 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBalancing Utility and Privacy: Dynamically Private SGD with Random Projection
Sep 11, 2025Stochastic optimization is a pivotal enabler in modern machine learning, producing effective models for various tasks. However, several existing works have shown that model parameters and gradient information are susceptible to privacy leakage. Although Differentially Private SGD (DPSGD) addresses privacy concerns, its static noise mechanism impacts the error bounds for model performance. Additionally, with the exponential increase in model parameters, efficient learning of these models using stochastic optimizers has become more challenging. To address these concerns, we introduce the Dynamically Differentially Private Projected SGD (D2P2-SGD) optimizer. In D2P2-SGD, we combine two important ideas: (i) dynamic differential privacy (DDP) with automatic gradient clipping and (ii) random projection with SGD, allowing dynamic adjustment of the tradeoff between utility and privacy of the model. It exhibits provably sub-linear convergence rates across different objective functions, matching the best available rate. The theoretical analysis further suggests that DDP leads to better utility at the cost of privacy, while random projection enables more efficient model learning. Extensive experiments across diverse datasets show that D2P2-SGD remarkably enhances accuracy while maintaining privacy. Our code is available here.
Data-driven Kinematic Modeling in Soft Robots: System Identification and Uncertainty Quantification
Jul 10, 2025Precise kinematic modeling is critical in calibration and controller design for soft robots, yet remains a challenging issue due to their highly nonlinear and complex behaviors. To tackle the issue, numerous data-driven machine learning approaches have been proposed for modeling nonlinear dynamics. However, these models suffer from prediction uncertainty that can negatively affect modeling accuracy, and uncertainty quantification for kinematic modeling in soft robots is underexplored. In this work, using limited simulation and real-world data, we first investigate multiple linear and nonlinear machine learning models commonly used for kinematic modeling of soft robots. The results reveal that nonlinear ensemble methods exhibit the most robust generalization performance. We then develop a conformal kinematic modeling framework for soft robots by utilizing split conformal prediction to quantify predictive position uncertainty, ensuring distribution-free prediction intervals with a theoretical guarantee.
DeCAF: Decentralized Consensus-And-Factorization for Low-Rank Adaptation of Foundation Models
May 27, 2025Low-Rank Adaptation (LoRA) has emerged as one of the most effective, computationally tractable fine-tuning approaches for training Vision-Language Models (VLMs) and Large Language Models (LLMs). LoRA accomplishes this by freezing the pre-trained model weights and injecting trainable low-rank matrices, allowing for efficient learning of these foundation models even on edge devices. However, LoRA in decentralized settings still remains under explored, particularly for the theoretical underpinnings due to the lack of smoothness guarantee and model consensus interference (defined formally below). This work improves the convergence rate of decentralized LoRA (DLoRA) to match the rate of decentralized SGD by ensuring gradient smoothness. We also introduce DeCAF, a novel algorithm integrating DLoRA with truncated singular value decomposition (TSVD)-based matrix factorization to resolve consensus interference. Theoretical analysis shows TSVD's approximation error is bounded and consensus differences between DLoRA and DeCAF vanish as rank increases, yielding DeCAF's matching convergence rate. Extensive experiments across vision/language tasks demonstrate our algorithms outperform local training and rivals federated learning under both IID and non-IID data distributions.
Bidirectional Linear Recurrent Models for Sequence-Level Multisource Fusion
Apr 11, 2025Sequence modeling is a critical yet challenging task with wide-ranging applications, especially in time series forecasting for domains like weather prediction, temperature monitoring, and energy load forecasting. Transformers, with their attention mechanism, have emerged as state-of-the-art due to their efficient parallel training, but they suffer from quadratic time complexity, limiting their scalability for long sequences. In contrast, recurrent neural networks (RNNs) offer linear time complexity, spurring renewed interest in linear RNNs for more computationally efficient sequence modeling. In this work, we introduce BLUR (Bidirectional Linear Unit for Recurrent network), which uses forward and backward linear recurrent units (LRUs) to capture both past and future dependencies with high computational efficiency. BLUR maintains the linear time complexity of traditional RNNs, while enabling fast parallel training through LRUs. Furthermore, it offers provably stable training and strong approximation capabilities, making it highly effective for modeling long-term dependencies. Extensive experiments on sequential image and time series datasets reveal that BLUR not only surpasses transformers and traditional RNNs in accuracy but also significantly reduces computational costs, making it particularly suitable for real-world forecasting tasks. Our code is available here.
