 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Agent Decision Transformers for Dynamic Dispatching in Material Handling Systems Leveraging Enterprise Big Data
Nov 04, 2024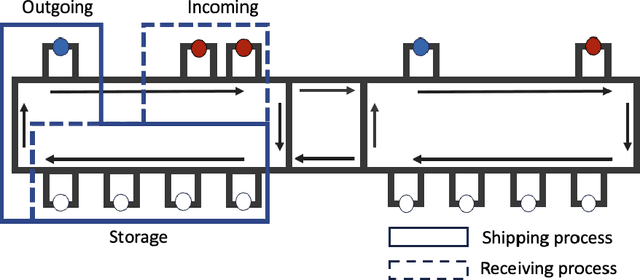

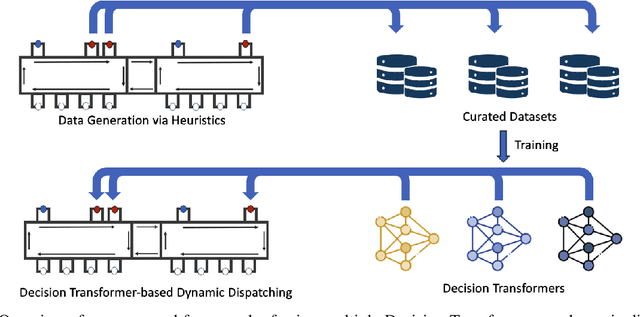
Dynamic dispatching rules that allocate resources to tasks in real-time play a critical role in ensuring efficient operations of many automated material handling systems across industries. Traditionally, the dispatching rules deployed are typically the result of manually crafted heuristics based on domain experts' knowledge. Generating these rules is time-consuming and often sub-optimal. As enterprises increasingly accumulate vast amounts of operational data, there is significant potential to leverage this big data to enhance the performance of automated systems. One promising approach is to use Decision Transformers, which can be trained on existing enterprise data to learn better dynamic dispatching rules for improving system throughput. In this work, we study the application of Decision Transformers as dynamic dispatching policies within an actual multi-agent material handling system and identify scenarios where enterprises can effectively leverage Decision Transformers on existing big data to gain business value. Our empirical results demonstrate that Decision Transformers can improve the material handling system's throughput by a considerable amount when the heuristic originally used in the enterprise data exhibits moderate performance and involves no randomness. When the original heuristic has strong performance, Decision Transformers can still improve the throughput but with a smaller improvement margin. However, when the original heuristics contain an element of randomness or when the performance of the dataset is below a certain threshold, Decision Transformers fail to outperform the original heuristic. These results highlight both the potential and limitations of Decision Transformers as dispatching policies for automated industrial material handling systems.
An ensemble of convolution-based methods for fault detection using vibration signals
May 05, 2023
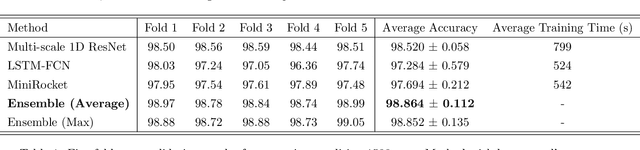
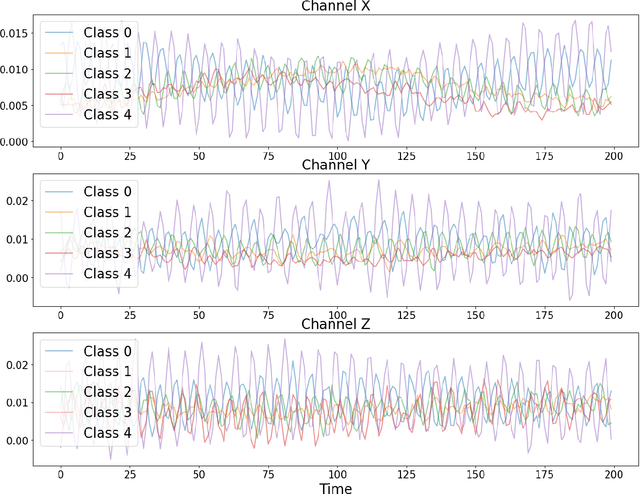
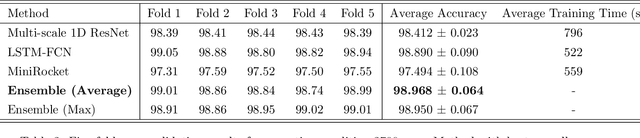
This paper focuses on solving a fault detection problem using multivariate time series of vibration signals collected from planetary gearboxes in a test rig. Various traditional machine learning and deep learning methods have been proposed for multivariate time-series classification, including distance-based, functional data-oriented, feature-driven, and convolution kernel-based methods. Recent studies have shown using convolution kernel-based methods like ROCKET, and 1D convolutional neural networks with ResNet and FCN, have robust performance for multivariate time-series data classification. We propose an ensemble of three convolution kernel-based methods and show its efficacy on this fault detection problem by outperforming other approaches and achieving an accuracy of more than 98.8\%.
