 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLighting-aware Unified Model for Instance Segmentation
May 19, 2026Foundation models like the Segment Anything Model (SAM) demonstrate impressive zero-shot generalization but frequently degrade under diverse real-world illumination, particularly for instance segmentation. In this work, we address this limitation by developing \textit{Lighting Convolutional-Attention (\lca{})}, an adapter module that enhances segmentation robustness without fine-tuning the heavy backbone. \lca{} employs a dual-branch architecture to process RGB features alongside contrast maps, enabling physically motivated sensitivity to structural changes rather than illumination artifacts. We optimize \lca{} through a pairwise training strategy, introducing a targeted loss term that explicitly penalizes discrepancies between clean images and their corresponding illumination variants. To evaluate and support this architecture, we conduct a comprehensive empirical study across multiple existing benchmarks and present a novel Unity-based synthetic dataset specifically designed to accurately replicate complex real-world lighting conditions. Extensive experimental results demonstrate that our approach successfully bridges the domain gap, delivering superior lighting-robust segmentation.
TabQL: In-Context Q-Learning with Tabular Foundation Models
May 18, 2026We propose Tabular Q-Learning (TabQL), a reinforcement learning framework that replaces the conventional parametric Q-network in Deep Q-Learning (DQN) with a tabular foundation model endowed with in-context learning capabilities. The key idea is to represent Q-values through a sequence-to-sequence foundation model operating over a tabularized representation of state-action-Q-value tuples, enabling rapid adaptation from limited online interaction by conditioning on recent experience. TabQL departs from classical DQN by leveraging (i) zero- or few-shot Q-value inference via in-context updates, and (ii) a warm-up phase using standard DQN to bootstrap high-quality context. Particularly, to enhance the context quality, new transitions are generated by executing actions output by TabQL with predicted Q values from DQN. We formalize TabQL, analyze its convergence and sample complexity under mild assumptions, and show that TabQL interpolates between vanilla Q-learning and DQN with in-context learning. Our analysis demonstrates that TabQL achieves improved efficiency compared to DQN by amortizing Bellman updates through in-context learning. Extensive numerical experiments with several benchmarks showcase the effectiveness and efficacy of the proposed TabQL.
COOPO: Cyclic Offline-Online Policy Optimization Algorithm
May 18, 2026Offline reinforcement learning struggles with distributional shift and constrained performance due to static dataset limitations, while online RL demands prohibitive environment interactions. The recent advent of hybrid offline-to-online methods bridges these domains but suffers from distribution drift during transitions and catastrophic forgetting of offline knowledge. We introduce COOPO (Cyclic Offline-Online Policy Optimization), a generalized framework that repeatedly cycles between constrained offline training and online fine-tuning. Each cycle first anchors the policy to the dataset via KL-regularized advantage-weighted offline updates to minimize distributional shift and then fine-tunes it online using any policy optimization for stable exploration. Crucially, periodically returning to offline training eliminates forgetting and drift while maximizing dataset reuse. The cyclic behavior also helps reduce the online environment interactions. Theoretically, COOPO achieves better online sample efficiency, surpassing pure online RL, with guaranteed monotonic improvement under standard coverage assumptions. Extensive D4RL benchmarks demonstrate COOPO reduces online interactions versus state-of-the-art hybrids while improving final returns, maintaining robustness across diverse offline algorithms and online optimizers. This looped synergy sets new efficiency and performance standards for adaptive RL.