FUSE: First-Order and Second-Order Unified SynthEsis in Stochastic Optimization
Mar 06, 2025Stochastic optimization methods have actively been playing a critical role in modern machine learning algorithms to deliver decent performance. While numerous works have proposed and developed diverse approaches, first-order and second-order methods are in entirely different situations. The former is significantly pivotal and dominating in emerging deep learning but only leads convergence to a stationary point. However, second-order methods are less popular due to their computational intensity in large-dimensional problems. This paper presents a novel method that leverages both the first-order and second-order methods in a unified algorithmic framework, termed FUSE, from which a practical version (PV) is derived accordingly. FUSE-PV stands as a simple yet efficient optimization method involving a switch-over between first and second orders. Additionally, we develop different criteria that determine when to switch. FUSE-PV has provably shown a smaller computational complexity than SGD and Adam. To validate our proposed scheme, we present an ablation study on several simple test functions and show a comparison with baselines for benchmark datasets.
Enhancing PPO with Trajectory-Aware Hybrid Policies
Feb 21, 2025



Proximal policy optimization (PPO) is one of the most popular state-of-the-art on-policy algorithms that has become a standard baseline in modern reinforcement learning with applications in numerous fields. Though it delivers stable performance with theoretical policy improvement guarantees, high variance, and high sample complexity still remain critical challenges in on-policy algorithms. To alleviate these issues, we propose Hybrid-Policy Proximal Policy Optimization (HP3O), which utilizes a trajectory replay buffer to make efficient use of trajectories generated by recent policies. Particularly, the buffer applies the "first in, first out" (FIFO) strategy so as to keep only the recent trajectories to attenuate the data distribution drift. A batch consisting of the trajectory with the best return and other randomly sampled ones from the buffer is used for updating the policy networks. The strategy helps the agent to improve its capability on top of the most recent best performance and in turn reduce variance empirically. We theoretically construct the policy improvement guarantees for the proposed algorithm. HP3O is validated and compared against several baseline algorithms using multiple continuous control environments. Our code is available here.
RLS3: RL-Based Synthetic Sample Selection to Enhance Spatial Reasoning in Vision-Language Models for Indoor Autonomous Perception
Jan 31, 2025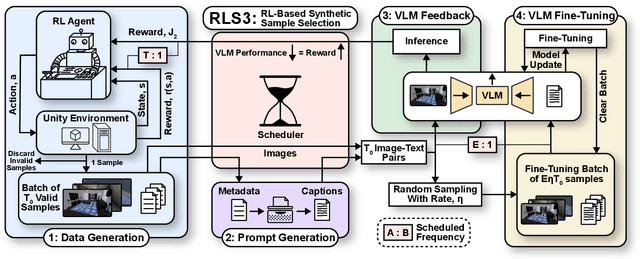
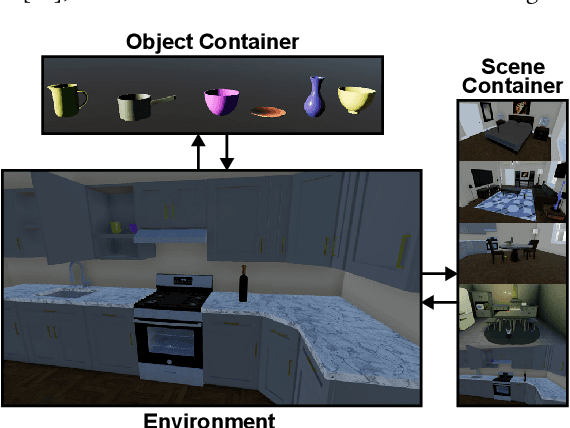
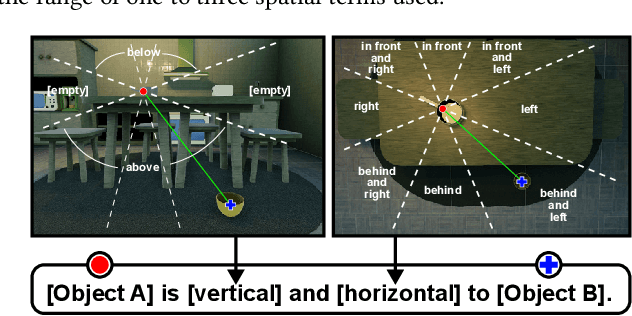
Vision-language model (VLM) fine-tuning for application-specific visual grounding based on natural language instructions has become one of the most popular approaches for learning-enabled autonomous systems. However, such fine-tuning relies heavily on high-quality datasets to achieve successful performance in various downstream tasks. Additionally, VLMs often encounter limitations due to insufficient and imbalanced fine-tuning data. To address these issues, we propose a new generalizable framework to improve VLM fine-tuning by integrating it with a reinforcement learning (RL) agent. Our method utilizes the RL agent to manipulate objects within an indoor setting to create synthetic data for fine-tuning to address certain vulnerabilities of the VLM. Specifically, we use the performance of the VLM to provide feedback to the RL agent to generate informative data that efficiently fine-tune the VLM over the targeted task (e.g. spatial reasoning). The key contribution of this work is developing a framework where the RL agent serves as an informative data sampling tool and assists the VLM in order to enhance performance and address task-specific vulnerabilities. By targeting the data sampling process to address the weaknesses of the VLM, we can effectively train a more context-aware model. In addition, generating synthetic data allows us to have precise control over each scene and generate granular ground truth captions. Our results show that the proposed data generation approach improves the spatial reasoning performance of VLMs, which demonstrates the benefits of using RL-guided data generation in vision-language tasks.
