 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChartFI: Benchmarking Faithfulness and Insightfulness of Chart Descriptions from Multimodal Large Language Models
May 22, 2026Chart descriptions are essential for accessibility, cross-modal retrieval, and assisting readers in extracting insights from complex visualizations. As multimodal large language models (MLLMs) are increasingly adopted for automated chart description generation, a critical question arises: how faithfully and insightfully do these models actually describe charts? Current benchmarks fall short on two fronts: existing datasets consist of simple, homogeneous charts paired with shallow, fact-enumerating descriptions; and prevailing metrics fail to capture the multi-faceted nature of description quality. To address these gaps, we present the Chart Faithfulness and Insightfulness Benchmark (ChartFI-Bench). We first summarize four dimensions that characterize high-quality chart descriptions: factual accuracy, salient feature emphasis, domain-informed guidance, and chart-text complementarity. Guided by these dimensions, we construct a high-quality benchmark comprising 896 chart-description pairs, which feature visually complex charts and semantically rich descriptions. Furthermore, we design four aligned evaluation metrics -- Faithfulness, Coverage, Informativeness, and Acuity -- to systematically assess the quality of descriptions across these dimensions. Experiments conducted on mainstream MLLMs demonstrate the effectiveness of the proposed framework and reveal common weaknesses among existing models.
A Dynamic Toolkit for Transmission Characteristics of Precision Reducers with Explicit Contact Geometry
Apr 02, 2026Precision reducers are critical components in robotic systems, directly affecting the motion accuracy and dynamic performance of humanoid robots, quadruped robots, collaborative robots, industrial robots, and SCARA robots. This paper presents a dynamic toolkit for analyzing the transmission characteristics of precision reducers with explicit contact geometry. A unified framework is proposed to address the challenges in modeling accurate contact behaviors, evaluating gear stiffness, and predicting system vibrations. By integrating advanced contact theories and numerical solving methods, the proposed toolkit offers higher precision and computational efficiency compared to traditional dynamics software. The toolkit is designed with a modular, scriptable architecture that supports rapid reconfiguration across diverse reducer topologies. Numerical validation against published benchmarks confirms the accuracy of the proposed approach.
Mode Seeking meets Mean Seeking for Fast Long Video Generation
Feb 27, 2026Scaling video generation from seconds to minutes faces a critical bottleneck: while short-video data is abundant and high-fidelity, coherent long-form data is scarce and limited to narrow domains. To address this, we propose a training paradigm where Mode Seeking meets Mean Seeking, decoupling local fidelity from long-term coherence based on a unified representation via a Decoupled Diffusion Transformer. Our approach utilizes a global Flow Matching head trained via supervised learning on long videos to capture narrative structure, while simultaneously employing a local Distribution Matching head that aligns sliding windows to a frozen short-video teacher via a mode-seeking reverse-KL divergence. This strategy enables the synthesis of minute-scale videos that learns long-range coherence and motions from limited long videos via supervised flow matching, while inheriting local realism by aligning every sliding-window segment of the student to a frozen short-video teacher, resulting in a few-step fast long video generator. Evaluations show that our method effectively closes the fidelity-horizon gap by jointly improving local sharpness, motion and long-range consistency. Project website: https://primecai.github.io/mmm/.
Spectral Disentanglement and Enhancement: A Dual-domain Contrastive Framework for Representation Learning
Feb 09, 2026Large-scale multimodal contrastive learning has recently achieved impressive success in learning rich and transferable representations, yet it remains fundamentally limited by the uniform treatment of feature dimensions and the neglect of the intrinsic spectral structure of the learned features. Empirical evidence indicates that high-dimensional embeddings tend to collapse into narrow cones, concentrating task-relevant semantics in a small subspace, while the majority of dimensions remain occupied by noise and spurious correlations. Such spectral imbalance and entanglement undermine model generalization. We propose Spectral Disentanglement and Enhancement (SDE), a novel framework that bridges the gap between the geometry of the embedded spaces and their spectral properties. Our approach leverages singular value decomposition to adaptively partition feature dimensions into strong signals that capture task-critical semantics, weak signals that reflect ancillary correlations, and noise representing irrelevant perturbations. A curriculum-based spectral enhancement strategy is then applied, selectively amplifying informative components with theoretical guarantees on training stability. Building upon the enhanced features, we further introduce a dual-domain contrastive loss that jointly optimizes alignment in both the feature and spectral spaces, effectively integrating spectral regularization into the training process and encouraging richer, more robust representations. Extensive experiments on large-scale multimodal benchmarks demonstrate that SDE consistently improves representation robustness and generalization, outperforming state-of-the-art methods. SDE integrates seamlessly with existing contrastive pipelines, offering an effective solution for multimodal representation learning.