LexiSafe: Offline Safe Reinforcement Learning with Lexicographic Safety-Reward Hierarchy
Feb 19, 2026Offline safe reinforcement learning (RL) is increasingly important for cyber-physical systems (CPS), where safety violations during training are unacceptable and only pre-collected data are available. Existing offline safe RL methods typically balance reward-safety tradeoffs through constraint relaxation or joint optimization, but they often lack structural mechanisms to prevent safety drift. We propose LexiSafe, a lexicographic offline RL framework designed to preserve safety-aligned behavior. We first develop LexiSafe-SC, a single-cost formulation for standard offline safe RL, and derive safety-violation and performance-suboptimality bounds that together yield sample-complexity guarantees. We then extend the framework to hierarchical safety requirements with LexiSafe-MC, which supports multiple safety costs and admits its own sample-complexity analysis. Empirically, LexiSafe demonstrates reduced safety violations and improved task performance compared to constrained offline baselines. By unifying lexicographic prioritization with structural bias, LexiSafe offers a practical and theoretically grounded approach for safety-critical CPS decision-making.
Bidirectional Linear Recurrent Models for Sequence-Level Multisource Fusion
Apr 11, 2025Sequence modeling is a critical yet challenging task with wide-ranging applications, especially in time series forecasting for domains like weather prediction, temperature monitoring, and energy load forecasting. Transformers, with their attention mechanism, have emerged as state-of-the-art due to their efficient parallel training, but they suffer from quadratic time complexity, limiting their scalability for long sequences. In contrast, recurrent neural networks (RNNs) offer linear time complexity, spurring renewed interest in linear RNNs for more computationally efficient sequence modeling. In this work, we introduce BLUR (Bidirectional Linear Unit for Recurrent network), which uses forward and backward linear recurrent units (LRUs) to capture both past and future dependencies with high computational efficiency. BLUR maintains the linear time complexity of traditional RNNs, while enabling fast parallel training through LRUs. Furthermore, it offers provably stable training and strong approximation capabilities, making it highly effective for modeling long-term dependencies. Extensive experiments on sequential image and time series datasets reveal that BLUR not only surpasses transformers and traditional RNNs in accuracy but also significantly reduces computational costs, making it particularly suitable for real-world forecasting tasks. Our code is available here.
Enhancing PPO with Trajectory-Aware Hybrid Policies
Feb 21, 2025



Proximal policy optimization (PPO) is one of the most popular state-of-the-art on-policy algorithms that has become a standard baseline in modern reinforcement learning with applications in numerous fields. Though it delivers stable performance with theoretical policy improvement guarantees, high variance, and high sample complexity still remain critical challenges in on-policy algorithms. To alleviate these issues, we propose Hybrid-Policy Proximal Policy Optimization (HP3O), which utilizes a trajectory replay buffer to make efficient use of trajectories generated by recent policies. Particularly, the buffer applies the "first in, first out" (FIFO) strategy so as to keep only the recent trajectories to attenuate the data distribution drift. A batch consisting of the trajectory with the best return and other randomly sampled ones from the buffer is used for updating the policy networks. The strategy helps the agent to improve its capability on top of the most recent best performance and in turn reduce variance empirically. We theoretically construct the policy improvement guarantees for the proposed algorithm. HP3O is validated and compared against several baseline algorithms using multiple continuous control environments. Our code is available here.
