 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLarge Models of What? Mistaking Engineering Achievements for Human Linguistic Agency
Jul 11, 2024In this paper we argue that key, often sensational and misleading, claims regarding linguistic capabilities of Large Language Models (LLMs) are based on at least two unfounded assumptions; the assumption of language completeness and the assumption of data completeness. Language completeness assumes that a distinct and complete thing such as `a natural language' exists, the essential characteristics of which can be effectively and comprehensively modelled by an LLM. The assumption of data completeness relies on the belief that a language can be quantified and wholly captured by data. Work within the enactive approach to cognitive science makes clear that, rather than a distinct and complete thing, language is a means or way of acting. Languaging is not the kind of thing that can admit of a complete or comprehensive modelling. From an enactive perspective we identify three key characteristics of enacted language; embodiment, participation, and precariousness, that are absent in LLMs, and likely incompatible in principle with current architectures. We argue that these absences imply that LLMs are not now and cannot in their present form be linguistic agents the way humans are. We illustrate the point in particular through the phenomenon of `algospeak', a recently described pattern of high stakes human language activity in heavily controlled online environments. On the basis of these points, we conclude that sensational and misleading claims about LLM agency and capabilities emerge from a deep misconception of both what human language is and what LLMs are.
The Surveillance AI Pipeline
Sep 26, 2023



A rapidly growing number of voices have argued that AI research, and computer vision in particular, is closely tied to mass surveillance. Yet the direct path from computer vision research to surveillance has remained obscured and difficult to assess. This study reveals the Surveillance AI pipeline. We obtain three decades of computer vision research papers and downstream patents (more than 20,000 documents) and present a rich qualitative and quantitative analysis. This analysis exposes the nature and extent of the Surveillance AI pipeline, its institutional roots and evolution, and ongoing patterns of obfuscation. We first perform an in-depth content analysis of computer vision papers and downstream patents, identifying and quantifying key features and the many, often subtly expressed, forms of surveillance that appear. On the basis of this analysis, we present a topology of Surveillance AI that characterizes the prevalent targeting of human data, practices of data transferal, and institutional data use. We find stark evidence of close ties between computer vision and surveillance. The majority (68%) of annotated computer vision papers and patents self-report their technology enables data extraction about human bodies and body parts and even more (90%) enable data extraction about humans in general.
The Lost Art of Mathematical Modelling
Jan 19, 2023



We provide a critique of mathematical biology in light of rapid developments in modern machine learning. We argue that out of the three modelling activities -- (1) formulating models; (2) analysing models; and (3) fitting or comparing models to data -- inherent to mathematical biology, researchers currently focus too much on activity (2) at the cost of (1). This trend, we propose, can be reversed by realising that any given biological phenomena can be modelled in an infinite number of different ways, through the adoption of an open/pluralistic approach. We explain the open approach using fish locomotion as a case study and illustrate some of the pitfalls -- universalism, creating models of models, etc. -- that hinder mathematical biology. We then ask how we might rediscover a lost art: that of creative mathematical modelling. This article is dedicated to the memory of Edmund Crampin.
Handling and Presenting Harmful Text
Apr 29, 2022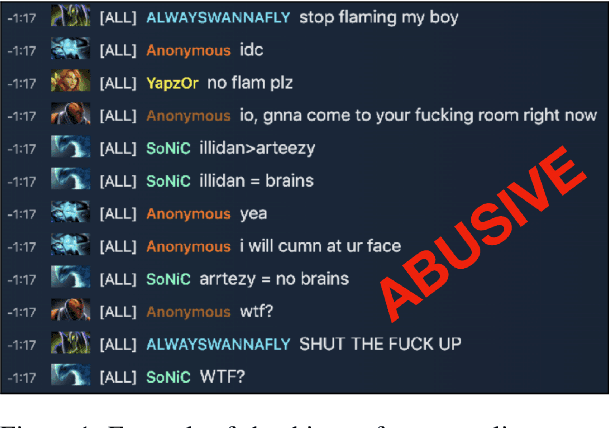
Textual data can pose a risk of serious harm. These harms can be categorised along three axes: (1) the harm type (e.g. misinformation, hate speech or racial stereotypes) (2) whether it is \textit{elicited} as a feature of the research design from directly studying harmful content (e.g. training a hate speech classifier or auditing unfiltered large-scale datasets) versus \textit{spuriously} invoked from working on unrelated problems (e.g. language generation or part of speech tagging) but with datasets that nonetheless contain harmful content, and (3) who it affects, from the humans (mis)represented in the data to those handling or labelling the data to readers and reviewers of publications produced from the data. It is an unsolved problem in NLP as to how textual harms should be handled, presented, and discussed; but, stopping work on content which poses a risk of harm is untenable. Accordingly, we provide practical advice and introduce \textsc{HarmCheck}, a resource for reflecting on research into textual harms. We hope our work encourages ethical, responsible, and respectful research in the NLP community.
