 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeActive shooter detection and robust tracking utilizing supplemental synthetic data
Sep 06, 2023



The increasing concern surrounding gun violence in the United States has led to a focus on developing systems to improve public safety. One approach to developing such a system is to detect and track shooters, which would help prevent or mitigate the impact of violent incidents. In this paper, we proposed detecting shooters as a whole, rather than just guns, which would allow for improved tracking robustness, as obscuring the gun would no longer cause the system to lose sight of the threat. However, publicly available data on shooters is much more limited and challenging to create than a gun dataset alone. Therefore, we explore the use of domain randomization and transfer learning to improve the effectiveness of training with synthetic data obtained from Unreal Engine environments. This enables the model to be trained on a wider range of data, increasing its ability to generalize to different situations. Using these techniques with YOLOv8 and Deep OC-SORT, we implemented an initial version of a shooter tracking system capable of running on edge hardware, including both a Raspberry Pi and a Jetson Nano.
MDPGT: Momentum-based Decentralized Policy Gradient Tracking
Dec 06, 2021
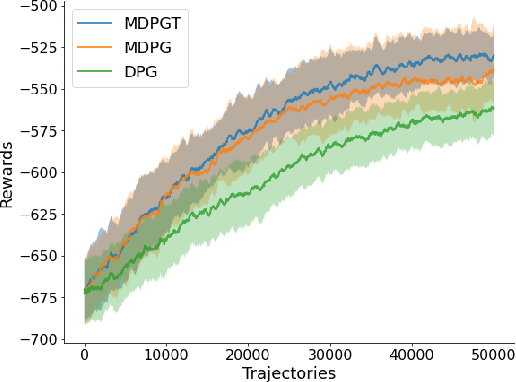
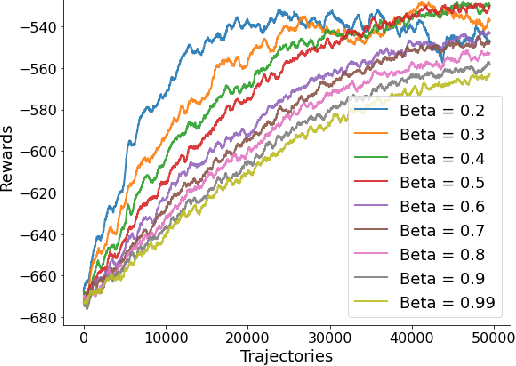
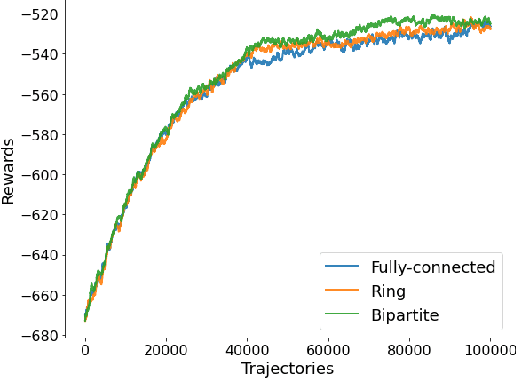
We propose a novel policy gradient method for multi-agent reinforcement learning, which leverages two different variance-reduction techniques and does not require large batches over iterations. Specifically, we propose a momentum-based decentralized policy gradient tracking (MDPGT) where a new momentum-based variance reduction technique is used to approximate the local policy gradient surrogate with importance sampling, and an intermediate parameter is adopted to track two consecutive policy gradient surrogates. Moreover, MDPGT provably achieves the best available sample complexity of $\mathcal{O}(N^{-1}\epsilon^{-3})$ for converging to an $\epsilon$-stationary point of the global average of $N$ local performance functions (possibly nonconcave). This outperforms the state-of-the-art sample complexity in decentralized model-free reinforcement learning, and when initialized with a single trajectory, the sample complexity matches those obtained by the existing decentralized policy gradient methods. We further validate the theoretical claim for the Gaussian policy function. When the required error tolerance $\epsilon$ is small enough, MDPGT leads to a linear speed up, which has been previously established in decentralized stochastic optimization, but not for reinforcement learning. Lastly, we provide empirical results on a multi-agent reinforcement learning benchmark environment to support our theoretical findings.
