 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMapping the Podcast Ecosystem with the Structured Podcast Research Corpus
Nov 12, 2024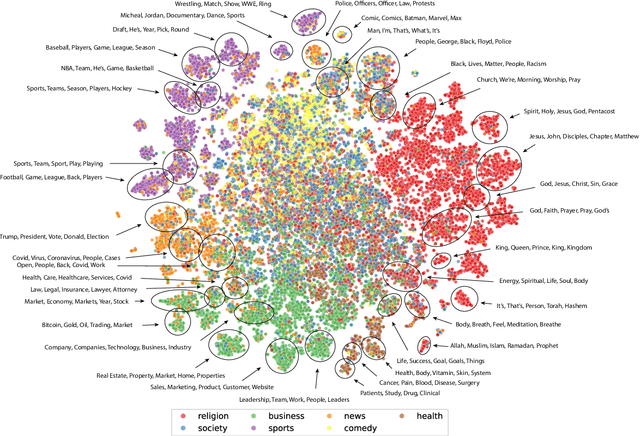


Podcasts provide highly diverse content to a massive listener base through a unique on-demand modality. However, limited data has prevented large-scale computational analysis of the podcast ecosystem. To fill this gap, we introduce a massive dataset of over 1.1M podcast transcripts that is largely comprehensive of all English language podcasts available through public RSS feeds from May and June of 2020. This data is not limited to text, but rather includes audio features and speaker turns for a subset of 370K episodes, and speaker role inferences and other metadata for all 1.1M episodes. Using this data, we also conduct a foundational investigation into the content, structure, and responsiveness of this ecosystem. Together, our data and analyses open the door to continued computational research of this popular and impactful medium.
Framing Social Movements on Social Media: Unpacking Diagnostic, Prognostic, and Motivational Strategies
Jun 19, 2024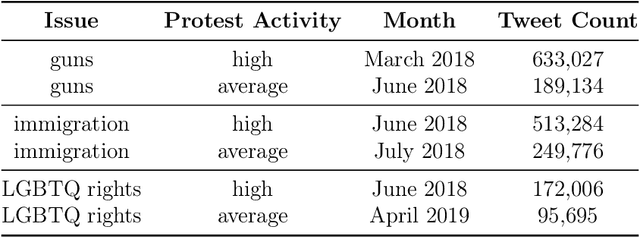
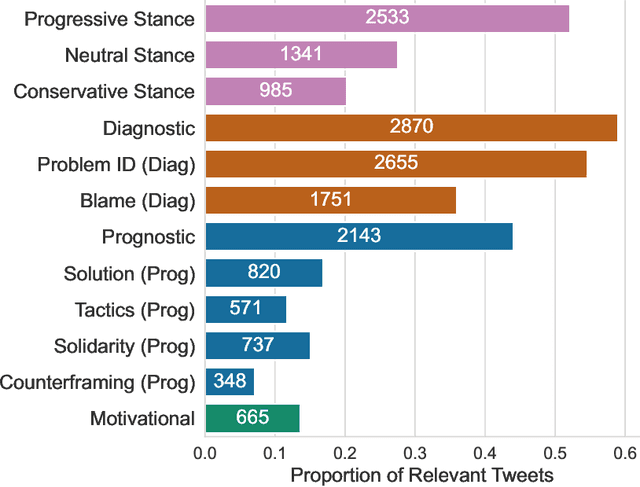
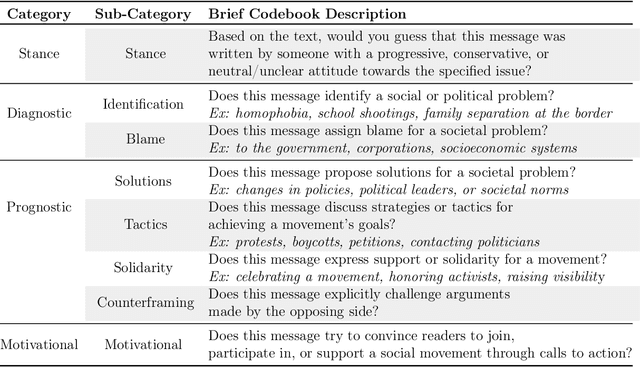
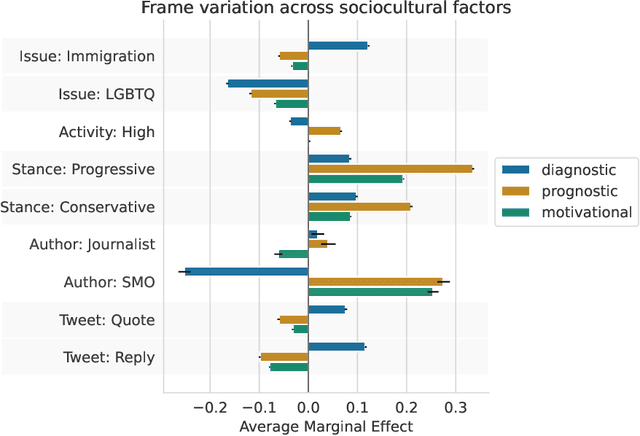
Social media enables activists to directly communicate with the public and provides a space for movement leaders, participants, bystanders, and opponents to collectively construct and contest narratives. Focusing on Twitter messages from social movements surrounding three issues in 2018-2019 (guns, immigration, and LGBTQ rights), we create a codebook, annotated dataset, and computational models to detect diagnostic (problem identification and attribution), prognostic (proposed solutions and tactics), and motivational (calls to action) framing strategies. We conduct an in-depth unsupervised linguistic analysis of each framing strategy, and uncover cross-movement similarities in associations between framing and linguistic features such as pronouns and deontic modal verbs. Finally, we compare framing strategies across issues and other social, cultural, and interactional contexts. For example, we show that diagnostic framing is more common in replies than original broadcast posts, and that social movement organizations focus much more on prognostic and motivational framing than journalists and ordinary citizens.
* Published in ICWSM Special Issue of the Journal of Quantitative Description: Digital Media
When it Rains, it Pours: Modeling Media Storms and the News Ecosystem
Dec 04, 2023



