 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSciAI4Industry -- Solving PDEs for industry-scale problems with deep learning
Nov 23, 2022



Solving partial differential equations with deep learning makes it possible to reduce simulation times by multiple orders of magnitude and unlock scientific methods that typically rely on large numbers of sequential simulations, such as optimization and uncertainty quantification. Two of the largest challenges of adopting scientific AI for industrial problem settings is that training datasets must be simulated in advance and that neural networks for solving large-scale PDEs exceed the memory capabilities of current GPUs. We introduce a distributed programming API in the Julia language for simulating training data in parallel on the cloud and without requiring users to manage the underlying HPC infrastructure. In addition, we show that model-parallel deep learning based on domain decomposition allows us to scale neural networks for solving PDEs to commercial-scale problem settings and achieve above 90% parallel efficiency. Combining our cloud API for training data generation and model-parallel deep learning, we train large-scale neural networks for solving the 3D Navier-Stokes equation and simulating 3D CO2 flow in porous media. For the CO2 example, we simulate a training dataset based on a commercial carbon capture and storage (CCS) project and train a neural network for CO2 flow simulation on a 3D grid with over 2 million cells that is 5 orders of magnitudes faster than a conventional numerical simulator and 3,200 times cheaper.
Neural PDE Solvers for Irregular Domains
Nov 07, 2022Neural network-based approaches for solving partial differential equations (PDEs) have recently received special attention. However, the large majority of neural PDE solvers only apply to rectilinear domains, and do not systematically address the imposition of Dirichlet/Neumann boundary conditions over irregular domain boundaries. In this paper, we present a framework to neurally