Distributed Online Non-convex Optimization with Composite Regret
Sep 21, 2022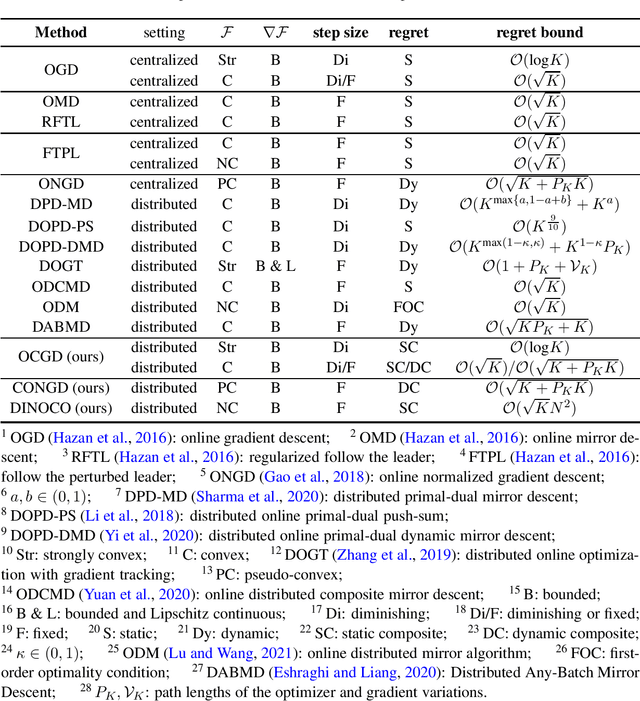
Regret has been widely adopted as the metric of choice for evaluating the performance of online optimization algorithms for distributed, multi-agent systems. However, data/model variations associated with agents can significantly impact decisions and requires consensus among agents. Moreover, most existing works have focused on developing approaches for (either strongly or non-strongly) convex losses, and very few results have been obtained regarding regret bounds in distributed online optimization for general non-convex losses. To address these two issues, we propose a novel composite regret with a new network regret-based metric to evaluate distributed online optimization algorithms. We concretely define static and dynamic forms of the composite regret. By leveraging the dynamic form of our composite regret, we develop a consensus-based online normalized gradient (CONGD) approach for pseudo-convex losses, and it provably shows a sublinear behavior relating to a regularity term for the path variation of the optimizer. For general non-convex losses, we first shed light on the regret for the setting of distributed online non-convex learning based on recent advances such that no deterministic algorithm can achieve the sublinear regret. We then develop the distributed online non-convex optimization with composite regret (DINOCO) without access to the gradients, depending on an offline optimization oracle. DINOCO is shown to achieve sublinear regret; to our knowledge, this is the first regret bound for general distributed online non-convex learning.