Granger Causality Based Hierarchical Time Series Clustering for State Estimation
Apr 09, 2021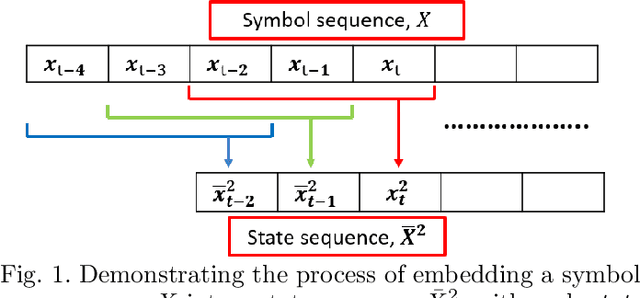
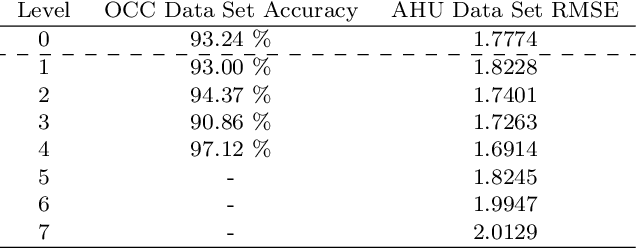
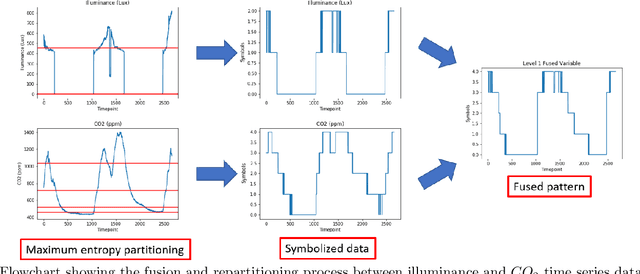
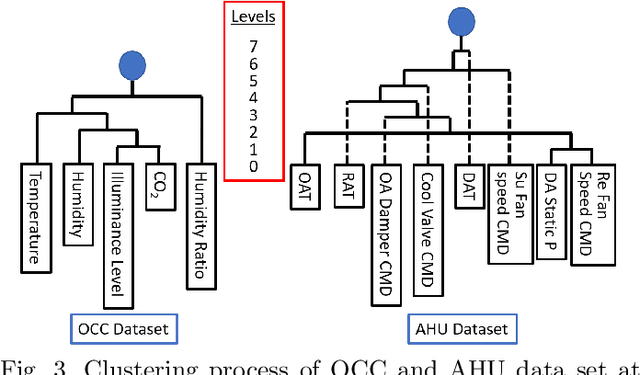
Clustering is an unsupervised learning technique that is useful when working with a large volume of unlabeled data. Complex dynamical systems in real life often entail data streaming from a large number of sources. Although it is desirable to use all source variables to form accurate state estimates, it is often impractical due to large computational power requirements, and sufficiently robust algorithms to handle these cases are not common. We propose a hierarchical time series clustering technique based on symbolic dynamic filtering and Granger causality, which serves as a dimensionality reduction and noise-rejection tool. Our process forms a hierarchy of variables in the multivariate time series with clustering of relevant variables at each level, thus separating out noise and less relevant variables. A new distance metric based on Granger causality is proposed and used for the time series clustering, as well as validated on empirical data sets. Experimental results from occupancy detection and building temperature estimation tasks show fidelity to the empirical data sets while maintaining state-prediction accuracy with substantially reduced data dimensionality.