Most events in the world receive at most brief coverage by the news media. Occasionally, however, an event will trigger a media storm, with voluminous and widespread coverage lasting for weeks instead of days. In this work, we develop and apply a pairwise article similarity model, allowing us to identify story clusters in corpora covering local and national online news, and thereby create a comprehensive corpus of media storms over a nearly two year period. Using this corpus, we investigate media storms at a new level of granularity, allowing us to validate claims about storm evolution and topical distribution, and provide empirical support for previously hypothesized patterns of influence of storms on media coverage and intermedia agenda setting.
You don't need a personality test to know these models are unreliable: Assessing the Reliability of Large Language Models on Psychometric Instruments
Nov 16, 2023The versatility of Large Language Models (LLMs) on natural language understanding tasks has made them popular for research in social sciences. In particular, to properly understand the properties and innate personas of LLMs, researchers have performed studies that involve using prompts in the form of questions that ask LLMs of particular opinions. In this study, we take a cautionary step back and examine whether the current format of prompting enables LLMs to provide responses in a consistent and robust manner. We first construct a dataset that contains 693 questions encompassing 39 different instruments of persona measurement on 115 persona axes. Additionally, we design a set of prompts containing minor variations and examine LLM's capabilities to generate accurate answers, as well as consistency variations to examine their consistency towards simple perturbations such as switching the option order. Our experiments on 15 different open-source LLMs reveal that even simple perturbations are sufficient to significantly downgrade a model's question-answering ability, and that most LLMs have low negation consistency. Our results suggest that the currently widespread practice of prompting is insufficient to accurately capture model perceptions, and we discuss potential alternatives to improve such issues.
Substitution-based Semantic Change Detection using Contextual Embeddings
Sep 06, 2023
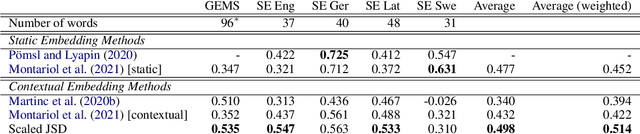


Measuring semantic change has thus far remained a task where methods using contextual embeddings have struggled to improve upon simpler techniques relying only on static word vectors. Moreover, many of the previously proposed approaches suffer from downsides related to scalability and ease of interpretation. We present a simplified approach to measuring semantic change using contextual embeddings, relying only on the most probable substitutes for masked terms. Not only is this approach directly interpretable, it is also far more efficient in terms of storage, achieves superior average performance across the most frequently cited datasets for this task, and allows for more nuanced investigation of change than is possible with static word vectors.
