 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDistributed Online Non-convex Optimization with Composite Regret
Sep 21, 2022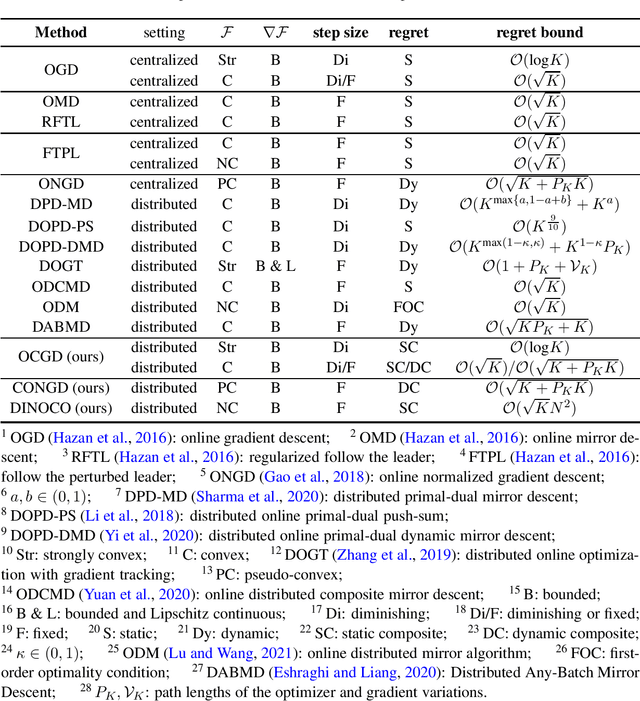
Regret has been widely adopted as the metric of choice for evaluating the performance of online optimization algorithms for distributed, multi-agent systems. However, data/model variations associated with agents can significantly impact decisions and requires consensus among agents. Moreover, most existing works have focused on developing approaches for (either strongly or non-strongly) convex losses, and very few results have been obtained regarding regret bounds in distributed online optimization for general non-convex losses. To address these two issues, we propose a novel composite regret with a new network regret-based metric to evaluate distributed online optimization algorithms. We concretely define static and dynamic forms of the composite regret. By leveraging the dynamic form of our composite regret, we develop a consensus-based online normalized gradient (CONGD) approach for pseudo-convex losses, and it provably shows a sublinear behavior relating to a regularity term for the path variation of the optimizer. For general non-convex losses, we first shed light on the regret for the setting of distributed online non-convex learning based on recent advances such that no deterministic algorithm can achieve the sublinear regret. We then develop the distributed online non-convex optimization with composite regret (DINOCO) without access to the gradients, depending on an offline optimization oracle. DINOCO is shown to achieve sublinear regret; to our knowledge, this is the first regret bound for general distributed online non-convex learning.
Asynchronous Training Schemes in Distributed Learning with Time Delay
Aug 28, 2022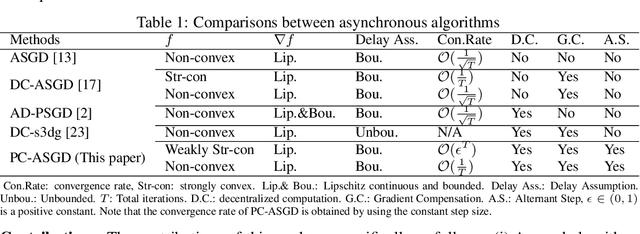
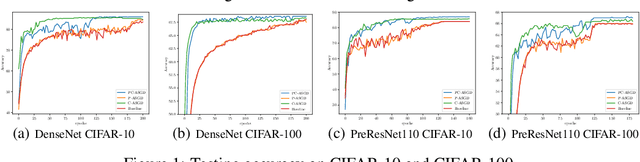

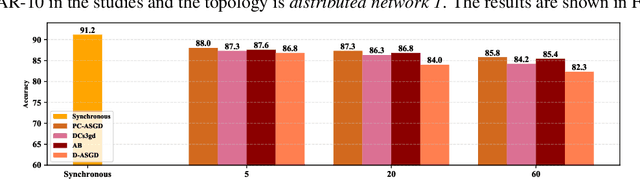
In the context of distributed deep learning, the issue of stale weights or gradients could result in poor algorithmic performance. This issue is usually tackled by delay tolerant algorithms with some mild assumptions on the objective functions and step sizes. In this paper, we propose a different approach to develop a new algorithm, called $\textbf{P}$redicting $\textbf{C}$lipping $\textbf{A}$synchronous $\textbf{S}$tochastic $\textbf{G}$radient $\textbf{D}$escent (aka, PC-ASGD). Specifically, PC-ASGD has two steps - the $\textit{predicting step}$ leverages the gradient prediction using Taylor expansion to reduce the staleness of the outdated weights while the $\textit{clipping step}$ selectively drops the outdated weights to alleviate their negative effects. A tradeoff parameter is introduced to balance the effects between these two steps. Theoretically, we present the convergence rate considering the effects of delay of the proposed algorithm with constant step size when the smooth objective functions are weakly strongly-convex and nonconvex. One practical variant of PC-ASGD is also proposed by adopting a condition to help with the determination of the tradeoff parameter. For empirical validation, we demonstrate the performance of the algorithm with two deep neural network architectures on two benchmark datasets.
