 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Multilingual Divide and Its Impact on Global AI Safety
May 27, 2025Despite advances in large language model capabilities in recent years, a large gap remains in their capabilities and safety performance for many languages beyond a relatively small handful of globally dominant languages. This paper provides researchers, policymakers and governance experts with an overview of key challenges to bridging the "language gap" in AI and minimizing safety risks across languages. We provide an analysis of why the language gap in AI exists and grows, and how it creates disparities in global AI safety. We identify barriers to address these challenges, and recommend how those working in policy and governance can help address safety concerns associated with the language gap by supporting multilingual dataset creation, transparency, and research.
Aya Expanse: Combining Research Breakthroughs for a New Multilingual Frontier
Dec 05, 2024



We introduce the Aya Expanse model family, a new generation of 8B and 32B parameter multilingual language models, aiming to address the critical challenge of developing highly performant multilingual models that match or surpass the capabilities of monolingual models. By leveraging several years of research at Cohere For AI and Cohere, including advancements in data arbitrage, multilingual preference training, and model merging, Aya Expanse sets a new state-of-the-art in multilingual performance. Our evaluations on the Arena-Hard-Auto dataset, translated into 23 languages, demonstrate that Aya Expanse 8B and 32B outperform leading open-weight models in their respective parameter classes, including Gemma 2, Qwen 2.5, and Llama 3.1, achieving up to a 76.6% win-rate. Notably, Aya Expanse 32B outperforms Llama 3.1 70B, a model with twice as many parameters, achieving a 54.0% win-rate. In this short technical report, we present extended evaluation results for the Aya Expanse model family and release their open-weights, together with a new multilingual evaluation dataset m-ArenaHard.
The Reality of AI and Biorisk
Dec 02, 2024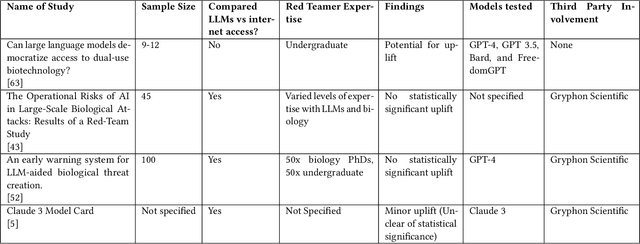
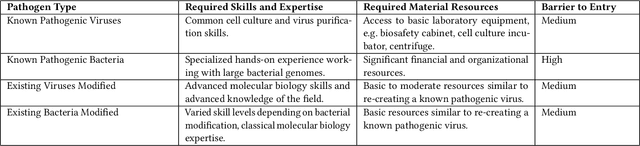
To accurately and confidently answer the question 'could an AI model or system increase biorisk', it is necessary to have both a sound theoretical threat model for how AI models or systems could increase biorisk and a robust method for testing that threat model. This paper provides an analysis of existing available research surrounding two AI and biorisk threat models: 1) access to information and planning via large language models (LLMs), and 2) the use of AI-enabled biological tools (BTs) in synthesizing novel biological artifacts. We find that existing studies around AI-related biorisk are nascent, often speculative in nature, or limited in terms of their methodological maturity and transparency. The available literature suggests that current LLMs and BTs do not pose an immediate risk, and more work is needed to develop rigorous approaches to understanding how future models could increase biorisks. We end with recommendations about how empirical work can be expanded to more precisely target biorisk and ensure rigor and validity of findings.
Going public: the role of public participation approaches in commercial AI labs
Jun 16, 2023In recent years, discussions of responsible AI practices have seen growing support for "participatory AI" approaches, intended to involve members of the public in the design and development of AI systems. Prior research has identified a lack of standardised methods or approaches for how to use participatory approaches in the AI development process. At present, there is a dearth of evidence on attitudes to and approaches for participation in the sites driving major AI developments: commercial AI labs. Through 12 semi-structured interviews with industry practitioners and subject-matter experts, this paper explores how commercial AI labs understand participatory AI approaches and the obstacles they have faced implementing these practices in the development of AI systems and research. We find that while interviewees view participation as a normative project that helps achieve "societally beneficial" AI systems, practitioners face numerous barriers to embedding participatory approaches in their companies: participation is expensive and resource intensive, it is "atomised" within companies, there is concern about exploitation, there is no incentive to be transparent about its adoption, and it is complicated by a lack of clear context. These barriers result in a piecemeal approach to participation that confers no decision-making power to participants and has little ongoing impact for AI labs. This papers contribution is to provide novel empirical research on the implementation of public participation in commercial AI labs, and shed light on the current challenges of using participatory approaches in this context.
Does "AI" stand for augmenting inequality in the era of covid-19 healthcare?
Apr 30, 2021Among the most damaging characteristics of the covid-19 pandemic has been its disproportionate effect on disadvantaged communities. As the outbreak has spread globally, factors such as systemic racism, marginalisation, and structural inequality have created path dependencies that have led to poor health outcomes. These social determinants of infectious disease and vulnerability to disaster have converged to affect already disadvantaged communities with higher levels of economic instability, disease exposure, infection severity, and death. Artificial intelligence (AI) technologies are an important part of the health informatics toolkit used to fight contagious disease. AI is well known, however, to be susceptible to algorithmic biases that can entrench and augment existing inequality. Uncritically deploying AI in the fight against covid-19 thus risks amplifying the pandemic's adverse effects on vulnerable groups, exacerbating health inequity. In this paper, we claim that AI systems can introduce or reflect bias and discrimination in three ways: in patterns of health discrimination that become entrenched in datasets, in data representativeness, and in human choices made during the design, development, and deployment of these systems. We highlight how the use of AI technologies threaten to exacerbate the disparate effect of covid-19 on marginalised, under-represented, and vulnerable groups, particularly black, Asian, and other minoritised ethnic people, older populations, and those of lower socioeconomic status. We conclude that, to mitigate the compounding effects of AI on inequalities associated with covid-19, decision makers, technology developers, and health officials must account for the potential biases and inequities at all stages of the AI process.