Transition Matching Distillation for Fast Video Generation
Jan 14, 2026Large video diffusion and flow models have achieved remarkable success in high-quality video generation, but their use in real-time interactive applications remains limited due to their inefficient multi-step sampling process. In this work, we present Transition Matching Distillation (TMD), a novel framework for distilling video diffusion models into efficient few-step generators. The central idea of TMD is to match the multi-step denoising trajectory of a diffusion model with a few-step probability transition process, where each transition is modeled as a lightweight conditional flow. To enable efficient distillation, we decompose the original diffusion backbone into two components: (1) a main backbone, comprising the majority of early layers, that extracts semantic representations at each outer transition step; and (2) a flow head, consisting of the last few layers, that leverages these representations to perform multiple inner flow updates. Given a pretrained video diffusion model, we first introduce a flow head to the model, and adapt it into a conditional flow map. We then apply distribution matching distillation to the student model with flow head rollout in each transition step. Extensive experiments on distilling Wan2.1 1.3B and 14B text-to-video models demonstrate that TMD provides a flexible and strong trade-off between generation speed and visual quality. In particular, TMD outperforms existing distilled models under comparable inference costs in terms of visual fidelity and prompt adherence. Project page: https://research.nvidia.com/labs/genair/tmd
On the Adversarial Robustness of 3D Large Vision-Language Models
Jan 10, 20263D Vision-Language Models (VLMs), such as PointLLM and GPT4Point, have shown strong reasoning and generalization abilities in 3D understanding tasks. However, their adversarial robustness remains largely unexplored. Prior work in 2D VLMs has shown that the integration of visual inputs significantly increases vulnerability to adversarial attacks, making these models easier to manipulate into generating toxic or misleading outputs. In this paper, we investigate whether incorporating 3D vision similarly compromises the robustness of 3D VLMs. To this end, we present the first systematic study of adversarial robustness in point-based 3D VLMs. We propose two complementary attack strategies: \textit{Vision Attack}, which perturbs the visual token features produced by the 3D encoder and projector to assess the robustness of vision-language alignment; and \textit{Caption Attack}, which directly manipulates output token sequences to evaluate end-to-end system robustness. Each attack includes both untargeted and targeted variants to measure general vulnerability and susceptibility to controlled manipulation. Our experiments reveal that 3D VLMs exhibit significant adversarial vulnerabilities under untargeted attacks, while demonstrating greater resilience against targeted attacks aimed at forcing specific harmful outputs, compared to their 2D counterparts. These findings highlight the importance of improving the adversarial robustness of 3D VLMs, especially as they are deployed in safety-critical applications.
DynaFix: Iterative Automated Program Repair Driven by Execution-Level Dynamic Information
Dec 31, 2025Automated Program Repair (APR) aims to automatically generate correct patches for buggy programs. Recent approaches leveraging large language models (LLMs) have shown promise but face limitations. Most rely solely on static analysis, ignoring runtime behaviors. Some attempt to incorporate dynamic signals, but these are often restricted to training or fine-tuning, or injected only once into the repair prompt, without iterative use. This fails to fully capture program execution. Current iterative repair frameworks typically rely on coarse-grained feedback, such as pass/fail results or exception types, and do not leverage fine-grained execution-level information effectively. As a result, models struggle to simulate human stepwise debugging, limiting their effectiveness in multi-step reasoning and complex bug repair. To address these challenges, we propose DynaFix, an execution-level dynamic information-driven APR method that iteratively leverages runtime information to refine the repair process. In each repair round, DynaFix captures execution-level dynamic information such as variable states, control-flow paths, and call stacks, transforming them into structured prompts to guide LLMs in generating candidate patches. If a patch fails validation, DynaFix re-executes the modified program to collect new execution information for the next attempt. This iterative loop incrementally improves patches based on updated feedback, similar to the stepwise debugging practices of human developers. We evaluate DynaFix on the Defects4J v1.2 and v2.0 benchmarks. DynaFix repairs 186 single-function bugs, a 10% improvement over state-of-the-art baselines, including 38 bugs previously unrepaired. It achieves correct patches within at most 35 attempts, reducing the patch search space by 70% compared with existing methods, thereby demonstrating both effectiveness and efficiency in repairing complex bugs.