Problems with Cosine as a Measure of Embedding Similarity for High Frequency Words
May 10, 2022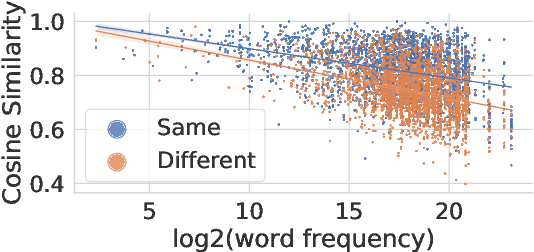
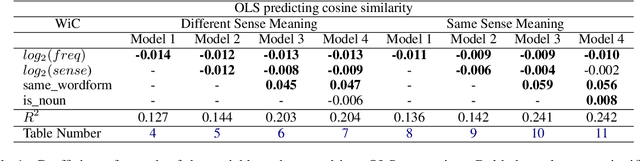
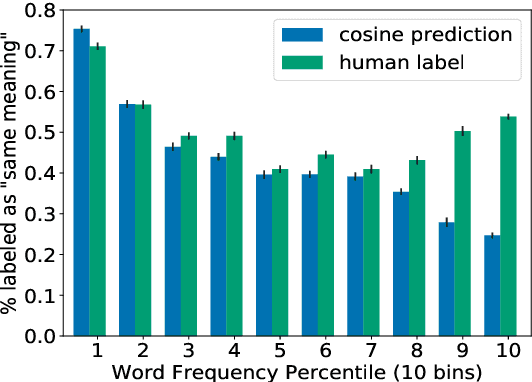

Cosine similarity of contextual embeddings is used in many NLP tasks (e.g., QA, IR, MT) and metrics (e.g., BERTScore). Here, we uncover systematic ways in which word similarities estimated by cosine over BERT embeddings are understated and trace this effect to training data frequency. We find that relative to human judgements, cosine similarity underestimates the similarity of frequent words with other instances of the same word or other words across contexts, even after controlling for polysemy and other factors. We conjecture that this underestimation of similarity for high frequency words is due to differences in the representational geometry of high and low frequency words and provide a formal argument for the two-dimensional case.
Modular Domain Adaptation
Apr 26, 2022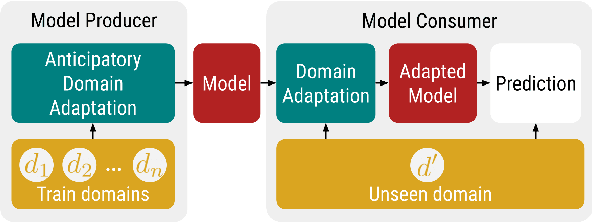

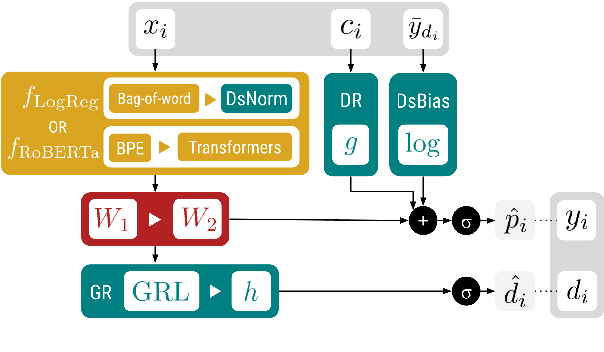
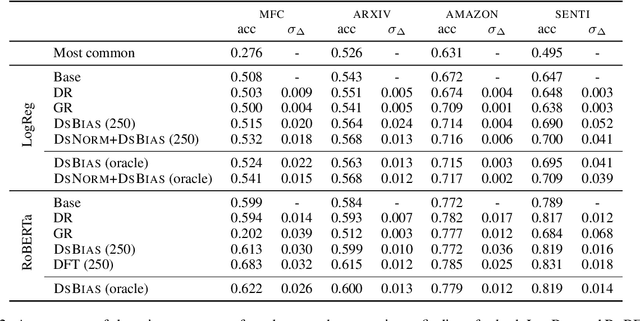
Off-the-shelf models are widely used by computational social science researchers to measure properties of text, such as sentiment. However, without access to source data it is difficult to account for domain shift, which represents a threat to validity. Here, we treat domain adaptation as a modular process that involves separate model producers and model consumers, and show how they can independently cooperate to facilitate more accurate measurements of text. We introduce two lightweight techniques for this scenario, and demonstrate that they reliably increase out-of-domain accuracy on four multi-domain text classification datasets when used with linear and contextual embedding models. We conclude with recommendations for model producers and consumers, and release models and replication code to accompany this paper.
