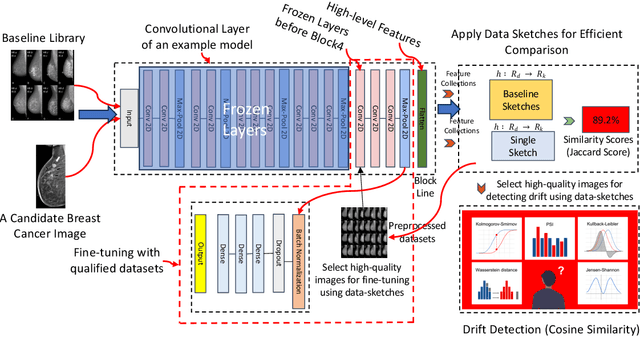
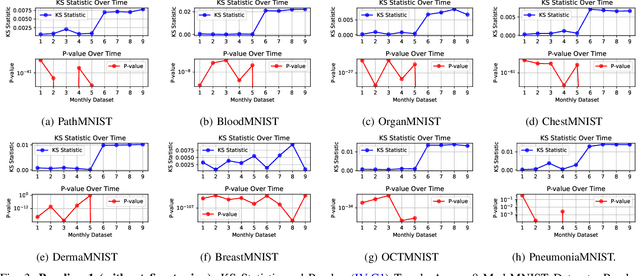
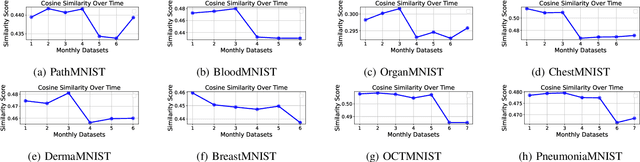
Distributional drift detection is important in medical applications as it helps ensure the accuracy and reliability of models by identifying changes in the underlying data distribution that could affect diagnostic or treatment decisions. However, current methods have limitations in detecting drift; for example, the inclusion of abnormal datasets can lead to unfair comparisons. This paper presents an accurate and sensitive approach to detect distributional drift in CT-scan medical images by leveraging data-sketching and fine-tuning techniques. We developed a robust baseline library model for real-time anomaly detection, allowing for efficient comparison of incoming images and identification of anomalies. Additionally, we fine-tuned a vision transformer pre-trained model to extract relevant features using breast cancer images as an example, significantly enhancing model accuracy to 99.11\%. Combining with data-sketches and fine-tuning, our feature extraction evaluation demonstrated that cosine similarity scores between similar datasets provide greater improvements, from around 50\% increased to 100\%. Finally, the sensitivity evaluation shows that our solutions are highly sensitive to even 1\% salt-and-pepper and speckle noise, and it is not sensitive to lighting noise (e.g., lighting conditions have no impact on data drift). The proposed methods offer a scalable and reliable solution for maintaining the accuracy of diagnostic models in dynamic clinical environments.
Improving VTE Identification through Adaptive NLP Model Selection and Clinical Expert Rule-based Classifier from Radiology Reports
Sep 21, 2023



Rapid and accurate identification of Venous thromboembolism (VTE), a severe cardiovascular condition including deep vein thrombosis (DVT) and pulmonary embolism (PE), is important for effective treatment. Leveraging Natural Language Processing (NLP) on radiology reports, automated methods have shown promising advancements in identifying VTE events from retrospective data cohorts or aiding clinical experts in identifying VTE events from radiology reports. However, effectively training Deep Learning (DL) and the NLP models is challenging due to limited labeled medical text data, the complexity and heterogeneity of radiology reports, and data imbalance. This study proposes novel method combinations of DL methods, along with data augmentation, adaptive pre-trained NLP model selection, and a clinical expert NLP rule-based classifier, to improve the accuracy of VTE identification in unstructured (free-text) radiology reports. Our experimental results demonstrate the model's efficacy, achieving an impressive 97\% accuracy and 97\% F1 score in predicting DVT, and an outstanding 98.3\% accuracy and 98.4\% F1 score in predicting PE. These findings emphasize the model's robustness and its potential to significantly contribute to VTE research.