RLS3: RL-Based Synthetic Sample Selection to Enhance Spatial Reasoning in Vision-Language Models for Indoor Autonomous Perception
Jan 31, 2025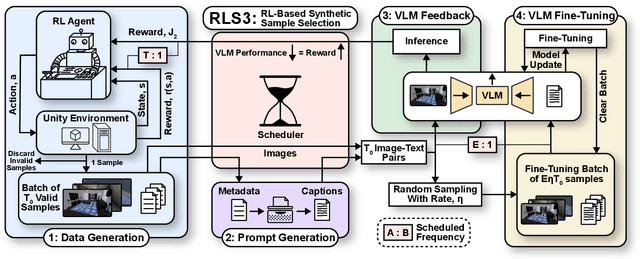
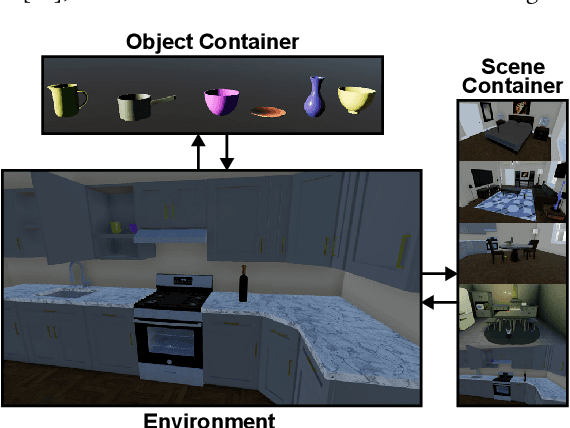
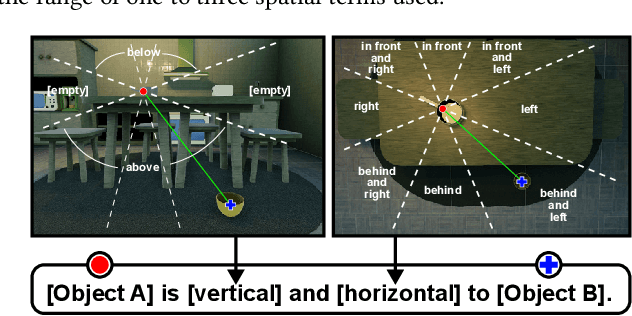
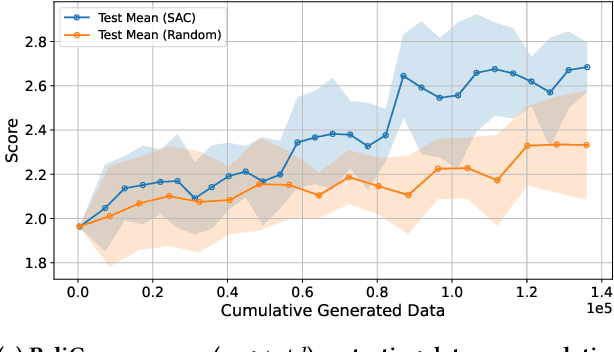
Vision-language model (VLM) fine-tuning for application-specific visual grounding based on natural language instructions has become one of the most popular approaches for learning-enabled autonomous systems. However, such fine-tuning relies heavily on high-quality datasets to achieve successful performance in various downstream tasks. Additionally, VLMs often encounter limitations due to insufficient and imbalanced fine-tuning data. To address these issues, we propose a new generalizable framework to improve VLM fine-tuning by integrating it with a reinforcement learning (RL) agent. Our method utilizes the RL agent to manipulate objects within an indoor setting to create synthetic data for fine-tuning to address certain vulnerabilities of the VLM. Specifically, we use the performance of the VLM to provide feedback to the RL agent to generate informative data that efficiently fine-tune the VLM over the targeted task (e.g. spatial reasoning). The key contribution of this work is developing a framework where the RL agent serves as an informative data sampling tool and assists the VLM in order to enhance performance and address task-specific vulnerabilities. By targeting the data sampling process to address the weaknesses of the VLM, we can effectively train a more context-aware model. In addition, generating synthetic data allows us to have precise control over each scene and generate granular ground truth captions. Our results show that the proposed data generation approach improves the spatial reasoning performance of VLMs, which demonstrates the benefits of using RL-guided data generation in vision-language tasks.
Incorporating System-level Safety Requirements in Perception Models via Reinforcement Learning
Dec 04, 2024



Perception components in autonomous systems are often developed and optimized independently of downstream decision-making and control components, relying on established performance metrics like accuracy, precision, and recall. Traditional loss functions, such as cross-entropy loss and negative log-likelihood, focus on reducing misclassification errors but fail to consider their impact on system-level safety, overlooking the varying severities of system-level failures caused by these errors. To address this limitation, we propose a novel training paradigm that augments the perception component with an understanding of system-level safety objectives. Central to our approach is the translation of system-level safety requirements, formally specified using the rulebook formalism, into safety scores. These scores are then incorporated into the reward function of a reinforcement learning framework for fine-tuning perception models with system-level safety objectives. Simulation results demonstrate that models trained with this approach outperform baseline perception models in terms of system-level safety.