Stochastic Conservative Contextual Linear Bandits
Mar 29, 2022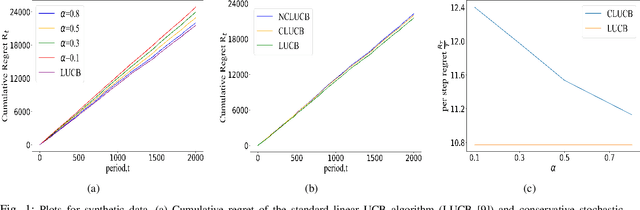
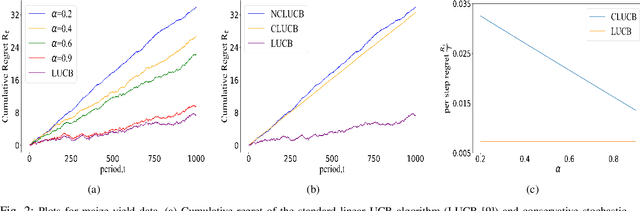
Many physical systems have underlying safety considerations that require that the strategy deployed ensures the satisfaction of a set of constraints. Further, often we have only partial information on the state of the system. We study the problem of safe real-time decision making under uncertainty. In this paper, we formulate a conservative stochastic contextual bandit formulation for real-time decision making when an adversary chooses a distribution on the set of possible contexts and the learner is subject to certain safety/performance constraints. The learner observes only the context distribution and the exact context is unknown, and the goal is to develop an algorithm that selects a sequence of optimal actions to maximize the cumulative reward without violating the safety constraints at any time step. By leveraging the UCB algorithm for this setting, we propose a conservative linear UCB algorithm for stochastic bandits with context distribution. We prove an upper bound on the regret of the algorithm and show that it can be decomposed into three terms: (i) an upper bound for the regret of the standard linear UCB algorithm, (ii) a constant term (independent of time horizon) that accounts for the loss of being conservative in order to satisfy the safety constraint, and (ii) a constant term (independent of time horizon) that accounts for the loss for the contexts being unknown and only the distribution being known. To validate the performance of our approach we perform extensive simulations on synthetic data and on real-world maize data collected through the Genomes to Fields (G2F) initiative.
MDPGT: Momentum-based Decentralized Policy Gradient Tracking
Dec 06, 2021
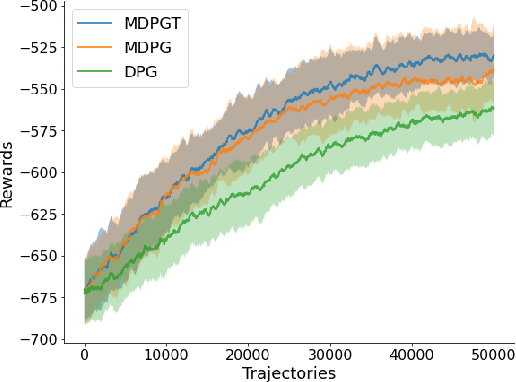
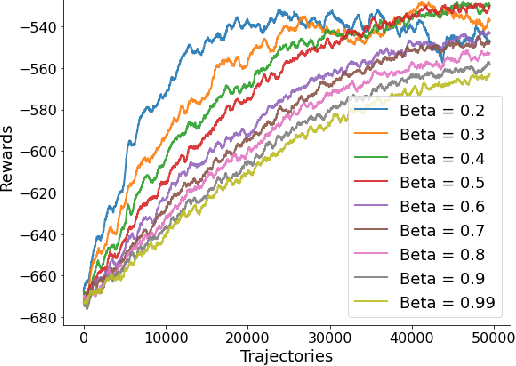
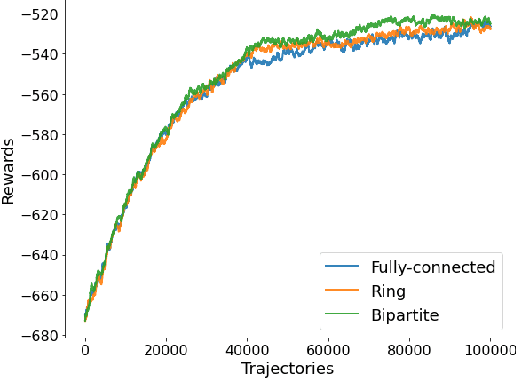
We propose a novel policy gradient method for multi-agent reinforcement learning, which leverages two different variance-reduction techniques and does not require large batches over iterations. Specifically, we propose a momentum-based decentralized policy gradient tracking (MDPGT) where a new momentum-based variance reduction technique is used to approximate the local policy gradient surrogate with importance sampling, and an intermediate parameter is adopted to track two consecutive policy gradient surrogates. Moreover, MDPGT provably achieves the best available sample complexity of $\mathcal{O}(N^{-1}\epsilon^{-3})$ for converging to an $\epsilon$-stationary point of the global average of $N$ local performance functions (possibly nonconcave). This outperforms the state-of-the-art sample complexity in decentralized model-free reinforcement learning, and when initialized with a single trajectory, the sample complexity matches those obtained by the existing decentralized policy gradient methods. We further validate the theoretical claim for the Gaussian policy function. When the required error tolerance $\epsilon$ is small enough, MDPGT leads to a linear speed up, which has been previously established in decentralized stochastic optimization, but not for reinforcement learning. Lastly, we provide empirical results on a multi-agent reinforcement learning benchmark environment to support our theoretical findings.