Enabling Quartile-based Estimated-Mean Gradient Aggregation As Baseline for Federated Image Classifications
Sep 21, 2023



Federated Learning (FL) has revolutionized how we train deep neural networks by enabling decentralized collaboration while safeguarding sensitive data and improving model performance. However, FL faces two crucial challenges: the diverse nature of data held by individual clients and the vulnerability of the FL system to security breaches. This paper introduces an innovative solution named Estimated Mean Aggregation (EMA) that not only addresses these challenges but also provides a fundamental reference point as a $\mathsf{baseline}$ for advanced aggregation techniques in FL systems. EMA's significance lies in its dual role: enhancing model security by effectively handling malicious outliers through trimmed means and uncovering data heterogeneity to ensure that trained models are adaptable across various client datasets. Through a wealth of experiments, EMA consistently demonstrates high accuracy and area under the curve (AUC) compared to alternative methods, establishing itself as a robust baseline for evaluating the effectiveness and security of FL aggregation methods. EMA's contributions thus offer a crucial step forward in advancing the efficiency, security, and versatility of decentralized deep learning in the context of FL.
Soft Merging: A Flexible and Robust Soft Model Merging Approach for Enhanced Neural Network Performance
Sep 21, 2023



Stochastic Gradient Descent (SGD), a widely used optimization algorithm in deep learning, is often limited to converging to local optima due to the non-convex nature of the problem. Leveraging these local optima to improve model performance remains a challenging task. Given the inherent complexity of neural networks, the simple arithmetic averaging of the obtained local optima models in undesirable results. This paper proposes a {\em soft merging} method that facilitates rapid merging of multiple models, simplifies the merging of specific parts of neural