A Deep Learning Approach to Detect Lean Blowout in Combustion Systems
Aug 03, 2022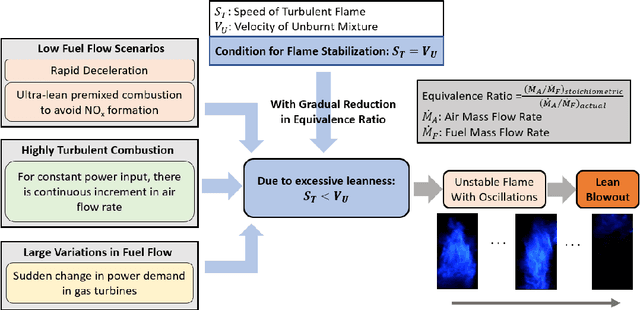
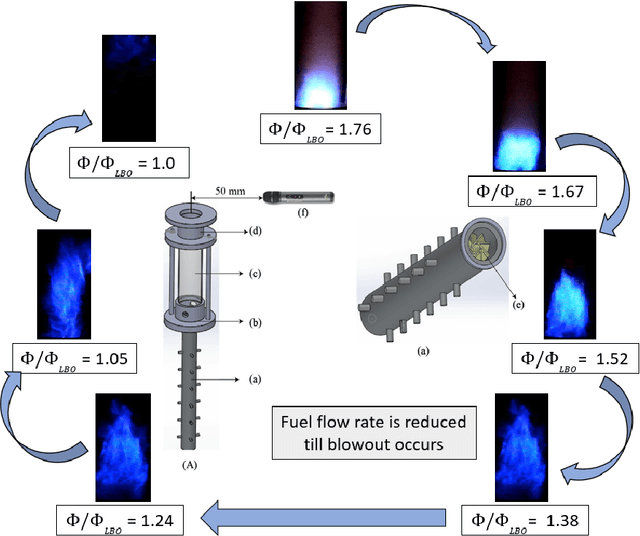
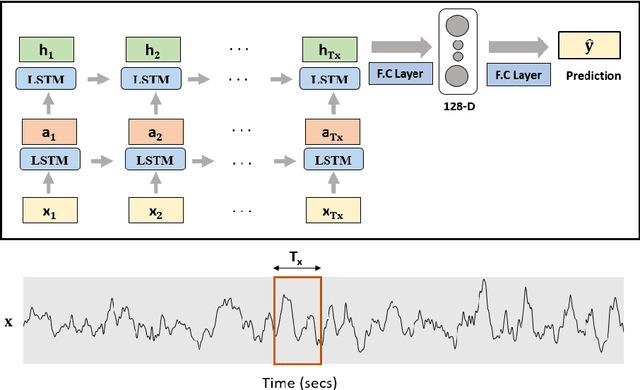
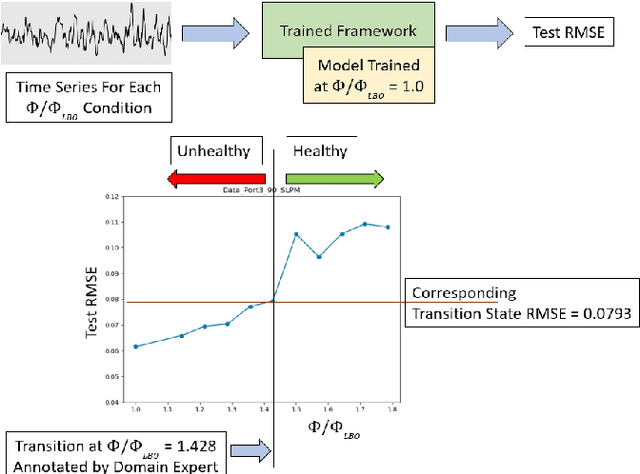
Lean combustion is environment friendly with low NOx emissions and also provides better fuel efficiency in a combustion system. However, approaching towards lean combustion can make engines more susceptible to lean blowout. Lean blowout (LBO) is an undesirable phenomenon that can cause sudden flame extinction leading to sudden loss of power. During the design stage, it is quite challenging for the scientists to accurately determine the optimal operating limits to avoid sudden LBO occurrence. Therefore, it is crucial to develop accurate and computationally tractable frameworks for online LBO detection in low NOx emission engines. To the best of our knowledge, for the first time, we propose a deep learning approach to detect lean blowout in combustion systems. In this work, we utilize a laboratory-scale combustor to collect data for different protocols. We start far from LBO for each protocol and gradually move towards the LBO regime, capturing a quasi-static time series dataset at each condition. Using one of the protocols in our dataset as the reference protocol and with conditions annotated by domain experts, we find a transition state metric for our trained deep learning model to detect LBO in the other test protocols. We find that our proposed approach is more accurate and computationally faster than other baseline models to detect the transitions to LBO. Therefore, we recommend this method for real-time performance monitoring in lean combustion engines.
