 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning from data with structured missingness
Apr 04, 2023Missing data are an unavoidable complication in many machine learning tasks. When data are `missing at random' there exist a range of tools and techniques to deal with the issue. However, as machine learning studies become more ambitious, and seek to learn from ever-larger volumes of heterogeneous data, an increasingly encountered problem arises in which missing values exhibit an association or structure, either explicitly or implicitly. Such `structured missingness' raises a range of challenges that have not yet been systematically addressed, and presents a fundamental hindrance to machine learning at scale. Here, we outline the current literature and propose a set of grand challenges in learning from data with structured missingness.
Don't "research fast and break things": On the ethics of Computational Social Science
Jun 12, 2022

This article is concerned with setting up practical guardrails within the research activities and environments of CSS. It aims to provide CSS scholars, as well as policymakers and other stakeholders who apply CSS methods, with the critical and constructive means needed to ensure that their practices are ethical, trustworthy, and responsible. It begins by providing a taxonomy of the ethical challenges faced by researchers in the field of CSS. These are challenges related to (1) the treatment of research subjects, (2) the impacts of CSS research on affected individuals and communities, (3) the quality of CSS research and to its epistemological status, (4) research integrity, and (5) research equity. Taking these challenges as a motivation for cultural transformation, it then argues for the end-to-end incorporation of habits of responsible research and innovation (RRI) into CSS practices, focusing on the role that contextual considerations, anticipatory reflection, impact assessment, public engagement, and justifiable and well-documented action should play across the research lifecycle. In proposing the inclusion of habits of RRI in CSS practices, the chapter lays out several practical steps needed for ethical, trustworthy, and responsible CSS research activities. These include stakeholder engagement processes, research impact assessments, data lifecycle documentation, bias self-assessments, and transparent research reporting protocols.
Data Justice Stories: A Repository of Case Studies
Apr 06, 2022The idea of "data justice" is of recent academic vintage. It has arisen over the past decade in Anglo-European research institutions as an attempt to bring together a critique of the power dynamics that underlie accelerating trends of datafication with a normative commitment to the principles of social justice-a commitment to the achievement of a society that is equitable, fair, and capable of confronting the root causes of injustice.However, despite the seeming novelty of such a data justice pedigree, this joining up of the critique of the power imbalances that have shaped the digital and "big data" revolutions with a commitment to social equity and constructive societal transformation has a deeper historical, and more geographically diverse, provenance. As the stories of the data justice initiatives, activism, and advocacy contained in this volume well evidence, practices of data justice across the globe have, in fact, largely preceded the elaboration and crystallisation of the idea of data justice in contemporary academic discourse. In telling these data justice stories, we hope to provide the reader with two interdependent tools of data justice thinking: First, we aim to provide the reader with the critical leverage needed to discern those distortions and malformations of data justice that manifest in subtle and explicit forms of power, domination, and coercion. Second, we aim to provide the reader with access to the historically effective forms of normativity and ethical insight that have been marshalled by data justice activists and advocates as tools of societal transformation-so that these forms of normativity and insight can be drawn on, in turn, as constructive resources to spur future transformative data justice practices.