networks, and enhances robustness against malicious models with extreme values. This is achieved by learning gate parameters through a surrogate of the $l_0$ norm using hard concrete distribution without modifying the model weights of the given local optima models. This merging process not only enhances the model performance by converging to a better local optimum, but also minimizes computational costs, offering an efficient and explicit learning process integrated with stochastic gradient descent. Thorough experiments underscore the effectiveness and superior performance of the merged neural networks.
CCS-GAN: COVID-19 CT-scan classification with very few positive training images
Oct 01, 2021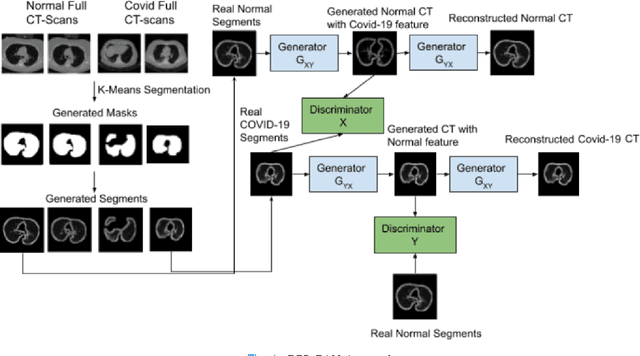

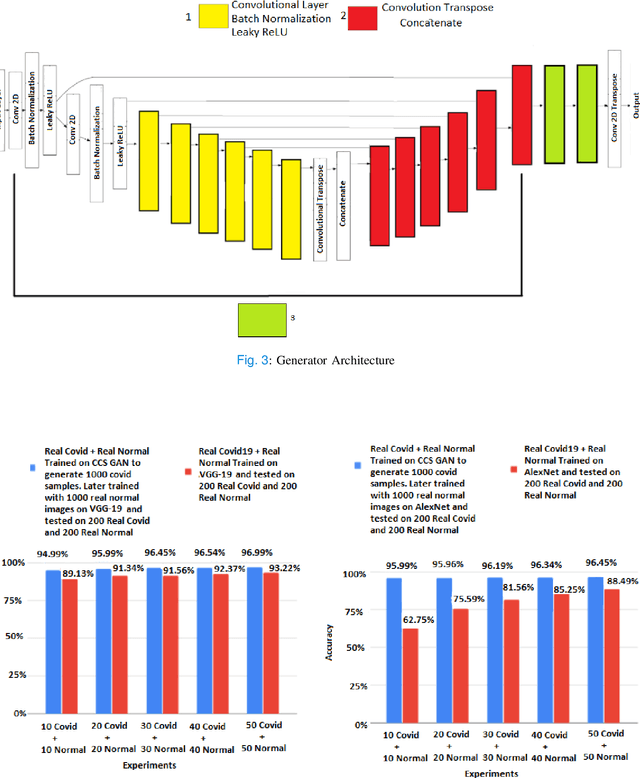
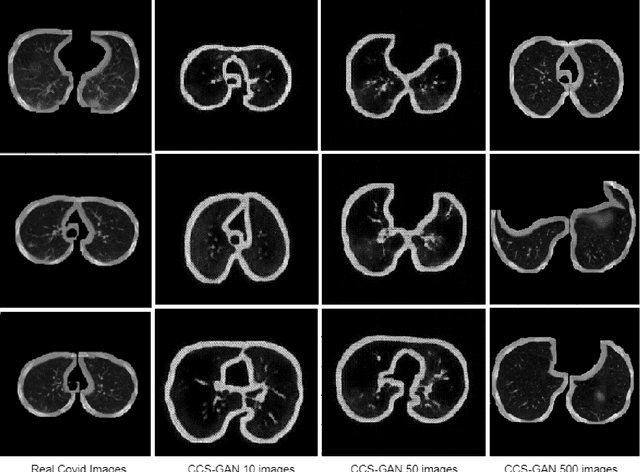
We present a novel algorithm that is able to classify COVID-19 pneumonia from CT Scan slices using a very small sample of training images exhibiting COVID-19 pneumonia in tandem with a larger number of normal images. This algorithm is able to achieve high classification accuracy using as few as 10 positive training slices (from 10 positive cases), which to the best of our knowledge is one order of magnitude fewer than the next closest published work at the time of writing. Deep learning with extremely small positive training volumes is a very difficult problem and has been an important topic during the COVID-19 pandemic, because for quite some time it was difficult to obtain large volumes of COVID-19 positive images for training. Algorithms that can learn to screen for diseases using few examples are an important area of research. We present the Cycle Consistent Segmentation Generative Adversarial Network (CCS-GAN). CCS-GAN combines style transfer with pulmonary segmentation and relevant transfer learning from negative images in order to create a larger volume of synthetic positive images for the purposes of improving diagnostic classification performance. The performance of a VGG-19 classifier plus CCS-GAN was trained