MDPGT: Momentum-based Decentralized Policy Gradient Tracking
Dec 06, 2021
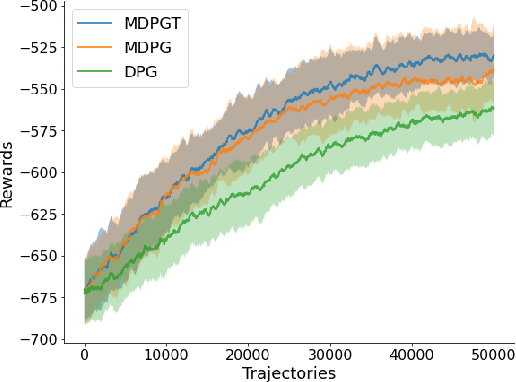
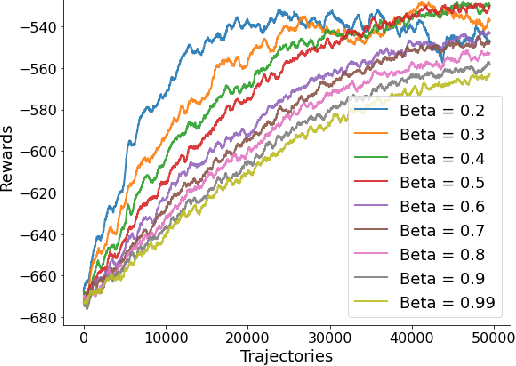
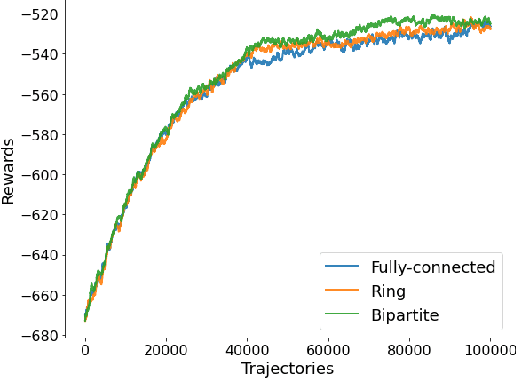
We propose a novel policy gradient method for multi-agent reinforcement learning, which leverages two different variance-reduction techniques and does not require large batches over iterations. Specifically, we propose a momentum-based decentralized policy gradient tracking (MDPGT) where a new momentum-based variance reduction technique is used to approximate the local policy gradient surrogate with importance sampling, and an intermediate parameter is adopted to track two consecutive policy gradient surrogates. Moreover, MDPGT provably achieves the best available sample complexity of $\mathcal{O}(N^{-1}\epsilon^{-3})$ for converging to an $\epsilon$-stationary point of the global average of $N$ local performance functions (possibly nonconcave). This outperforms the state-of-the-art sample complexity in decentralized model-free reinforcement learning, and when initialized with a single trajectory, the sample complexity matches those obtained by the existing decentralized policy gradient methods. We further validate the theoretical claim for the Gaussian policy function. When the required error tolerance $\epsilon$ is small enough, MDPGT leads to a linear speed up, which has been previously established in decentralized stochastic optimization, but not for reinforcement learning. Lastly, we provide empirical results on a multi-agent reinforcement learning benchmark environment to support our theoretical findings.