Advancing Data Justice Research and Practice: An Integrated Literature Review
Apr 06, 2022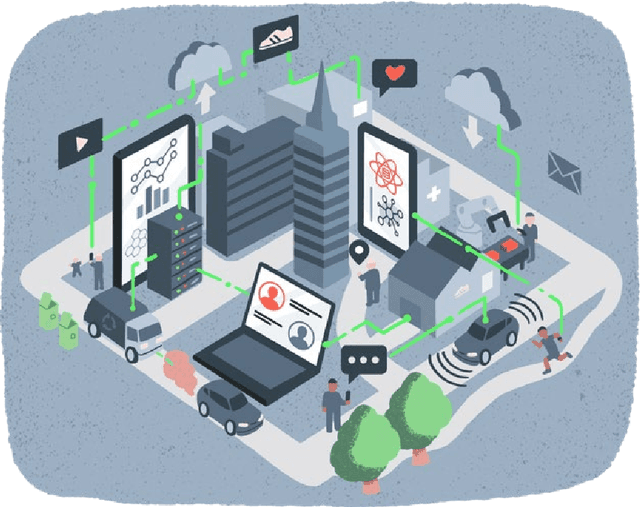

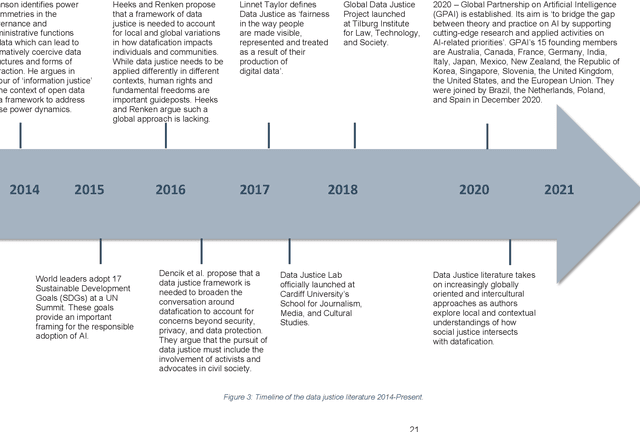
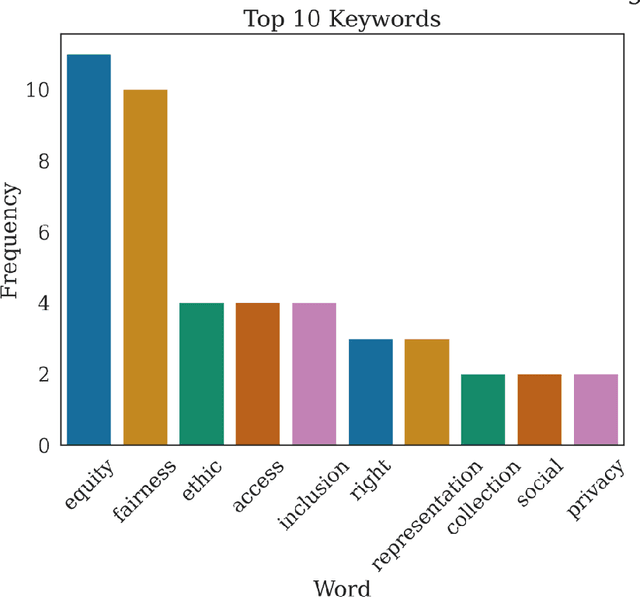
The Advancing Data Justice Research and Practice (ADJRP) project aims to widen the lens of current thinking around data justice and to provide actionable resources that will help policymakers, practitioners, and impacted communities gain a broader understanding of what equitable, freedom-promoting, and rights-sustaining data collection, governance, and use should look like in increasingly dynamic and global data innovation ecosystems. In this integrated literature review we hope to lay the conceptual groundwork needed to support this aspiration. The introduction motivates the broadening of data justice that is undertaken by the literature review which follows. First, we address how certain limitations of the current study of data justice drive the need for a re-location of data justice research and practice. We map out the strengths and shortcomings of the contemporary state of the art and then elaborate on the challenges faced by our own effort to broaden the data justice perspective in the decolonial context. The body of the literature review covers seven thematic areas. For each theme, the ADJRP team has systematically collected and analysed key texts in order to tell the critical empirical story of how existing social structures and power dynamics present challenges to data justice and related justice fields. In each case, this critical empirical story is also supplemented by the transformational story of how activists, policymakers, and academics are challenging longstanding structures of inequity to advance social justice in data innovation ecosystems and adjacent areas of technological practice.
Human rights, democracy, and the rule of law assurance framework for AI systems: A proposal
Feb 06, 2022Following on from the publication of its Feasibility Study in December 2020, the Council of Europe's Ad Hoc Committee on Artificial Intelligence (CAHAI) and its subgroups initiated efforts to formulate and draft its Possible Elements of a Legal Framework on Artificial Intelligence, based on the Council of Europe's standards on human rights, democracy, and the rule of law. This document was ultimately adopted by the CAHAI plenary in December 2021. To support this effort, The Alan Turing Institute undertook a programme of research that explored the governance processes and practical tools needed to operationalise the integration of human right due diligence with the assurance of trustworthy AI innovation practices. The resulting framework was completed and submitted to the Council of Europe in September 2021. It presents an end-to-end approach to the assurance of AI project lifecycles that integrates context-based risk analysis and appropriate stakeholder engagement with comprehensive impact assessment, and transparent risk management, impact mitigation, and innovation assurance practices. Taken together, these interlocking processes constitute a Human Rights, Democracy and the Rule of Law Assurance Framework (HUDERAF). The HUDERAF combines the procedural requirements for principles-based human rights due diligence with the governance mechanisms needed to set up technical and socio-technical guardrails for responsible and trustworthy AI innovation practices. Its purpose is to provide an accessible and user-friendly set of mechanisms for facilitating compliance with a binding legal framework on artificial intelligence, based on the Council of Europe's standards on human rights, democracy, and the rule of law, and to ensure that AI innovation projects are carried out with appropriate levels of public accountability, transparency, and democratic governance.