A Graph Policy Network Approach for Volt-Var Control in Power Distribution Systems
Sep 24, 2021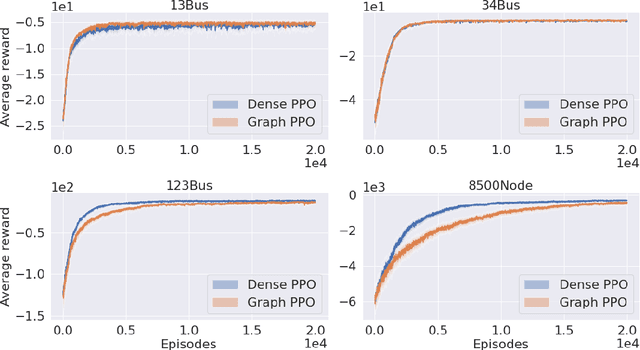
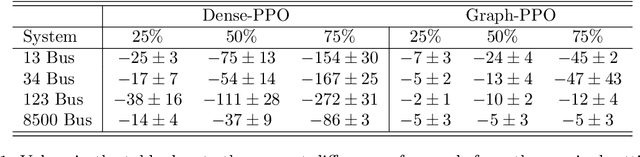
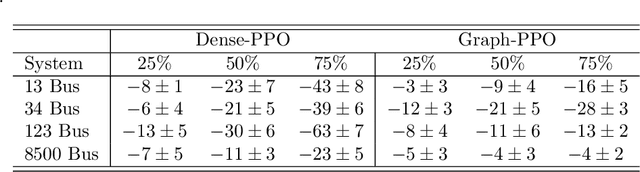
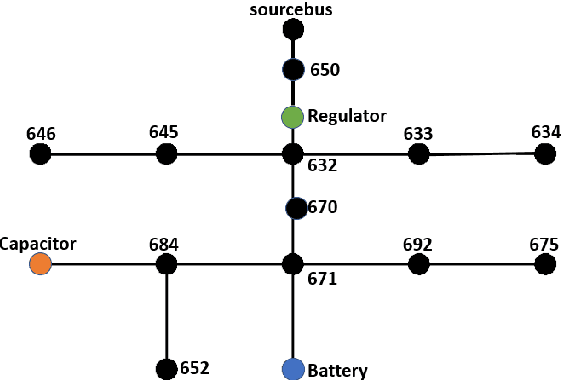
Volt-var control (VVC) is the problem of operating power distribution systems within healthy regimes by controlling actuators in power systems. Existing works have mostly adopted the conventional routine of representing the power systems (a graph with tree topology) as vectors to train deep reinforcement learning (RL) policies. We propose a framework that combines RL with graph neural networks and study the benefits and limitations of graph-based policy in the VVC setting. Our results show that graph-based policies converge to the same rewards asymptotically however at a slower rate when compared to vector representation counterpart. We conduct further analysis on the impact of both observations and actions: on the observation end, we examine the robustness of graph-based policy on two typical data acquisition errors in power systems, namely sensor communication failure and measurement misalignment. On the action end, we show that actuators have various impacts on the system, thus using a graph representation induced by power systems topology may not be the optimal choice. In the end, we conduct a case study to demonstrate that the choice of readout function architecture and graph augmentation can further improve training performance and robustness.