A modular vision language navigation and manipulation framework for long horizon compositional tasks in indoor environment
Jan 19, 2021
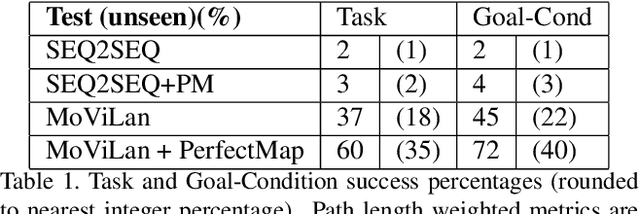
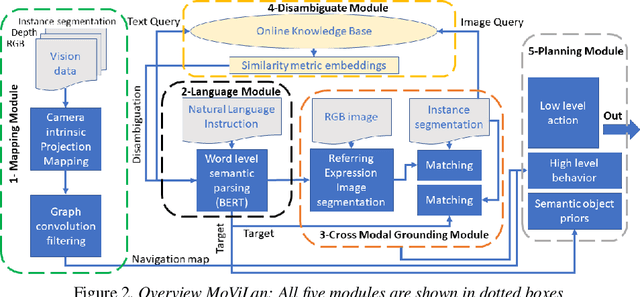
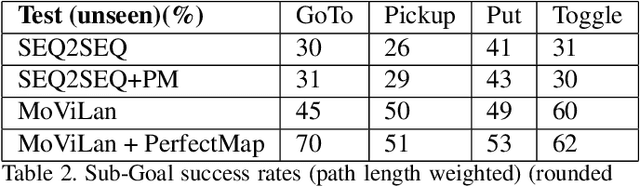
In this paper we propose a new framework - MoViLan (Modular Vision and Language) for execution of visually grounded natural language instructions for day to day indoor household tasks. While several data-driven, end-to-end learning frameworks have been proposed for targeted navigation tasks based on the vision and language modalities, performance on recent benchmark data sets revealed the gap in developing comprehensive techniques for long horizon, compositional tasks (involving manipulation and navigation) with diverse object categories, realistic instructions and visual scenarios with non-reversible state changes. We propose a modular approach to deal with the combined navigation and object interaction problem without the need for strictly aligned vision and language training data (e.g., in the form of expert demonstrated trajectories). Such an approach is a significant departure from the traditional end-to-end techniques in this space and allows for a more tractable training process with separate vision and language data sets. Specifically, we propose a novel geometry-aware mapping technique for cluttered indoor environments, and a language understanding model generalized for household instruction following. We demonstrate a significant increase in success rates for long-horizon, compositional tasks over the baseline on the recently released benchmark data set-ALFRED.