Gaussian Processes on Hypergraphs
Jun 03, 2021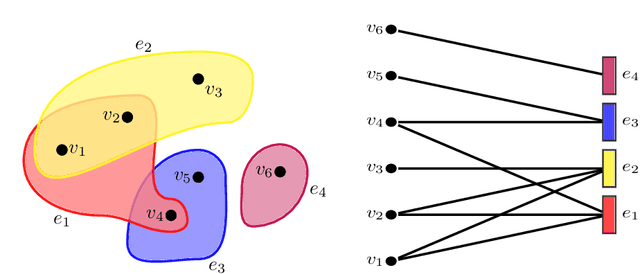
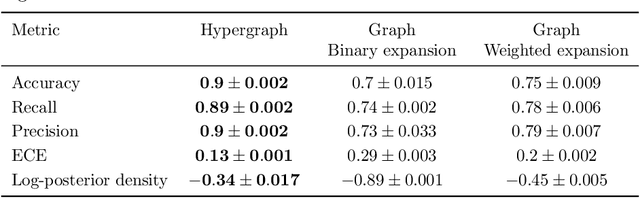
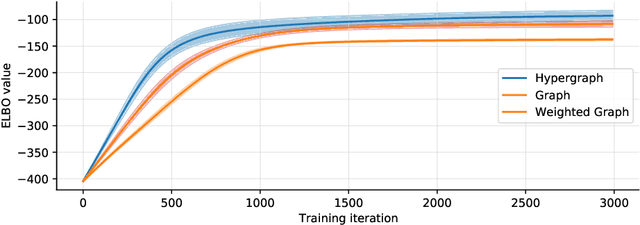
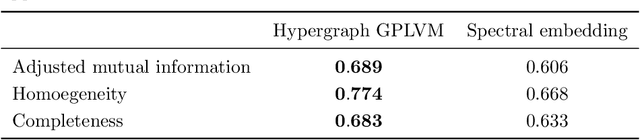
We derive a Matern Gaussian process (GP) on the vertices of a hypergraph. This enables estimation of regression models of observed or latent values associated with the vertices, in which the correlation and uncertainty estimates are informed by the hypergraph structure. We further present a framework for embedding the vertices of a hypergraph into a latent space using the hypergraph GP. Finally, we provide a scheme for identifying a small number of representative inducing vertices that enables scalable inference through sparse GPs. We demonstrate the utility of our framework on three challenging real-world problems that concern multi-class classification for the political party affiliation of legislators on the basis of voting behaviour, probabilistic matrix factorisation of movie reviews, and embedding a hypergraph of animals into a low-dimensional latent space.
Does "AI" stand for augmenting inequality in the era of covid-19 healthcare?
Apr 30, 2021Among the most damaging characteristics of the covid-19 pandemic has been its disproportionate effect on disadvantaged communities. As the outbreak has spread globally, factors such as systemic racism, marginalisation, and structural inequality have created path dependencies that have led to poor health outcomes. These social determinants of infectious disease and vulnerability to disaster have converged to affect already disadvantaged communities with higher levels of economic instability, disease exposure, infection severity, and death. Artificial intelligence (AI) technologies are an important part of the health informatics toolkit used to fight contagious disease. AI is well known, however, to be susceptible to algorithmic biases that can entrench and augment existing inequality. Uncritically deploying AI in the fight against covid-19 thus risks amplifying the pandemic's adverse effects on vulnerable groups, exacerbating health inequity. In this paper, we claim that AI systems can introduce or reflect bias and discrimination in three ways: in patterns of health discrimination that become entrenched in datasets, in data representativeness, and in human choices made during the design, development, and deployment of these systems. We highlight how the use of AI technologies threaten to exacerbate the disparate effect of covid-19 on marginalised, under-represented, and vulnerable groups, particularly black, Asian, and other minoritised ethnic people, older populations, and those of lower socioeconomic status. We conclude that, to mitigate the compounding effects of AI on inequalities associated with covid-19, decision makers, technology developers, and health officials must account for the potential biases and inequities at all stages of the AI process.