PowerGym: A Reinforcement Learning Environment for Volt-Var Control in Power Distribution Systems
Sep 20, 2021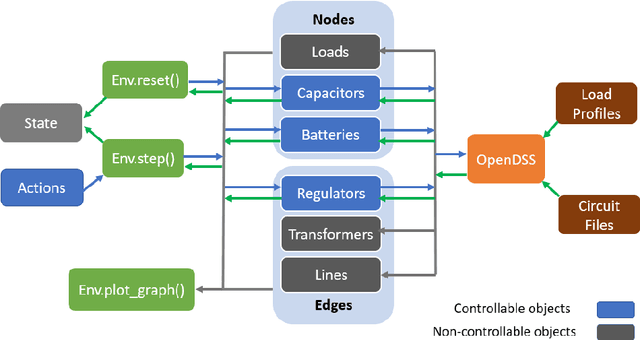
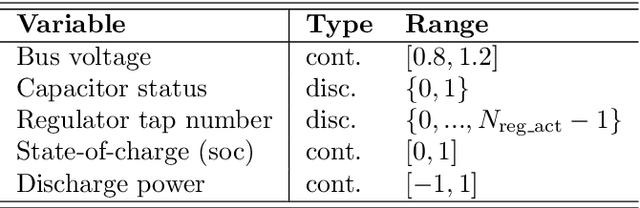

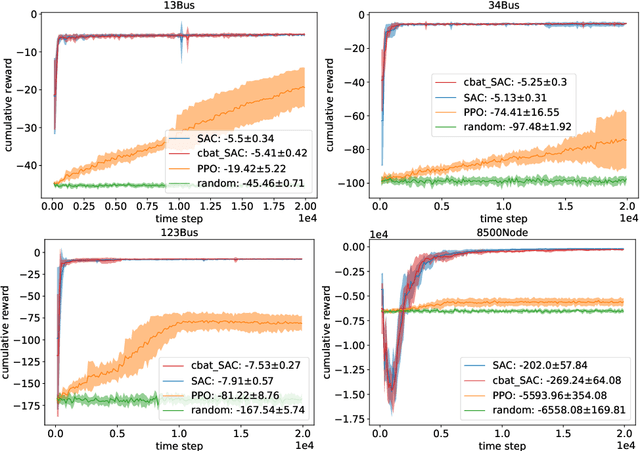
We introduce PowerGym, an open-source reinforcement learning environment for Volt-Var control in power distribution systems. Following OpenAI Gym APIs, PowerGym targets minimizing power loss and voltage violations under physical networked constraints. PowerGym provides four distribution systems (13Bus, 34Bus, 123Bus, and 8500Node) based on IEEE benchmark systems and design variants for various control difficulties. To foster generalization, PowerGym offers a detailed customization guide for users working with their distribution systems. As a demonstration, we examine state-of-the-art reinforcement learning algorithms in PowerGym and validate the environment by studying controller behaviors. The repository is available at \url{https://github.com/siemens/powergym}.
Query-based Targeted Action-Space Adversarial Policies on Deep Reinforcement Learning Agents
Nov 13, 2020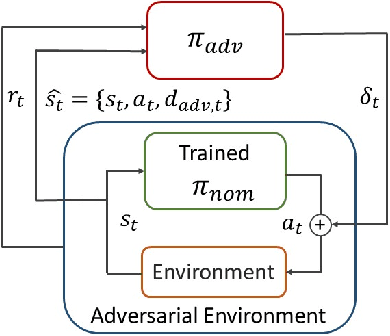
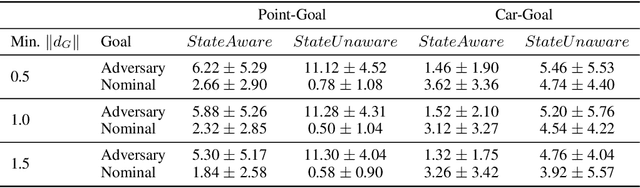
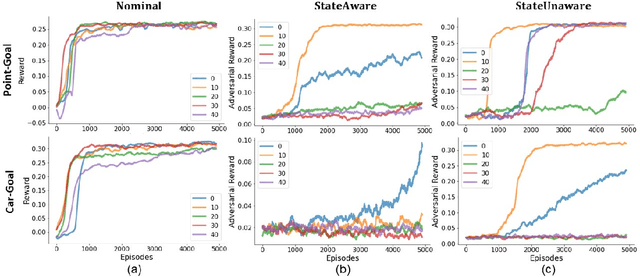
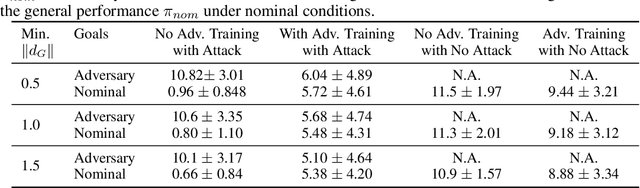
Advances in computing resources have resulted in the increasing complexity of cyber-physical systems (CPS). As the complexity of CPS evolved, the focus has shifted from traditional control methods to deep reinforcement learning-based (DRL) methods for control of these systems. This is due to the difficulty of obtaining accurate models of complex CPS for traditional control. However, to securely deploy DRL in production, it is essential to examine the weaknesses of DRL-based controllers (policies) towards malicious attacks from all angles. In this work, we investigate targeted attacks in the action-space domain, also commonly known as actuation attacks in CPS literature, which perturbs the outputs of a controller. We show that a query-based black-box attack model that generates optimal perturbations with respect to an adversarial goal can be formulated as another reinforcement learning problem. Thus, such an adversarial policy can be trained using conventional DRL