solve partial differential equations over domains with irregularly shaped (non-rectilinear) geometric boundaries. Our network takes in the shape of the domain as an input (represented using an unstructured point cloud, or any other parametric representation such as Non-Uniform Rational B-Splines) and is able to generalize to novel (unseen) irregular domains; the key technical ingredient to realizing this model is a novel approach for identifying the interior and exterior of the computational grid in a differentiable manner. We also perform a careful error analysis which reveals theoretical insights into several sources of error incurred in the model-building process. Finally, we showcase a wide variety of applications, along with favorable comparisons with ground truth solutions.
NFDLM: A Lightweight Network Flow based Deep Learning Model for DDoS Attack Detection in IoT Domains
Jul 15, 2022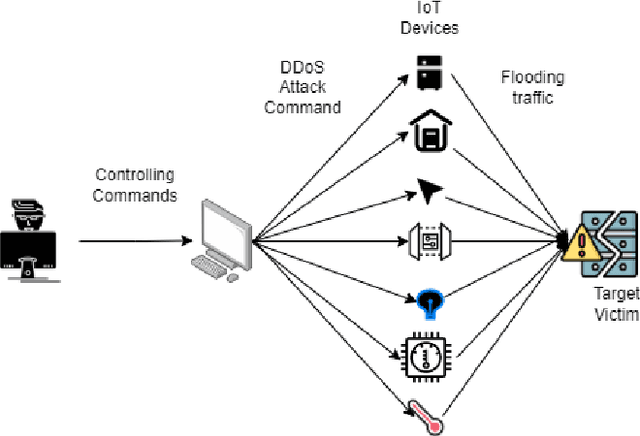
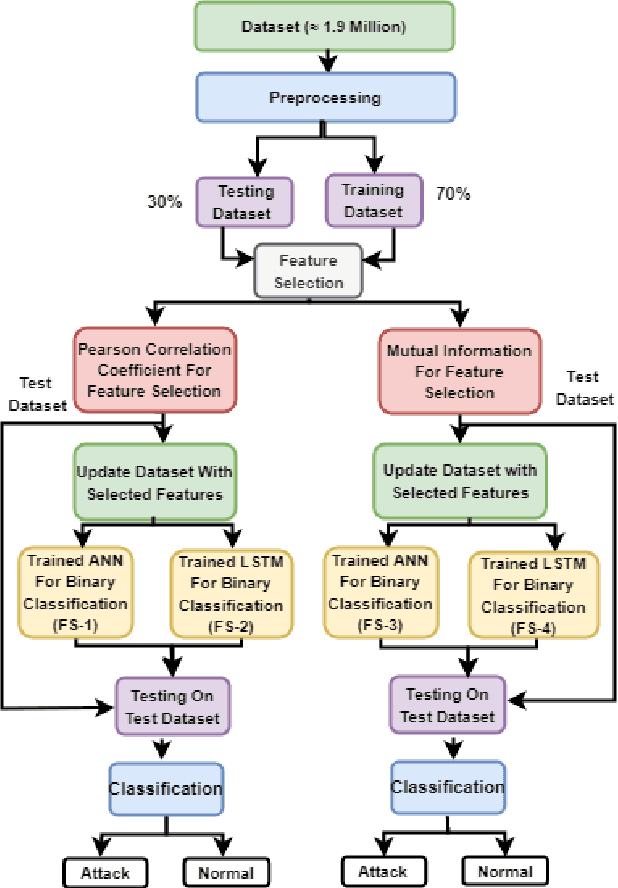
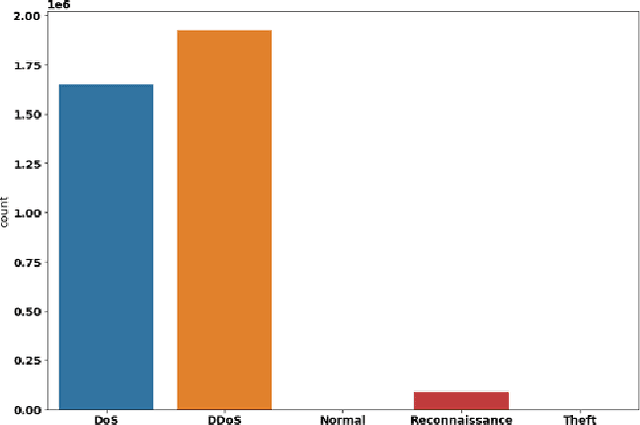
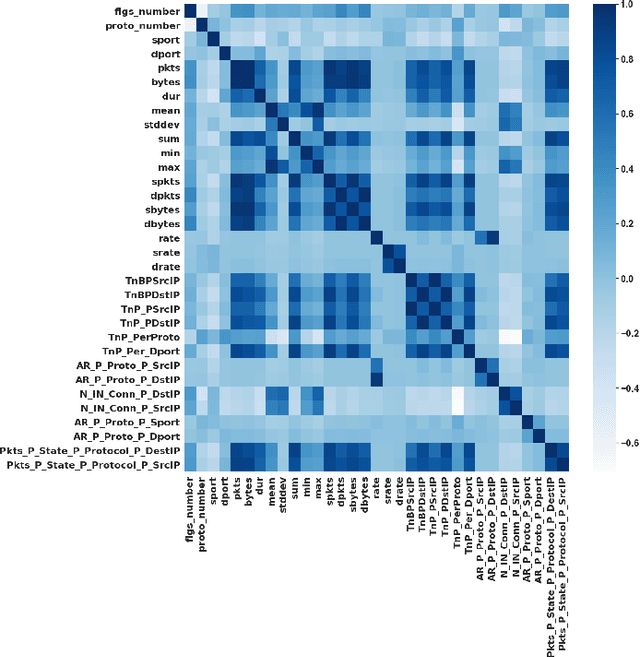
In the recent years, Distributed Denial of Service (DDoS) attacks on Internet of Things (IoT) devices have become one of the prime concerns to Internet users around the world. One of the sources of the attacks on IoT ecosystems are botnets. Intruders force IoT devices to become unavailable for its legitimate users by sending large number of messages within a short interval. This study proposes NFDLM, a lightweight and optimised Artificial Neural Network (ANN) based Distributed Denial of Services (DDoS) attack detection framework with mutual correlation as feature selection method which produces a superior result when compared with Long Short Term Memory (LSTM) and simple ANN. Overall, the detection performance achieves approximately 99\% accuracy for the detection of attacks from botnets. In this work, we have designed and compared four different models where two are based on ANN and the other two are based on LSTM to detect the attack types of DDoS.