Data Justice Stories: A Repository of Case Studies
Apr 06, 2022The idea of "data justice" is of recent academic vintage. It has arisen over the past decade in Anglo-European research institutions as an attempt to bring together a critique of the power dynamics that underlie accelerating trends of datafication with a normative commitment to the principles of social justice-a commitment to the achievement of a society that is equitable, fair, and capable of confronting the root causes of injustice.However, despite the seeming novelty of such a data justice pedigree, this joining up of the critique of the power imbalances that have shaped the digital and "big data" revolutions with a commitment to social equity and constructive societal transformation has a deeper historical, and more geographically diverse, provenance. As the stories of the data justice initiatives, activism, and advocacy contained in this volume well evidence, practices of data justice across the globe have, in fact, largely preceded the elaboration and crystallisation of the idea of data justice in contemporary academic discourse. In telling these data justice stories, we hope to provide the reader with two interdependent tools of data justice thinking: First, we aim to provide the reader with the critical leverage needed to discern those distortions and malformations of data justice that manifest in subtle and explicit forms of power, domination, and coercion. Second, we aim to provide the reader with access to the historically effective forms of normativity and ethical insight that have been marshalled by data justice activists and advocates as tools of societal transformation-so that these forms of normativity and insight can be drawn on, in turn, as constructive resources to spur future transformative data justice practices.
Advancing Data Justice Research and Practice: An Integrated Literature Review
Apr 06, 2022

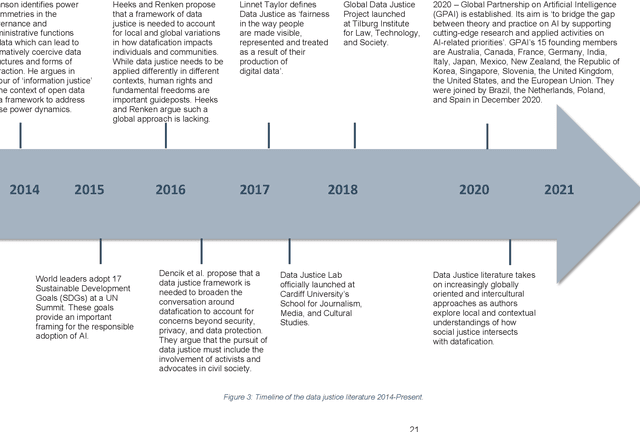
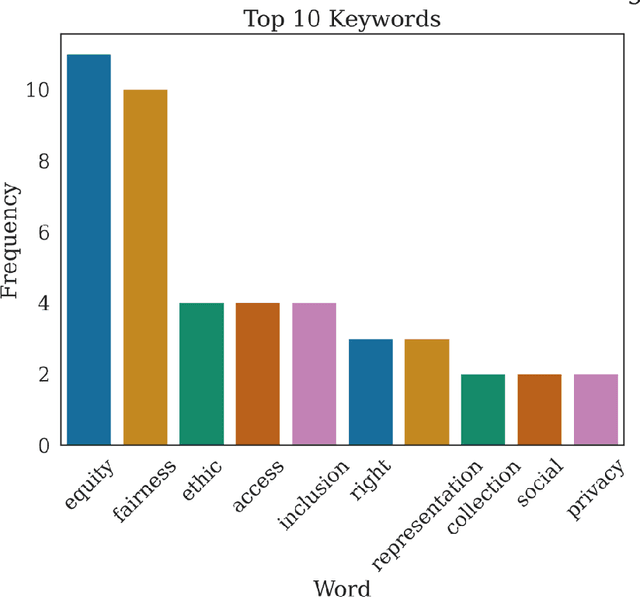
The Advancing Data Justice Research and Practice (ADJRP) project aims to widen the lens of current thinking around data justice and to provide actionable resources that will help policymakers, practitioners, and impacted communities gain a broader understanding of what equitable, freedom-promoting, and rights-sustaining data collection, governance, and use should look like in increasingly dynamic and global data innovation ecosystems. In this integrated literature review we hope to lay the conceptual groundwork needed to support this aspiration. The introduction motivates the broadening of data justice that is undertaken by the literature review which follows. First, we address how certain limitations of the current study of data justice drive the need for a re-location of data justice research and practice. We map out the strengths and shortcomings of the contemporary state of the art and then elaborate on the challenges faced by our own effort to broaden the data justice perspective in the decolonial context. The body of the literature review covers seven thematic areas. For each theme, the ADJRP team has systematically collected and analysed key texts in order to tell the critical empirical story of how existing social structures and power dynamics present challenges to data justice and related justice fields. In each case, this critical empirical story is also supplemented by the transformational story of how activists, policymakers, and academics are challenging longstanding structures of inequity to advance social justice in data innovation ecosystems and adjacent areas of technological practice.