using a small sample of positive image slices ranging from at most 50 down to as few as 10 COVID-19 positive CT-scan images. CCS-GAN achieves high accuracy with few positive images and thereby greatly reduces the barrier of acquiring large training volumes in order to train a diagnostic classifier for COVID-19.
Tolerating Adversarial Attacks and Byzantine Faults in Distributed Machine Learning
Sep 05, 2021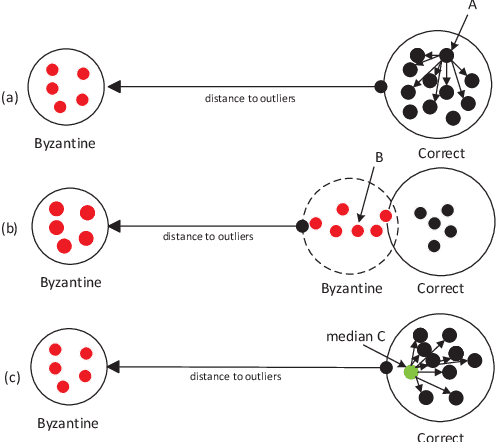
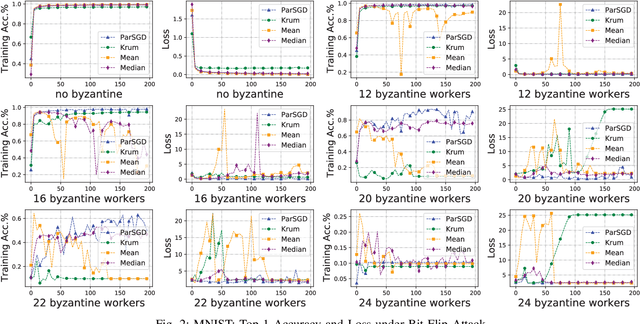

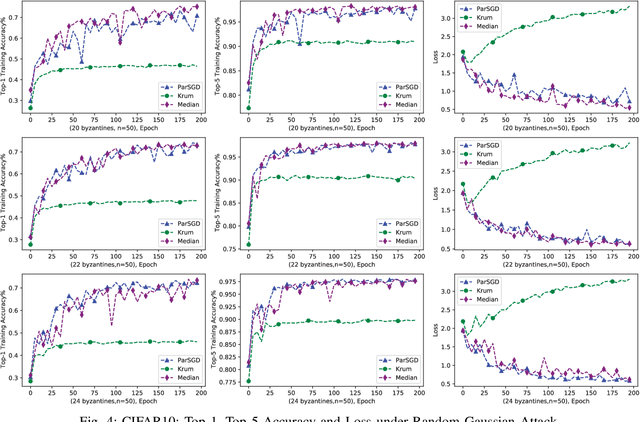
Adversarial attacks attempt to disrupt the training, retraining and utilizing of artificial intelligence and machine learning models in large-scale distributed machine learning systems. This causes security risks on its prediction outcome. For example, attackers attempt to poison the model by either presenting inaccurate misrepresentative data or altering the models' parameters. In addition, Byzantine faults including software, hardware, network issues occur in distributed systems which also lead to a negative impact on the prediction outcome. In this paper, we propose a novel distributed training algorithm, partial synchronous stochastic gradient descent (ParSGD), which defends adversarial attacks and/or tolerates Byzantine faults. We demonstrate the effectiveness of our algorithm under three common adversarial attacks again the ML models and a Byzantine fault during the training phase. Our results show that using ParSGD, ML models can still produce accurate predictions as if it is not being attacked nor having failures at all when almost half of the nodes are being compromised or failed. We will report the experimental evaluations of ParSGD in comparison with other algorithms.
Toward Generating Synthetic CT Volumes using a 3D-Conditional Generative Adversarial Network
Apr 02, 2021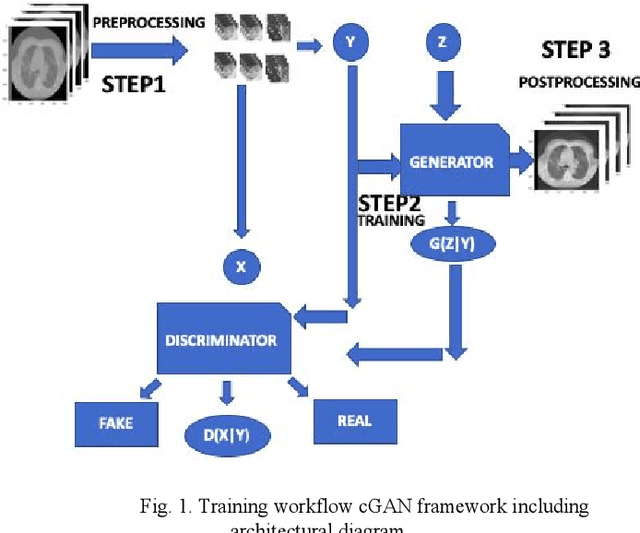
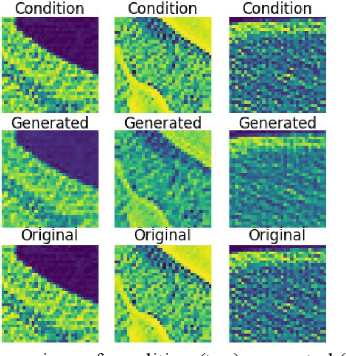
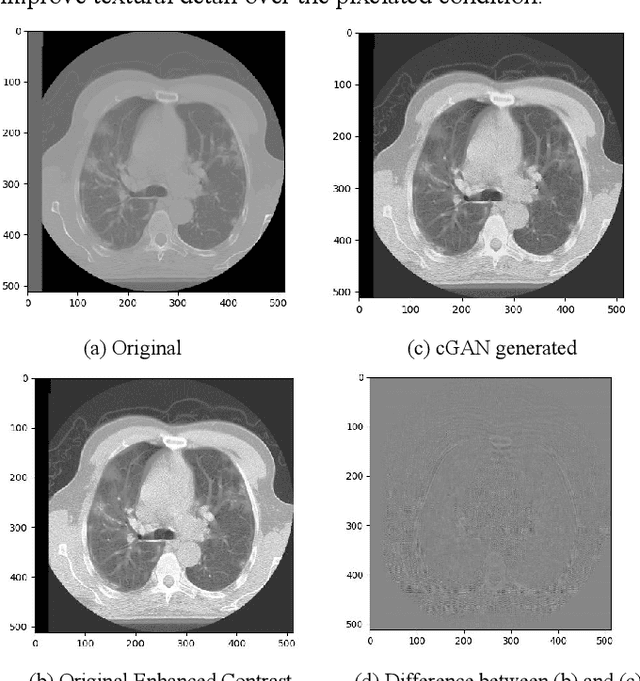
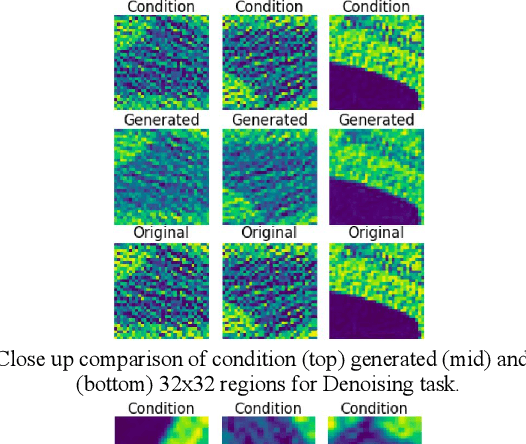
