 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSimMerge: Learning to Select Merge Operators from Similarity Signals
Jan 14, 2026Model merging enables multiple large language models (LLMs) to be combined into a single model while preserving performance. This makes it a valuable tool in LLM development, offering a competitive alternative to multi-task training. However, merging can be difficult at scale, as successful merging requires choosing the right merge operator, selecting the right models, and merging them in the right order. This often leads researchers to run expensive merge-and-evaluate searches to select the best merge. In this work, we provide an alternative by introducing \simmerge{}, \emph{a predictive merge-selection method} that selects the best merge using inexpensive, task-agnostic similarity signals between models. From a small set of unlabeled probes, we compute functional and structural features and use them to predict the performance of a given 2-way merge. Using these predictions, \simmerge{} selects the best merge operator, the subset of models to merge, and the merge order, eliminating the expensive merge-and-evaluate loop. We demonstrate that we surpass standard merge-operator performance on 2-way merges of 7B-parameter LLMs, and that \simmerge{} generalizes to multi-way merges and 111B-parameter LLM merges without retraining. Additionally, we present a bandit variant that supports adding new tasks, models, and operators on the fly. Our results suggest that learning how to merge is a practical route to scalable model composition when checkpoint catalogs are large and evaluation budgets are tight.
The Multilingual Divide and Its Impact on Global AI Safety
May 27, 2025Despite advances in large language model capabilities in recent years, a large gap remains in their capabilities and safety performance for many languages beyond a relatively small handful of globally dominant languages. This paper provides researchers, policymakers and governance experts with an overview of key challenges to bridging the "language gap" in AI and minimizing safety risks across languages. We provide an analysis of why the language gap in AI exists and grows, and how it creates disparities in global AI safety. We identify barriers to address these challenges, and recommend how those working in policy and governance can help address safety concerns associated with the language gap by supporting multilingual dataset creation, transparency, and research.
Command A: An Enterprise-Ready Large Language Model
Apr 01, 2025



In this report we describe the development of Command A, a powerful large language model purpose-built to excel at real-world enterprise use cases. Command A is an agent-optimised and multilingual-capable model, with support for 23 languages of global business, and a novel hybrid architecture balancing efficiency with top of the range performance. It offers best-in-class Retrieval Augmented Generation (RAG) capabilities with grounding and tool use to automate sophisticated business processes. These abilities are achieved through a decentralised training approach, including self-refinement algorithms and model merging techniques. We also include results for Command R7B which shares capability and architectural similarities to Command A. Weights for both models have been released for research purposes. This technical report details our original training pipeline and presents an extensive evaluation of our models across a suite of enterprise-relevant tasks and public benchmarks, demonstrating excellent performance and efficiency.
Mix Data or Merge Models? Optimizing for Diverse Multi-Task Learning
Oct 14, 2024



Large Language Models (LLMs) have been adopted and deployed worldwide for a broad variety of applications. However, ensuring their safe use remains a significant challenge. Preference training and safety measures often overfit to harms prevalent in Western-centric datasets, and safety protocols frequently fail to extend to multilingual settings. In this work, we explore model merging in a diverse multi-task setting, combining safety and general-purpose tasks within a multilingual context. Each language introduces unique and varied learning challenges across tasks. We find that objective-based merging is more effective than mixing data, with improvements of up to 8% and 10% in general performance and safety respectively. We also find that language-based merging is highly effective -- by merging monolingually fine-tuned models, we achieve a 4% increase in general performance and 7% reduction in harm across all languages on top of the data mixtures method using the same available data. Overall, our comprehensive study of merging approaches provides a useful framework for building strong and safe multilingual models.
The Multilingual Alignment Prism: Aligning Global and Local Preferences to Reduce Harm
Jun 26, 2024



A key concern with the concept of "alignment" is the implicit question of "alignment to what?". AI systems are increasingly used across the world, yet safety alignment is often focused on homogeneous monolingual settings. Additionally, preference training and safety measures often overfit to harms common in Western-centric datasets. Here, we explore the viability of different alignment approaches when balancing dual objectives: addressing and optimizing for a non-homogeneous set of languages and cultural preferences while minimizing both global and local harms. We collect the first set of human annotated red-teaming prompts in different languages distinguishing between global and local harm, which serve as a laboratory for understanding the reliability of alignment techniques when faced with preference distributions that are non-stationary across geographies and languages. While this setting is seldom covered by the literature to date, which primarily centers on English harm mitigation, it captures real-world interactions with AI systems around the world. We establish a new precedent for state-of-the-art alignment techniques across 6 languages with minimal degradation in general performance. Our work provides important insights into cross-lingual transfer and novel optimization approaches to safeguard AI systems designed to serve global populations.
Robust Super-Resolution of Real Faces using Smooth Features
Nov 04, 2020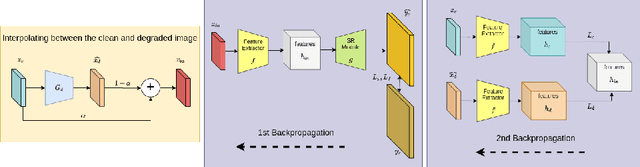