STITCH: Surface reconstrucTion using Implicit neural representations with Topology Constraints and persistent Homology
Dec 24, 2024



We present STITCH, a novel approach for neural implicit surface reconstruction of a sparse and irregularly spaced point cloud while enforcing topological constraints (such as having a single connected component). We develop a new differentiable framework based on persistent homology to formulate topological loss terms that enforce the prior of a single 2-manifold object. Our method demonstrates excellent performance in preserving the topology of complex 3D geometries, evident through both visual and empirical comparisons. We supplement this with a theoretical analysis, and provably show that optimizing the loss with stochastic (sub)gradient descent leads to convergence and enables reconstructing shapes with a single connected component. Our approach showcases the integration of differentiable topological data analysis tools for implicit surface reconstruction.
FAWAC: Feasibility Informed Advantage Weighted Regression for Persistent Safety in Offline Reinforcement Learning
Dec 12, 2024



Safe offline reinforcement learning aims to learn policies that maximize cumulative rewards while adhering to safety constraints, using only offline data for training. A key challenge is balancing safety and performance, particularly when the policy encounters out-of-distribution (OOD) states and actions, which can lead to safety violations or overly conservative behavior during deployment. To address these challenges, we introduce Feasibility Informed Advantage Weighted Actor-Critic (FAWAC), a method that prioritizes persistent safety in constrained Markov decision processes (CMDPs). FAWAC formulates policy optimization with feasibility conditions derived specifically for offline datasets, enabling safe policy updates in non-parametric policy space, followed by projection into parametric space for constrained actor training. By incorporating a cost-advantage term into Advantage Weighted Regression (AWR), FAWAC ensures that the safety constraints are respected while maximizing performance. Additionally, we propose a strategy to address a more challenging class of problems that involves tempting datasets where trajectories are predominantly high-rewarded but unsafe. Empirical evaluations on standard benchmarks demonstrate that FAWAC achieves strong results, effectively balancing safety and performance in learning policies from the static datasets.
Latent Safety-Constrained Policy Approach for Safe Offline Reinforcement Learning
Dec 11, 2024



In safe offline reinforcement learning (RL), the objective is to develop a policy that maximizes cumulative rewards while strictly adhering to safety constraints, utilizing only offline data. Traditional methods often face difficulties in balancing these constraints, leading to either diminished performance or increased safety risks. We address these issues with a novel approach that begins by learning a conservatively safe policy through the use of Conditional Variational Autoencoders, which model the latent safety constraints. Subsequently, we frame this as a Constrained Reward-Return Maximization problem, wherein the policy aims to optimize rewards while complying with the inferred latent safety constraints. This is achieved by training an encoder with a reward-Advantage Weighted Regression objective within the latent constraint space. Our methodology is supported by theoretical analysis, including bounds on policy performance and sample complexity. Extensive empirical evaluation on benchmark datasets, including challenging autonomous driving scenarios, demonstrates that our approach not only maintains safety compliance but also excels in cumulative reward optimization, surpassing existing methods. Additional visualizations provide further insights into the effectiveness and underlying mechanisms of our approach.