We present a novel conditional Generative Adversarial Network (cGAN) architecture that is capable of generating 3D Computed Tomography scans in voxels from noisy and/or pixelated approximations and with the potential to generate full synthetic 3D scan volumes. We believe conditional cGAN to be a tractable approach to generate 3D CT volumes, even though the problem of generating full resolution deep fakes is presently impractical due to GPU memory limitations. We present results for autoencoder, denoising, and depixelating tasks which are trained and tested on two novel COVID19 CT datasets. Our evaluation metrics, Peak Signal to Noise ratio (PSNR) range from 12.53 - 46.46 dB, and the Structural Similarity index ( SSIM) range from 0.89 to 1.
Deep Expectation-Maximization for Semi-Supervised Lung Cancer Screening
Oct 02, 2020
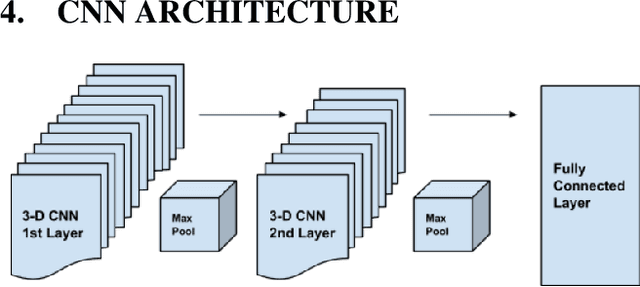
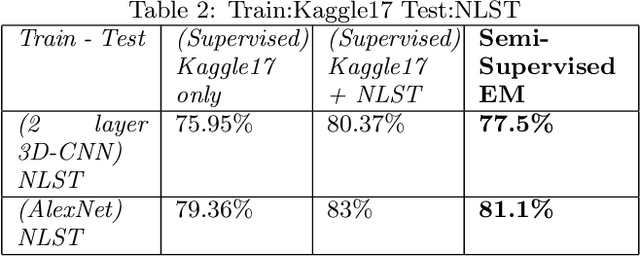
We present a semi-supervised algorithm for lung cancer screening in which a 3D Convolutional Neural Network (CNN) is trained using the Expectation-Maximization (EM) meta-algorithm. Semi-supervised learning allows a smaller labelled data-set to be combined with an unlabeled data-set in order to provide a larger and more diverse training sample. EM allows the algorithm to simultaneously calculate a maximum likelihood estimate of the CNN training coefficients along with the labels for the unlabeled training set which are defined as a latent variable space. We evaluate the model performance of the Semi-Supervised EM algorithm for CNNs through cross-domain training of the Kaggle Data Science Bowl 2017 (Kaggle17) data-set with the National Lung Screening Trial (NLST) data-set. Our results show that the Semi-Supervised EM algorithm greatly improves the classification accuracy of the cross-domain lung cancer screening, although results are lower than a fully supervised approach with the advantage of additional labelled data from the unsupervised sample. As such, we demonstrate that Semi-Supervised EM is a valuable technique to improve the accuracy of lung cancer screening models using 3D CNNs.
