 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLMs for Analog Circuit Design Continuum (ACDC)
Dec 09, 2025Large Language Models (LLMs) and transformer architectures have shown impressive reasoning and generation capabilities across diverse natural language tasks. However, their reliability and robustness in real-world engineering domains remain largely unexplored, limiting their practical utility in human-centric workflows. In this work, we investigate the applicability and consistency of LLMs for analog circuit design -- a task requiring domain-specific reasoning, adherence to physical constraints, and structured representations -- focusing on AI-assisted design where humans remain in the loop. We study how different data representations influence model behavior and compare smaller models (e.g., T5, GPT-2) with larger foundation models (e.g., Mistral-7B, GPT-oss-20B) under varying training conditions. Our results highlight key reliability challenges, including sensitivity to data format, instability in generated designs, and limited generalization to unseen circuit configurations. These findings provide early evidence on the limits and potential of LLMs as tools to enhance human capabilities in complex engineering tasks, offering insights into designing reliable, deployable foundation models for structured, real-world applications.
Provably effective detection of effective data poisoning attacks
Jan 21, 2025
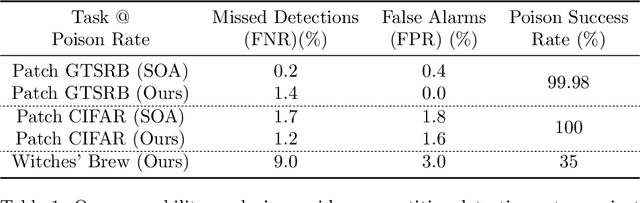
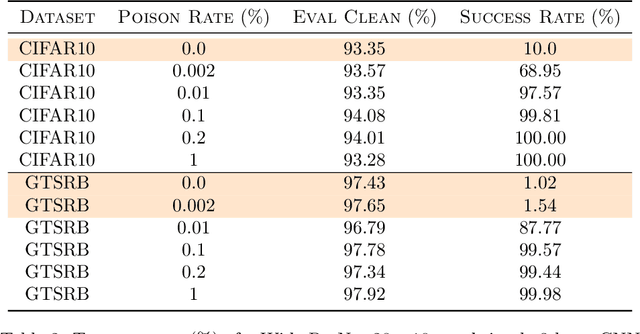
This paper establishes a mathematically precise definition of dataset poisoning attack and proves that the very act of effectively poisoning a dataset ensures that the attack can be effectively detected. On top of a mathematical guarantee that dataset poisoning is identifiable by a new statistical test that we call the Conformal Separability Test, we provide experimental evidence that we can adequately detect poisoning attempts in the real world.
Cross-Gradient Aggregation for Decentralized Learning from Non-IID data
Mar 02, 2021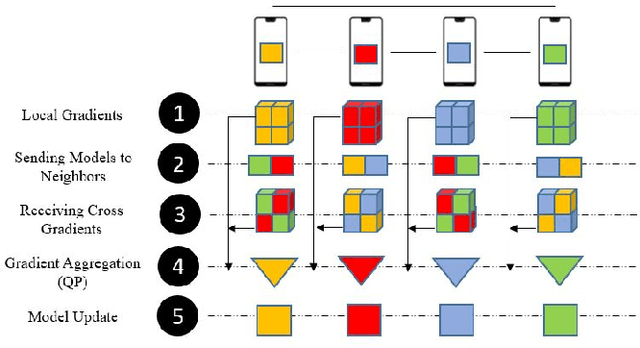

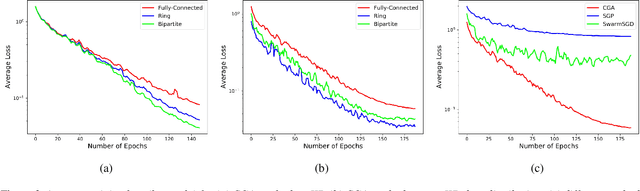
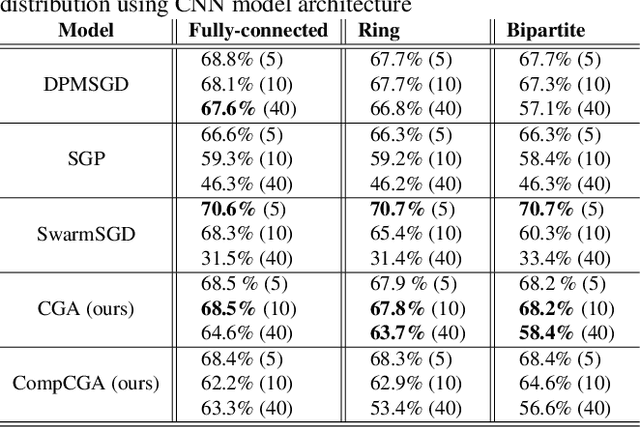
Decentralized learning enables a group of collaborative agents to learn models using a distributed dataset without the need for a central parameter server. Recently, decentralized learning algorithms have demonstrated state-of-the-art results on benchmark data sets, comparable with centralized algorithms. However, the key assumption to achieve competitive performance is that the data is independently and identically distributed (IID) among the agents which, in real-life applications, is often not applicable. Inspired by ideas from continual learning, we propose Cross-Gradient Aggregation (CGA), a novel decentralized learning algorithm where (i) each agent aggregates cross-gradient information, i.e., derivatives of its model with respect to its neighbors' datasets, and (ii) updates its model using a projected gradient based on quadratic programming (QP). We theoretically analyze the convergence characteristics of CGA and demonstrate its efficiency on non-IID data distributions sampled from the MNIST and CIFAR-10 datasets. Our empirical comparisons show superior learning performance of CGA over existing state-of-the-art decentralized learning algorithms, as well as maintaining the improved performance under information compression to reduce peer-to-peer communication overhead.