Ethical and social risks of harm from Language Models
Dec 08, 2021
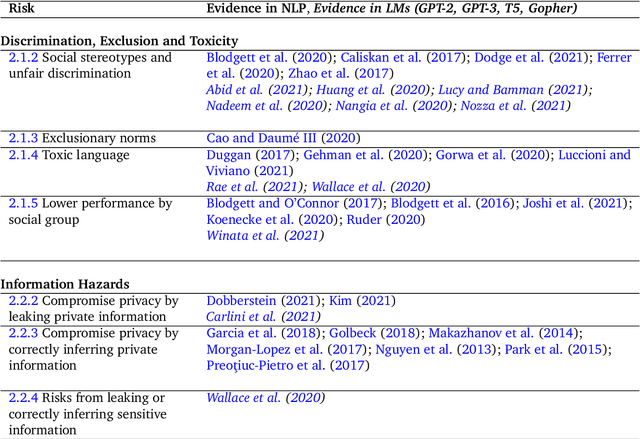
This paper aims to help structure the risk landscape associated with large-scale Language Models (LMs). In order to foster advances in responsible innovation, an in-depth understanding of the potential risks posed by these models is needed. A wide range of established and anticipated risks are analysed in detail, drawing on multidisciplinary expertise and literature from computer science, linguistics, and social sciences. We outline six specific risk areas: I. Discrimination, Exclusion and Toxicity, II. Information Hazards, III. Misinformation Harms, V. Malicious Uses, V. Human-Computer Interaction Harms, VI. Automation, Access, and Environmental Harms. The first area concerns the perpetuation of stereotypes, unfair discrimination, exclusionary norms, toxic language, and lower performance by social group for LMs. The second focuses on risks from private data leaks or LMs correctly inferring sensitive information. The third addresses risks arising from poor, false or misleading information including in sensitive domains, and knock-on risks such as the erosion of trust in shared information. The fourth considers risks from actors who try to use LMs to cause harm. The fifth focuses on risks specific to LLMs used to underpin conversational agents that interact with human users, including unsafe use, manipulation or deception. The sixth discusses the risk of environmental harm, job automation, and other challenges that may have a disparate effect on different social groups or communities. In total, we review 21 risks in-depth. We discuss the points of origin of different risks and point to potential mitigation approaches. Lastly, we discuss organisational responsibilities in implementing mitigations, and the role of collaboration and participation. We highlight directions for further research, particularly on expanding the toolkit for assessing and evaluating the outlined risks in LMs.
The Values Encoded in Machine Learning Research
Jun 29, 2021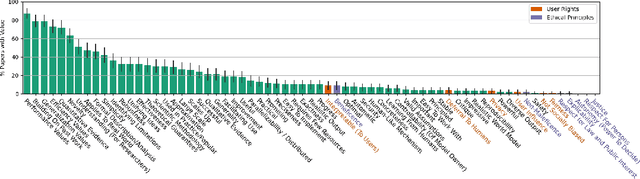


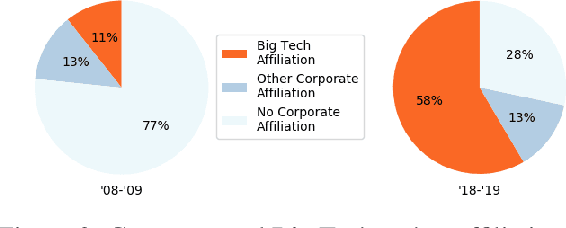
Machine learning (ML) currently exerts an outsized influence on the world, increasingly affecting communities and institutional practices. It is therefore critical that we question vague conceptions of the field as value-neutral or universally beneficial, and investigate what specific values the field is advancing. In this paper, we present a rigorous examination of the values of the field by quantitatively and qualitatively analyzing 100 highly cited ML papers published at premier ML conferences, ICML and NeurIPS. We annotate key features of papers which reveal their values: how they justify their choice of project, which aspects they uplift, their consideration of potential negative consequences, and their institutional affiliations and funding sources. We find that societal needs are typically very loosely connected to the choice of project, if mentioned at all, and that consideration of negative consequences is extremely rare. We identify 67 values that are uplifted in machine learning research, and, of these, we find that papers most frequently justify and assess themselves based on performance, generalization, efficiency, researcher understanding, novelty, and building on previous work. We present extensive textual evidence and analysis of how these values are operationalized. Notably, we find that each of these top values is currently being defined and applied with assumptions and implications generally supporting the centralization of power. Finally, we find increasingly close ties between these highly cited papers and tech companies and elite universities.