AKG kernel Agent: A Multi-Agent Framework for Cross-Platform Kernel Synthesis
Dec 29, 2025Modern AI models demand high-performance computation kernels. The growing complexity of LLMs, multimodal architectures, and recommendation systems, combined with techniques like sparsity and quantization, creates significant computational challenges. Moreover, frequent hardware updates and diverse chip architectures further complicate this landscape, requiring tailored kernel implementations for each platform. However, manual optimization cannot keep pace with these demands, creating a critical bottleneck in AI system development. Recent advances in LLM code generation capabilities have opened new possibilities for automating kernel development. In this work, we propose AKG kernel agent (AI-driven Kernel Generator), a multi-agent system that automates kernel generation, migration, and performance tuning. AKG kernel agent is designed to support multiple domain-specific languages (DSLs), including Triton, TileLang, CPP, and CUDA-C, enabling it to target different hardware backends while maintaining correctness and portability. The system's modular design allows rapid integration of new DSLs and hardware targets. When evaluated on KernelBench using Triton DSL across GPU and NPU backends, AKG kernel agent achieves an average speedup of 1.46$\times$ over PyTorch Eager baselines implementations, demonstrating its effectiveness in accelerating kernel development for modern AI workloads.
FocusMed: A Large Language Model-based Framework for Enhancing Medical Question Summarization with Focus Identification
Oct 06, 2025
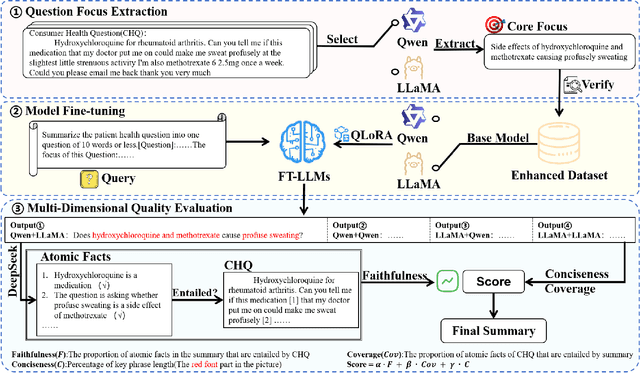

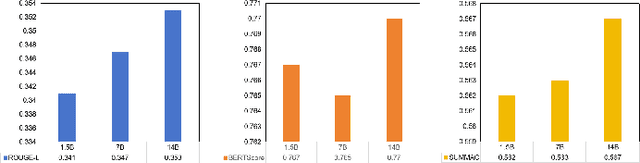
With the rapid development of online medical platforms, consumer health questions (CHQs) are inefficient in diagnosis due to redundant information and frequent non-professional terms. The medical question summary (MQS) task aims to transform CHQs into streamlined doctors' frequently asked questions (FAQs), but existing methods still face challenges such as poor identification of question focus and model hallucination. This paper explores the potential of large language models (LLMs) in the MQS task and finds that direct fine-tuning is prone to focus identification bias and generates unfaithful content. To this end, we propose an optimization framework based on core focus guidance. First, a prompt template is designed to drive the LLMs to extract the core focus from the CHQs that is faithful to the original text. Then, a fine-tuning dataset is constructed in combination with the original CHQ-FAQ pairs to improve the ability to identify the focus of the question. Finally, a multi-dimensional quality evaluation and selection mechanism is proposed to comprehensively improve the quality of the summary from multiple dimensions. We conduct comprehensive experiments on two widely-adopted MQS datasets using three established evaluation metrics. The proposed framework achieves state-of-the-art performance across all measures, demonstrating a significant boost in the model's ability to identify critical focus of questions and a notable mitigation of hallucinations. The source codes are freely available at https://github.com/DUT-LiuChao/FocusMed.
Balancing Utility and Privacy: Dynamically Private SGD with Random Projection
Sep 11, 2025Stochastic optimization is a pivotal enabler in modern machine learning, producing effective models for various tasks. However, several existing works have shown that model parameters and gradient information are susceptible to privacy leakage. Although Differentially Private SGD (DPSGD) addresses privacy concerns, its static noise mechanism impacts the error bounds for model performance. Additionally, with the exponential increase in model parameters, efficient learning of these models using stochastic optimizers has become more challenging. To address these concerns, we introduce the Dynamically Differentially Private Projected SGD (D2P2-SGD) optimizer. In D2P2-SGD, we combine two important ideas: (i) dynamic differential privacy (DDP) with automatic gradient clipping and (ii) random projection with SGD, allowing dynamic adjustment of the tradeoff between utility and privacy of the model. It exhibits provably sub-linear convergence rates across different objective functions, matching the best available rate. The theoretical analysis further suggests that DDP leads to better utility at the cost of privacy, while random projection enables more efficient model learning. Extensive experiments across diverse datasets show that D2P2-SGD remarkably enhances accuracy while maintaining privacy. Our code is available here.