Artificial intelligence, human rights, democracy, and the rule of law: a primer
Apr 02, 2021In September 2019, the Council of Europe's Committee of Ministers adopted the terms of reference for the Ad Hoc Committee on Artificial Intelligence (CAHAI). The CAHAI is charged with examining the feasibility and potential elements of a legal framework for the design, development, and deployment of AI systems that accord with Council of Europe standards across the interrelated areas of human rights, democracy, and the rule of law. As a first and necessary step in carrying out this responsibility, the CAHAI's Feasibility Study, adopted by its plenary in December 2020, has explored options for an international legal response that fills existing gaps in legislation and tailors the use of binding and non-binding legal instruments to the specific risks and opportunities presented by AI systems. The Study examines how the fundamental rights and freedoms that are already codified in international human rights law can be used as the basis for such a legal framework. The purpose of this primer is to introduce the main concepts and principles presented in the CAHAI's Feasibility Study for a general, non-technical audience. It also aims to provide some background information on the areas of AI innovation, human rights law, technology policy, and compliance mechanisms covered therein. In keeping with the Council of Europe's commitment to broad multi-stakeholder consultations, outreach, and engagement, this primer has been designed to help facilitate the meaningful and informed participation of an inclusive group of stakeholders as the CAHAI seeks feedback and guidance regarding the essential issues raised by the Feasibility Study.
Explaining decisions made with AI: A workbook
Mar 20, 2021
Over the last two years, The Alan Turing Institute and the Information Commissioner's Office (ICO) have been working together to discover ways to tackle the difficult issues surrounding explainable AI. The ultimate product of this joint endeavour, Explaining decisions made with AI, published in May 2020, is the most comprehensive practical guidance on AI explanation produced anywhere to date. We have put together this workbook to help support the uptake of that guidance. The goal of the workbook is to summarise some of main themes from Explaining decisions made with AI and then to provide the materials for a workshop exercise that has been built around a use case created to help you gain a flavour of how to put the guidance into practice. In the first three sections, we run through the basics of Explaining decisions made with AI. We provide a precis of the four principles of AI explainability, the typology of AI explanations, and the tasks involved in the explanation-aware design, development, and use of AI/ML systems. We then provide some reflection questions, which are intended to be a launching pad for group discussion, and a starting point for the case-study-based exercise that we have included as Appendix B. In Appendix A, we go into more detailed suggestions about how to organise the workshop. These recommendations are based on two workshops we had the privilege of co-hosting with our colleagues from the ICO and Manchester Metropolitan University in January 2021. The participants of these workshops came from both the private and public sectors, and we are extremely grateful to them for their energy, enthusiasm, and tremendous insight. This workbook would simply not exist without the commitment and keenness of all our collaborators and workshop participants.
The Arc of the Data Scientific Universe
Feb 06, 2021In this paper I explore the scaffolding of normative assumptions that supports Sabina Leonelli's implicit appeal to the values of epistemic integrity and the global public good that conjointly animate the ethos of responsible and sustainable data work in the context of COVID-19. Drawing primarily on the writings of sociologist Robert K. Merton, the thinkers of the Vienna Circle, and Charles Sanders Peirce, I make some of these assumptions explicit by telling a longer story about the evolution of social thinking about the normative structure of science from Merton's articulation of his well-known norms (those of universalism, communism, organized skepticism, and disinterestedness) to the present. I show that while Merton's norms and his intertwinement of these with the underlying mechanisms of democratic order provide us with an especially good starting point to explore and clarify the commitments and values of science, Leonelli's broader, more context-responsive, and more holistic vision of the epistemic integrity of data scientific understanding, and her discernment of the global and biospheric scope of its moral-practical reach, move beyond Merton's schema in ways that effectively draw upon important critiques. Stepping past Merton, I argue that a combination of situated universalism, methodological pluralism, strong objectivity, and unbounded communalism must guide the responsible and sustainable data work of the future.
* 43 pages