Whose Language Counts as High Quality? Measuring Language Ideologies in Text Data Selection
Jan 26, 2022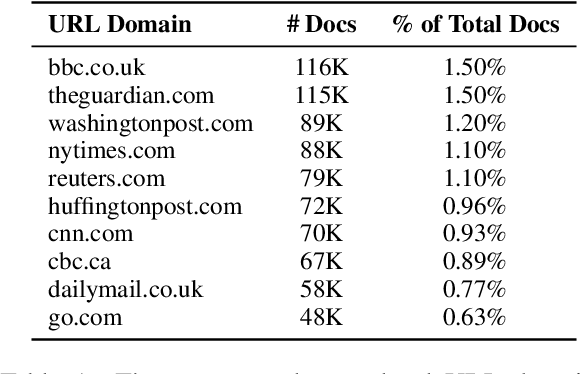
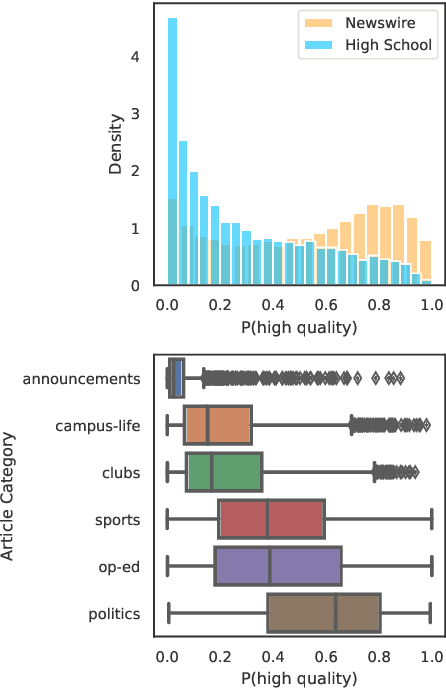
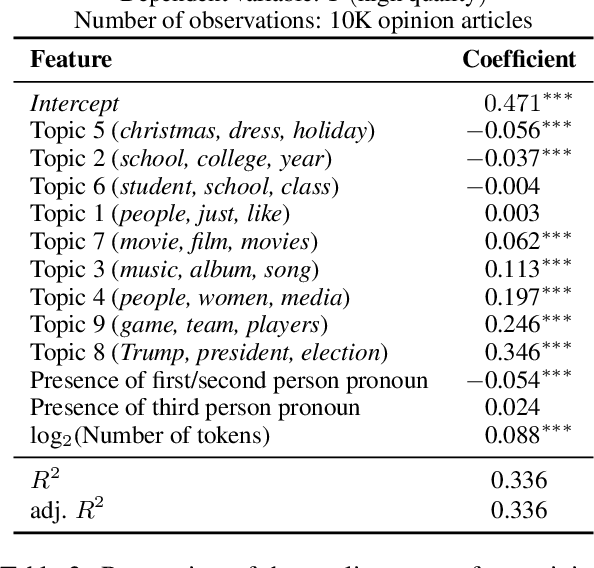
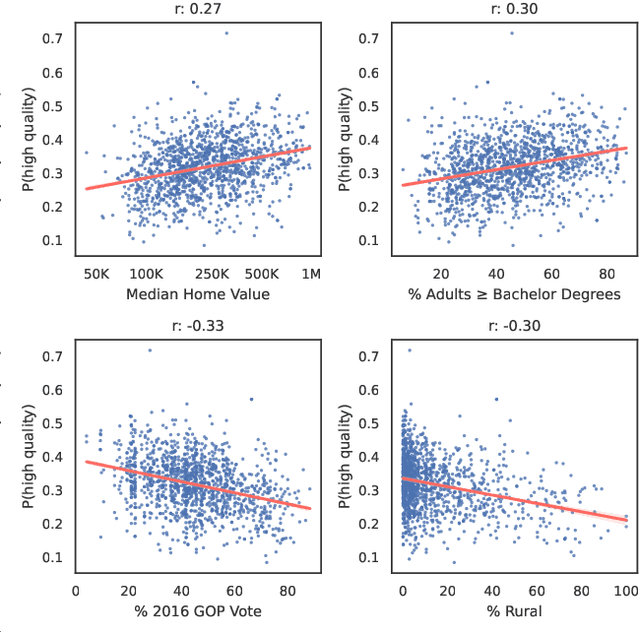
Language models increasingly rely on massive web dumps for diverse text data. However, these sources are rife with undesirable content. As such, resources like Wikipedia, books, and newswire often serve as anchors for automatically selecting web text most suitable for language modeling, a process typically referred to as quality filtering. Using a new dataset of U.S. high school newspaper articles -- written by students from across the country -- we investigate whose language is preferred by the quality filter used for GPT-3. We find that newspapers from larger schools, located in wealthier, educated, and urban ZIP codes are more likely to be classified as high quality. We then demonstrate that the filter's measurement of quality is unaligned with other sensible metrics, such as factuality or literary acclaim. We argue that privileging any corpus as high quality entails a language ideology, and more care is needed to construct training corpora for language models, with better transparency and justification for the inclusion or exclusion of various texts.