Real low-resolution (LR) face images contain degradations which are too varied and complex to be captured by known downsampling kernels and signal-independent noises. So, in order to successfully super-resolve real faces, a method needs to be robust to a wide range of noise, blur, compression artifacts etc. Some of the recent works attempt to model these degradations from a dataset of real images using a Generative Adversarial Network (GAN). They generate synthetically degraded LR images and use them with corresponding real high-resolution(HR) image to train a super-resolution (SR) network using a combination of a pixel-wise loss and an adversarial loss. In this paper, we propose a two module super-resolution network where the feature extractor module extracts robust features from the LR image, and the SR module generates an HR estimate using only these robust features. We train a degradation GAN to convert bicubically downsampled clean images to real degraded images, and interpolate between the obtained degraded LR image and its clean LR counterpart. This interpolated LR image is then used along with it's corresponding HR counterpart to train the super-resolution network from end to end. Entropy Regularized Wasserstein Divergence is used to force the encoded features learnt from the clean and degraded images to closely resemble those extracted from the interpolated image to ensure robustness.
Robustifying Reinforcement Learning Agents via Action Space Adversarial Training
Jul 14, 2020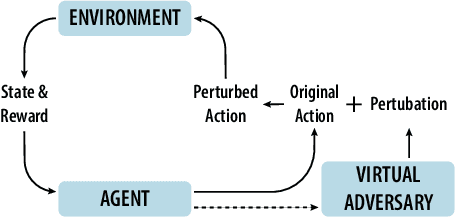
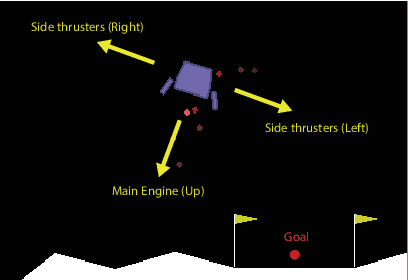
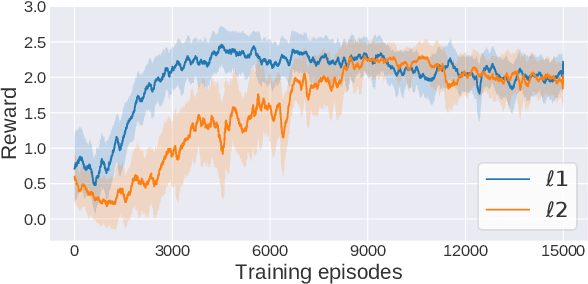
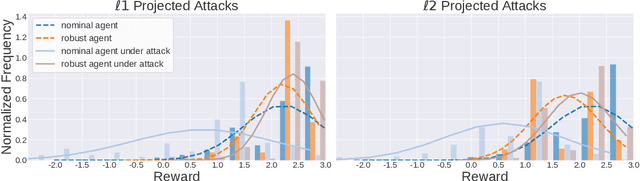
Adoption of machine learning (ML)-enabled cyber-physical systems (CPS) are becoming prevalent in various sectors of modern society such as transportation, industrial, and power grids. Recent studies in deep reinforcement learning (DRL) have demonstrated its benefits in a large variety of data-driven decisions and control applications. As reliance on ML-enabled systems grows, it is imperative to study the performance of these systems under malicious state and actuator attacks. Traditional control systems employ resilient/fault-tolerant controllers that counter these attacks by correcting the system via error observations. However, in some applications, a resilient controller may not be sufficient to avoid a catastrophic failure. Ideally, a robust approach is more useful in these scenarios where a system is inherently robust (by design) to adversarial attacks. While robust control has a long history of development, robust ML is an emerging research area that has already demonstrated its relevance and urgency. However, the majority of robust ML research has focused on perception tasks and not on decision and control tasks, although the ML (specifically RL) models used for control applications are equally vulnerable to adversarial attacks. In this paper, we show that a well-performing DRL agent that is initially susceptible to action space perturbations (e.g. actuator attacks) can be robustified against similar perturbations through adversarial training.