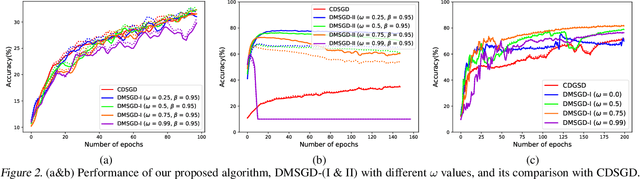
Cross-Gradient Aggregation for Decentralized Learning from Non-IID data
Mar 02, 2021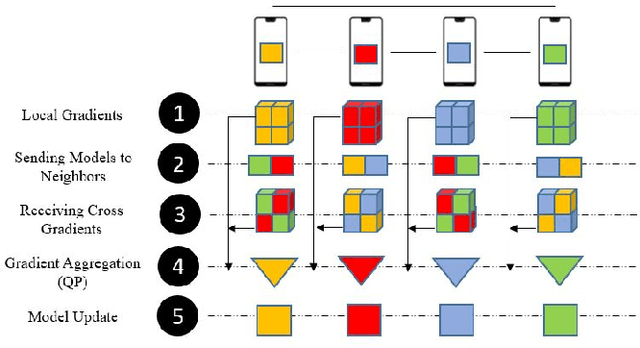

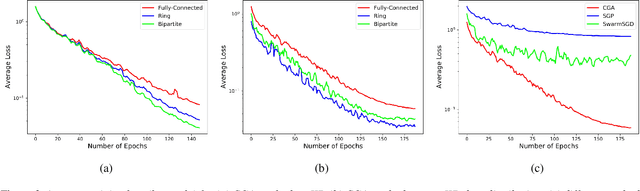
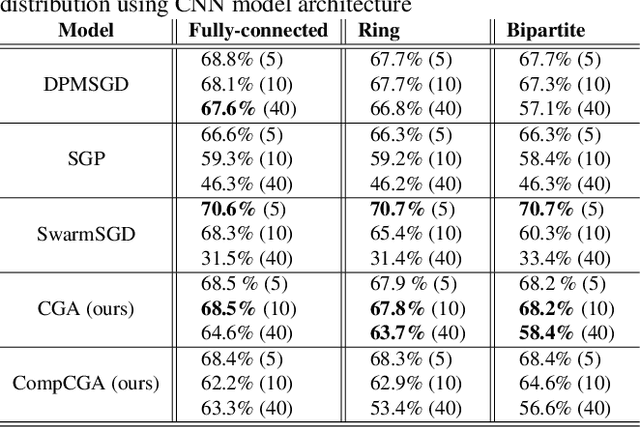
Decentralized learning enables a group of collaborative agents to learn models using a distributed dataset without the need for a central parameter server. Recently, decentralized learning algorithms have demonstrated state-of-the-art results on benchmark data sets, comparable with centralized algorithms. However, the key assumption to achieve competitive performance is that the data is independently and identically distributed (IID) among the agents which, in real-life applications, is often not applicable. Inspired by ideas from continual learning, we propose Cross-Gradient Aggregation (CGA), a novel decentralized learning algorithm where (i) each agent aggregates cross-gradient information, i.e., derivatives of its model with respect to its neighbors' datasets, and (ii) updates its model using a projected gradient based on quadratic programming (QP). We theoretically analyze the convergence characteristics of CGA and demonstrate its efficiency on non-IID data distributions sampled from the MNIST and CIFAR-10 datasets. Our empirical comparisons show superior learning performance of CGA over existing state-of-the-art decentralized learning algorithms, as well as maintaining the improved performance under information compression to reduce peer-to-peer communication overhead.
Decentralized Deep Learning using Momentum-Accelerated Consensus
Oct 21, 2020
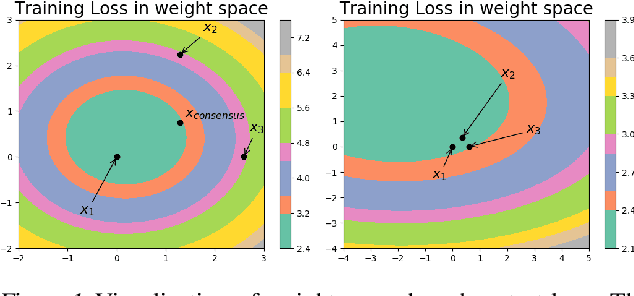
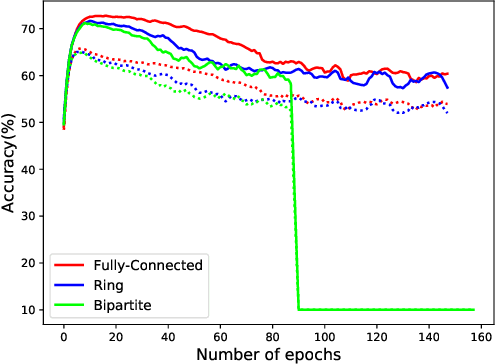
We consider the problem of decentralized deep learning where multiple agents collaborate to learn from a distributed dataset. While there exist several decentralized deep learning approaches, the majority consider a central parameter-server topology for aggregating the model parameters from the agents. However, such a topology may be inapplicable in networked systems such as ad-hoc mobile networks, field robotics, and power network systems where direct communication with the central parameter server may be inefficient. In this context, we propose and analyze a novel decentralized deep learning algorithm where the agents interact over a fixed communication topology (without a central server). Our algorithm is based on the heavy-ball acceleration method used in gradient-based optimization. We propose a novel consensus protocol where each agent shares with its neighbors its model parameters as well as gradient-momentum values during the optimization process. We consider both strongly convex and non-convex objective functions and theoretically analyze our algorithm's performance. We present several empirical comparisons with competing decentralized learning methods to demonstrate the efficacy of our approach under different communication topologies.