methods. Experimental results showed that adversarial policies that only observe the nominal policy's output generate stronger attacks than adversarial policies that observe the nominal policy's input and output. Further analysis reveals that nominal policies whose outputs are frequently at the boundaries of the action space are naturally more robust towards adversarial policies. Lastly, we propose the use of adversarial training with transfer learning to induce robust behaviors into the nominal policy, which decreases the rate of successful targeted attacks by half.
Robustifying Reinforcement Learning Agents via Action Space Adversarial Training
Jul 14, 2020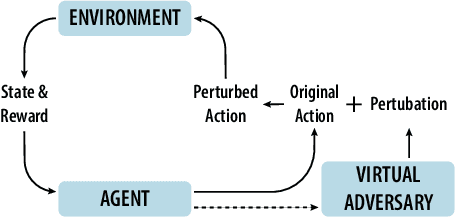
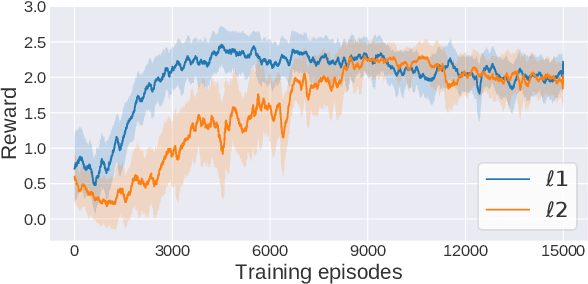
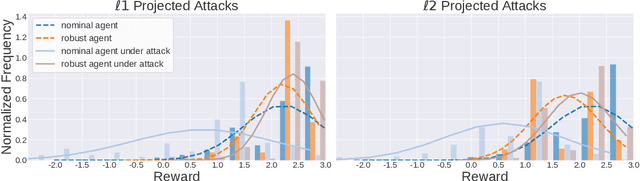
Adoption of machine learning (ML)-enabled cyber-physical systems (CPS) are becoming prevalent in various sectors of modern society such as transportation, industrial, and power grids. Recent studies in deep reinforcement learning (DRL) have demonstrated its benefits in a large variety of data-driven decisions and control applications. As reliance on ML-enabled systems grows, it is imperative to study the performance of these systems under malicious state and actuator attacks. Traditional control systems employ resilient/fault-tolerant controllers that counter these attacks by correcting the system via error observations. However, in some applications, a resilient controller may not be sufficient to avoid a catastrophic failure. Ideally, a robust approach is more useful in these scenarios where a system is inherently robust (by design) to adversarial attacks. While robust control has a long history of development, robust ML is an emerging research area that has already demonstrated its relevance and urgency. However, the majority of robust ML research has focused on perception tasks and not on decision and control tasks, although the ML (specifically RL) models used for control applications are equally vulnerable to adversarial attacks. In this paper, we show that a well-performing DRL agent that is initially susceptible to action space perturbations (e.g. actuator attacks) can be robustified against similar perturbations through adversarial training.