Deep Transfer Learning for Thermal Dynamics Modeling in Smart Buildings
Nov 08, 2019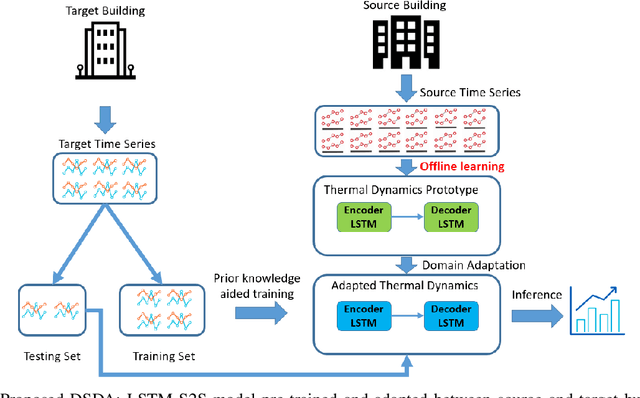
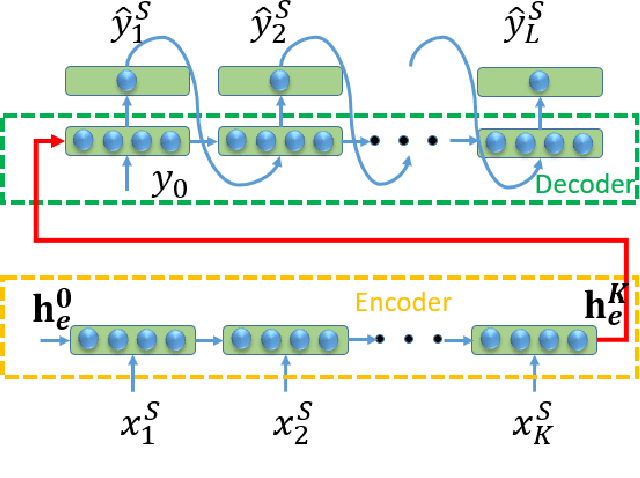
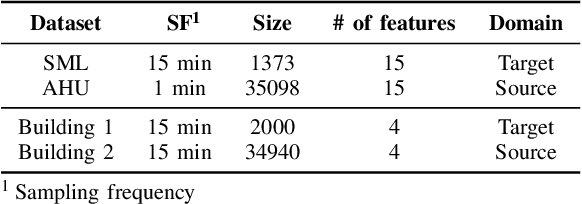
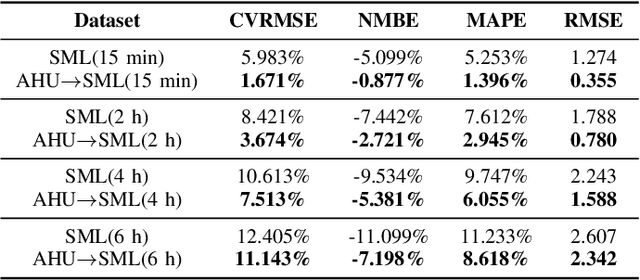
Thermal dynamics modeling has been a critical issue in building heating, ventilation, and air-conditioning (HVAC) systems, which can significantly affect the control and maintenance strategies. Due to the uniqueness of each specific building, traditional thermal dynamics modeling approaches heavily depending on physics knowledge cannot generalize well. This study proposes a deep supervised domain adaptation (DSDA) method for thermal dynamics modeling of building indoor temperature evolution and energy consumption. A long short term memory network based Sequence to Sequence scheme is pre-trained based on a large amount of data collected from a building and then adapted to another building which has a limited amount of data by applying the model fine-tuning. We use four publicly available datasets: SML and AHU for temperature evolution, long-term datasets from two different commercial buildings, termed as Building 1 and Building 2 for energy consumption. We show that the deep supervised domain adaptation is effective to adapt the pre-trained model from one building to another building and has better predictive performance than learning from scratch with only a limited amount of data.