Large image datasets: A pyrrhic win for computer vision?
Jun 24, 2020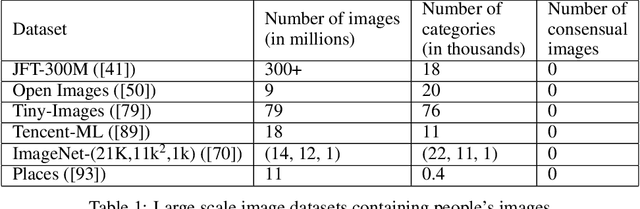


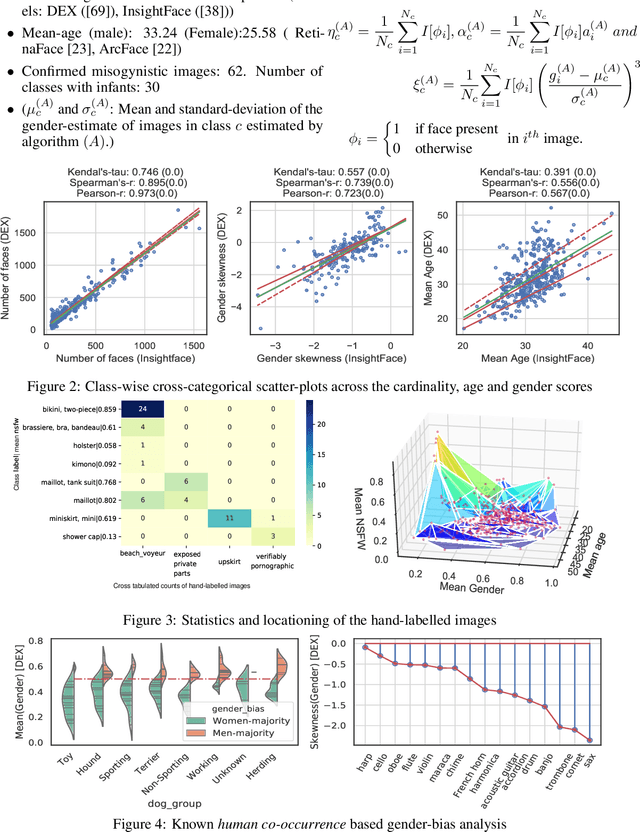
In this paper we investigate problematic practices and consequences of large scale vision datasets. We examine broad issues such as the question of consent and justice as well as specific concerns such as the inclusion of verifiably pornographic images in datasets. Taking the ImageNet-ILSVRC-2012 dataset as an example, we perform a cross-sectional model-based quantitative census covering factors such as age, gender, NSFW content scoring, class-wise accuracy, human-cardinality-analysis, and the semanticity of the image class information in order to statistically investigate the extent and subtleties of ethical transgressions. We then use the census to help hand-curate a look-up-table of images in the ImageNet-ILSVRC-2012 dataset that fall into the categories of verifiably pornographic: shot in a non-consensual setting (up-skirt), beach voyeuristic, and exposed private parts. We survey the landscape of harm and threats both society broadly and individuals face due to uncritical and ill-considered dataset curation practices. We then propose possible courses of correction and critique the pros and cons of these. We have duly open-sourced all of the code and the census meta-datasets generated in this endeavor for the computer vision community to build on. By unveiling the severity of the threats, our hope is to motivate the constitution of mandatory Institutional Review Boards (IRB) for large scale dataset curation processes.