Spatiotemporal Attention for Multivariate Time Series Prediction and Interpretation
Aug 11, 2020
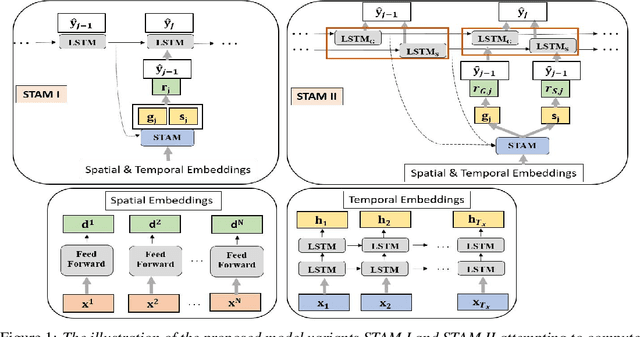
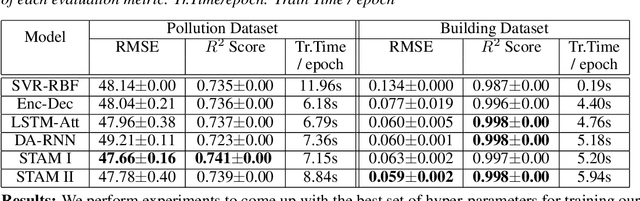
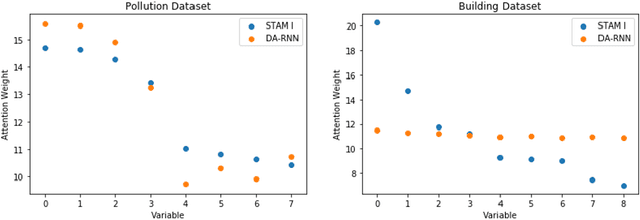
Multivariate time series modeling and prediction problems are abundant in many machine learning application domains. Accurate interpretation of such prediction outcomes from a machine learning model that explicitly captures temporal correlations can be a major benefit to the domain experts. In this context, temporal attention has been successfully applied to isolate the important time steps for the input time series. However, in multivariate time series problems, spatial interpretation is also critical to understand the contributions of different variables on the model outputs. We propose a novel deep learning architecture, called spatiotemporal attention mechanism (STAM) for simultaneous learning of the most important time steps and variables. STAM is a causal (i.e., only depends on past inputs and does not use future inputs) and scalable (i.e., scales well with an increase in the number of variables) approach that is comparable to the state-of-the-art models in terms of computational tractability. We demonstrate the performance of our models both on a popular public dataset as well as on a domain-specific dataset. When compared with the baseline models, the results show that STAM maintains state-of-the-art prediction accuracy while offering the benefit of accurate spatiotemporal interpretability. We validate the learned attention weights from a domain knowledge perspective for the real-world datasets.
On Higher-order Moments in Adam
Oct 15, 2019
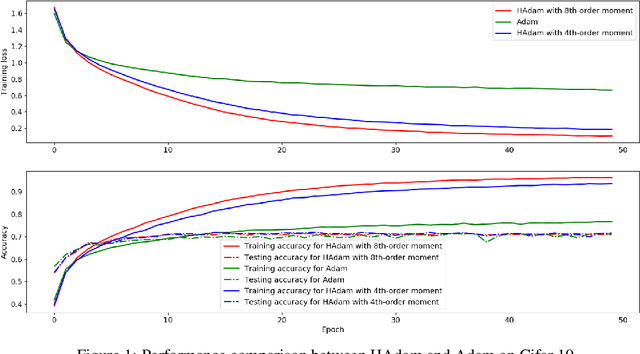
In this paper, we investigate the popular deep learning optimization routine, Adam, from the perspective of statistical moments. While Adam is an adaptive lower-order moment based (of the stochastic gradient) method, we propose an extension namely, HAdam, which uses higher order moments of the stochastic gradient. Our analysis and experiments reveal that certain higher-order moments of the stochastic gradient are able to achieve better performance compared to the vanilla Adam algorithm. We also provide some analysis of HAdam related to odd and even moments to explain some intriguing and seemingly non-intuitive empirical results.