Query-based Targeted Action-Space Adversarial Policies on Deep Reinforcement Learning Agents
Nov 13, 2020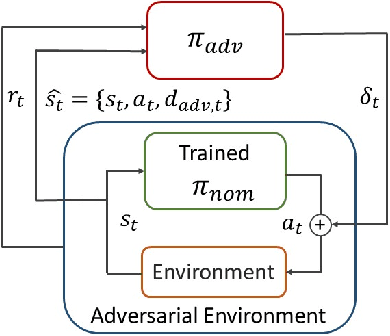
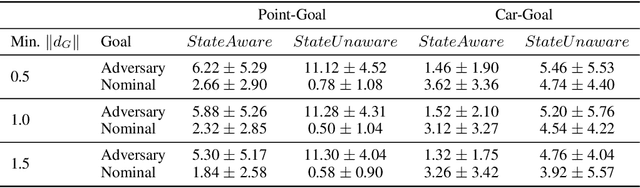
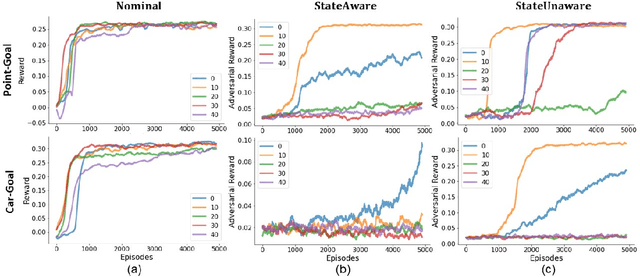
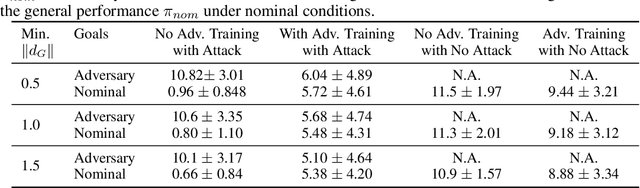
Advances in computing resources have resulted in the increasing complexity of cyber-physical systems (CPS). As the complexity of CPS evolved, the focus has shifted from traditional control methods to deep reinforcement learning-based (DRL) methods for control of these systems. This is due to the difficulty of obtaining accurate models of complex CPS for traditional control. However, to securely deploy DRL in production, it is essential to examine the weaknesses of DRL-based controllers (policies) towards malicious attacks from all angles. In this work, we investigate targeted attacks in the action-space domain, also commonly known as actuation attacks in CPS literature, which perturbs the outputs of a controller. We show that a query-based black-box attack model that generates optimal perturbations with respect to an adversarial goal can be formulated as another reinforcement learning problem. Thus, such an adversarial policy can be trained using conventional DRL methods. Experimental results showed that adversarial policies that only observe the nominal policy's output generate stronger attacks than adversarial policies that observe the nominal policy's input and output. Further analysis reveals that nominal policies whose outputs are frequently at the boundaries of the action space are naturally more robust towards adversarial policies. Lastly, we propose the use of adversarial training with transfer learning to induce robust behaviors into the nominal policy, which decreases the rate of successful targeted attacks by half.