Spatiotemporally Constrained Action Space Attacks on Deep Reinforcement Learning Agents
Sep 05, 2019
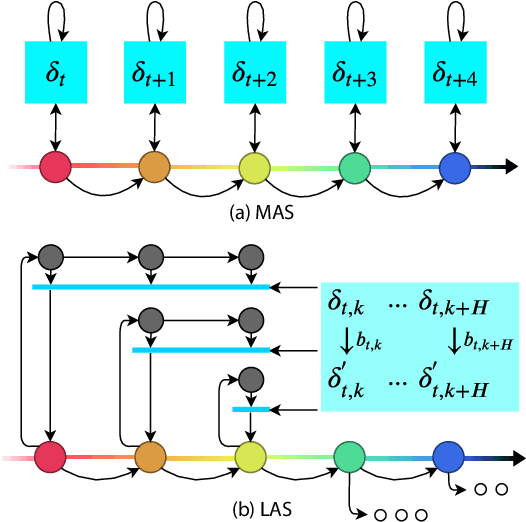
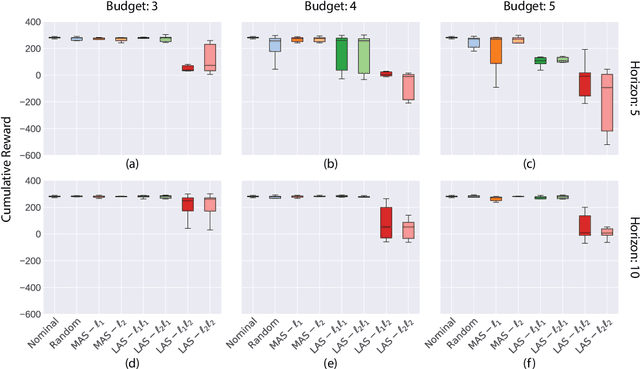
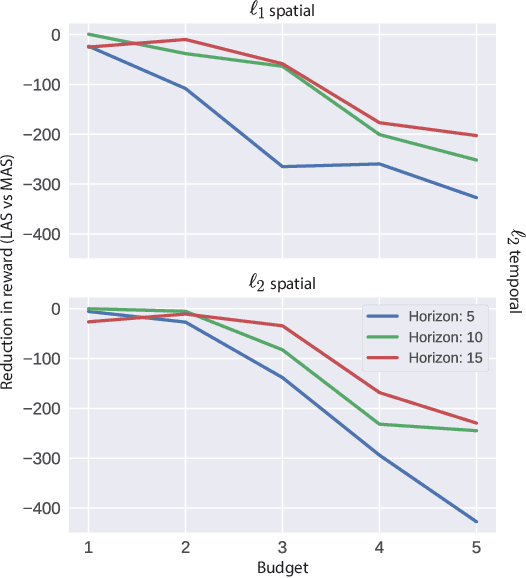
Robustness of Deep Reinforcement Learning (DRL) algorithms towards adversarial attacks in real world applications such as those deployed in cyber-physical systems (CPS) are of increasing concern. Numerous studies have investigated the mechanisms of attacks on the RL agent's state space. Nonetheless, attacks on the RL agent's action space (AS) (corresponding to actuators in engineering systems) are equally perverse; such attacks are relatively less studied in the ML literature. In this work, we first frame the problem as an optimization problem of minimizing the cumulative reward of an RL agent with decoupled constraints as the budget of attack. We propose a white-box Myopic Action Space (MAS) attack algorithm that distributes the attacks across the action space dimensions. Next, we reformulate the optimization problem above with the same objective function, but with a temporally coupled constraint on the attack budget to take into account the approximated dynamics of the agent. This leads to the white-box Look-ahead Action Space (LAS) attack algorithm that distributes the attacks across the action and temporal dimensions. Our results shows that using the same amount of resources, the LAS attack deteriorates the agent's performance significantly more than the MAS attack. This reveals the possibility that with limited resource, an adversary can utilize the agent's dynamics to malevolently craft attacks that causes the agent to fail. Additionally, we leverage these attack strategies as a possible tool to gain insights on the potential vulnerabilities of DRL agents.