Generating Realistic COVID19 X-rays with a Mean Teacher + Transfer Learning GAN
Sep 26, 2020
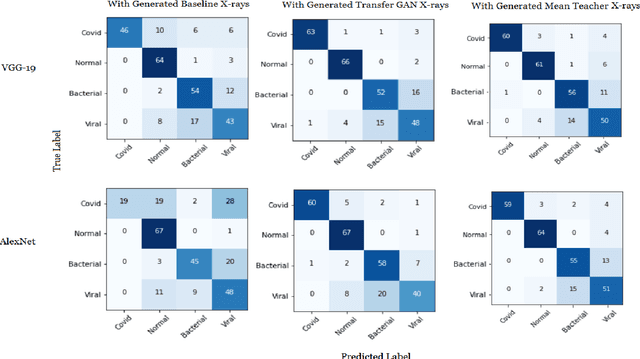
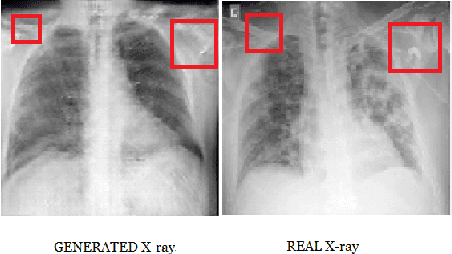
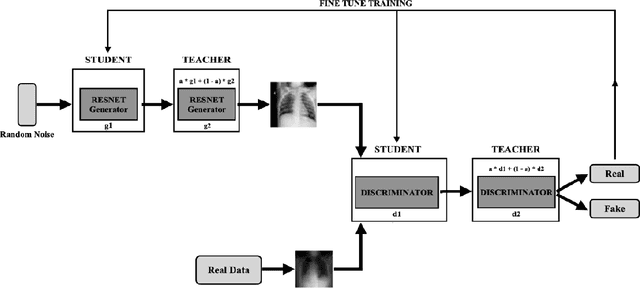
COVID-19 is a novel infectious disease responsible for over 800K deaths worldwide as of August 2020. The need for rapid testing is a high priority and alternative testing strategies including X-ray image classification are a promising area of research. However, at present, public datasets for COVID19 x-ray images have low data volumes, making it challenging to develop accurate image classifiers. Several recent papers have made use of Generative Adversarial Networks (GANs) in order to increase the training data volumes. But realistic synthetic COVID19 X-rays remain challenging to generate. We present a novel Mean Teacher + Transfer GAN (MTT-GAN) that generates COVID19 chest X-ray images of high quality. In order to create a more accurate GAN, we employ transfer learning from the Kaggle Pneumonia X-Ray dataset, a highly relevant data source orders of magnitude larger than public COVID19 datasets. Furthermore, we employ the Mean Teacher algorithm as a constraint to improve stability of training. Our qualitative analysis shows that the MTT-GAN generates X-ray images that are greatly superior to a baseline GAN and visually comparable to real X-rays. Although board-certified radiologists can distinguish MTT-GAN fakes from real COVID19 X-rays. Quantitative analysis shows that MTT-GAN greatly improves the accuracy of both a binary COVID19 classifier as well as a multi-class Pneumonia classifier as compared to a baseline GAN. Our classification accuracy is favourable as compared to recently reported results in the literature for similar binary and multi-class COVID19 screening tasks.