Robustifying Reinforcement Learning Agents via Action Space Adversarial Training
Jul 14, 2020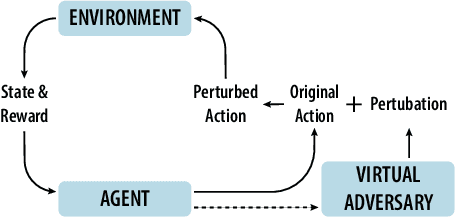
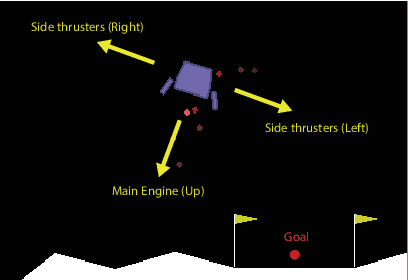
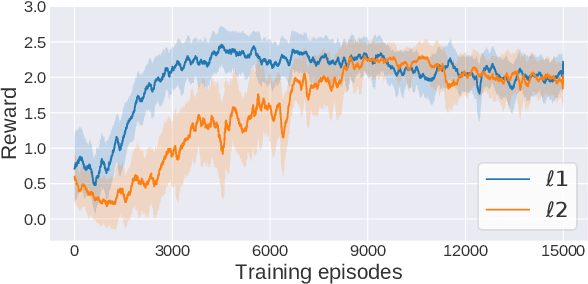
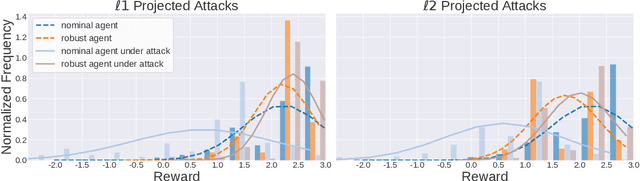
Adoption of machine learning (ML)-enabled cyber-physical systems (CPS) are becoming prevalent in various sectors of modern society such as transportation, industrial, and power grids. Recent studies in deep reinforcement learning (DRL) have demonstrated its benefits in a large variety of data-driven decisions and control applications. As reliance on ML-enabled systems grows, it is imperative to study the performance of these systems under malicious state and actuator attacks. Traditional control systems employ resilient/fault-tolerant controllers that counter these attacks by correcting the system via error observations. However, in some applications, a resilient controller may not be sufficient to avoid a catastrophic failure. Ideally, a robust approach is more useful in these scenarios where a system is inherently robust (by design) to adversarial attacks. While robust control has a long history of development, robust ML is an emerging research area that has already demonstrated its relevance and urgency. However, the majority of robust ML research has focused on perception tasks and not on decision and control tasks, although the ML (specifically RL) models used for control applications are equally vulnerable to adversarial attacks. In this paper, we show that a well-performing DRL agent that is initially susceptible to action space perturbations (e.g. actuator attacks) can be robustified against similar perturbations through adversarial training.
A Saddle-Point Dynamical System Approach for Robust Deep Learning
Oct 18, 2019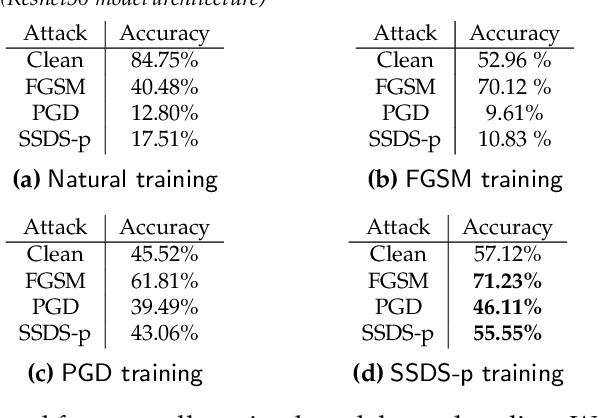

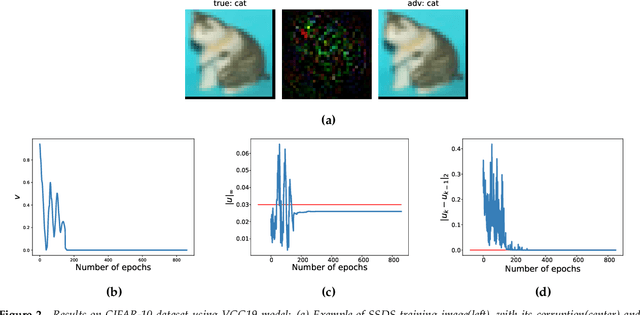
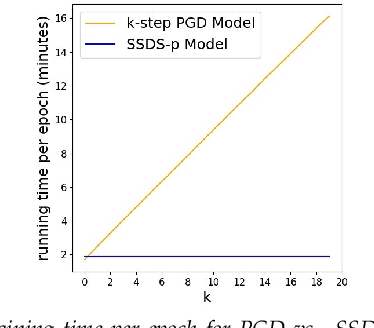
We propose a novel discrete-time dynamical system-based framework for achieving adversarial robustness in machine learning models. Our algorithm is originated from robust optimization, which aims to find the saddle point of a min-max optimization problem in the presence of uncertainties. The robust learning problem is formulated as a robust optimization problem, and we introduce a discrete-time algorithm based on a saddle-point dynamical system (SDS) to solve this problem. Under the assumptions that the cost function is convex and uncertainties enter concavely in the robust learning problem, we analytically show that using a diminishing step-size, the stochastic version of our algorithm, SSDS converges asymptotically to the robust optimal solution. The algorithm is deployed for the training of adversarially robust deep neural networks. Although such training involves highly non-convex non-concave robust optimization problems, empirical results show that the algorithm can achieve significant robustness for deep learning. We compare the performance of our SSDS model to other state-of-the-art robust models, e.g., trained using the projected gradient descent (PGD)-training approach. From the empirical results, we find that SSDS training is computationally inexpensive (compared to PGD-training) while achieving comparable performances. SSDS training also helps robust models to maintain a relatively high level of performance for clean data as well as under black-box attacks.