LBDMIDS: LSTM Based Deep Learning Model for Intrusion Detection Systems for IoT Networks
Jun 23, 2022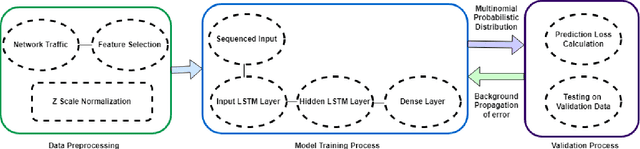
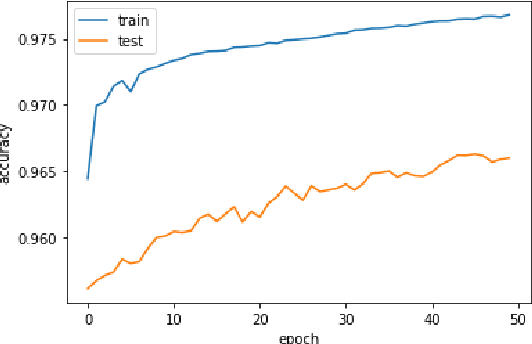
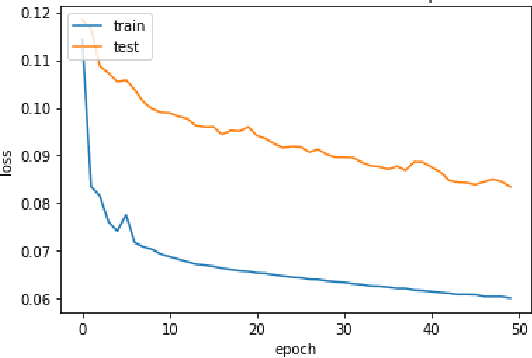

In the recent years, we have witnessed a huge growth in the number of Internet of Things (IoT) and edge devices being used in our everyday activities. This demands the security of these devices from cyber attacks to be improved to protect its users. For years, Machine Learning (ML) techniques have been used to develop Network Intrusion Detection Systems (NIDS) with the aim of increasing their reliability/robustness. Among the earlier ML techniques DT performed well. In the recent years, Deep Learning (DL) techniques have been used in an attempt to build more reliable systems. In this paper, a Deep Learning enabled Long Short Term Memory (LSTM) Autoencoder and a 13-feature Deep Neural Network (DNN) models were developed which performed a lot better in terms of accuracy on UNSW-NB15 and Bot-IoT datsets. Hence we proposed LBDMIDS, where we developed NIDS models based on variants of LSTMs namely, stacked LSTM and bidirectional LSTM and validated their performance on the UNSW\_NB15 and BoT\-IoT datasets. This paper concludes that these variants in LBDMIDS outperform classic ML techniques and perform similarly to the DNN models that have been suggested in the past.
Terrain Classification using Transfer Learning on Hyperspectral Images: A Comparative study
Jun 19, 2022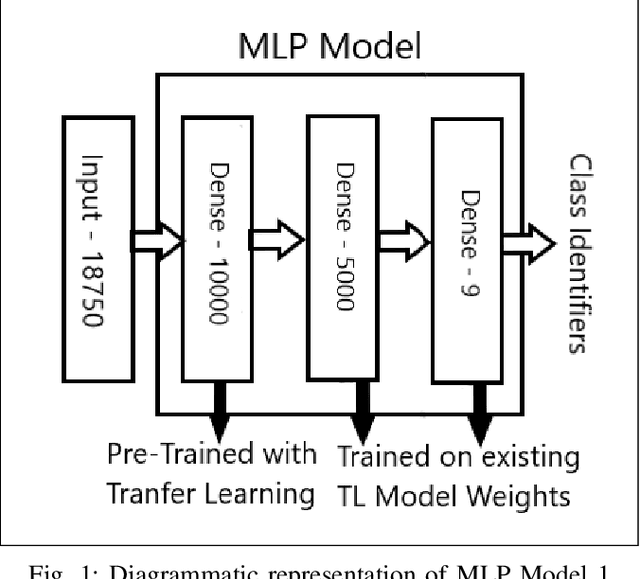


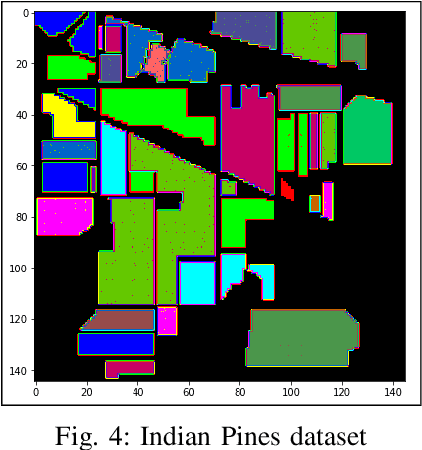
A Hyperspectral image contains much more number of channels as compared to a RGB image, hence containing more information about entities within the image. The convolutional neural network (CNN) and the Multi-Layer Perceptron (MLP) have been proven to be an effective method of image classification. However, they suffer from the issues of long training time and requirement of large amounts of the labeled data, to achieve the expected outcome. These issues become more complex while dealing with hyperspectral images. To decrease the training time and reduce the dependence on large labeled dataset, we propose using the method of transfer learning. The hyperspectral dataset is preprocessed to a lower dimension using PCA, then deep learning models are applied to it for the purpose of classification. The features learned by this model are then used by the transfer learning model to solve a new classification problem on an unseen dataset. A detailed comparison of CNN and multiple MLP architectural models is performed, to determine an optimum architecture that suits best the objective. The results show that the scaling of layers not always leads to increase in accuracy but often leads to overfitting, and also an increase in the training time.The training time is reduced to greater extent by applying the transfer learning approach rather than just approaching the problem by directly training a new model on large datasets, without much affecting the accuracy.