Expected Validation Performance and Estimation of a Random Variable's Maximum
Oct 01, 2021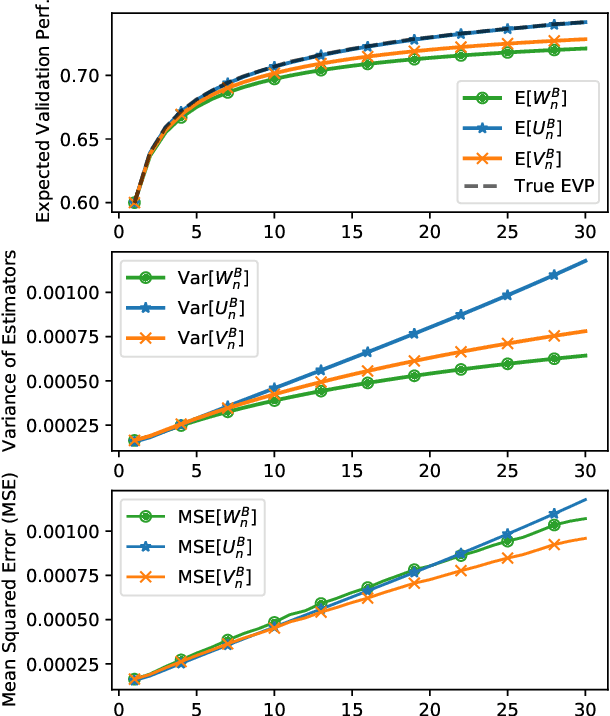
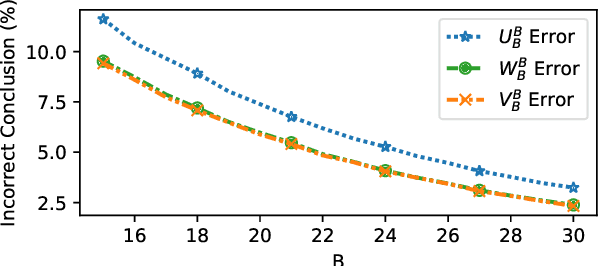
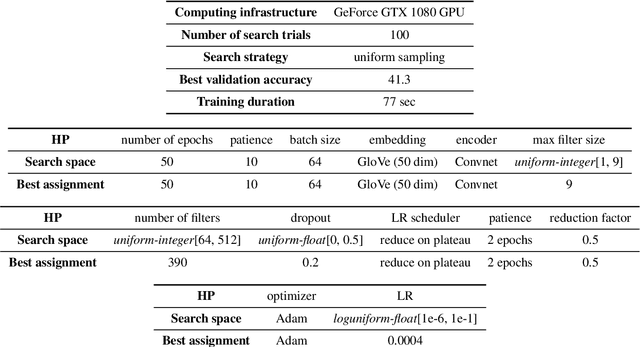
Research in NLP is often supported by experimental results, and improved reporting of such results can lead to better understanding and more reproducible science. In this paper we analyze three statistical estimators for expected validation performance, a tool used for reporting performance (e.g., accuracy) as a function of computational budget (e.g., number of hyperparameter tuning experiments). Where previous work analyzing such estimators focused on the bias, we also examine the variance and mean squared error (MSE). In both synthetic and realistic scenarios, we evaluate three estimators and find the unbiased estimator has the highest variance, and the estimator with the smallest variance has the largest bias; the estimator with the smallest MSE strikes a balance between bias and variance, displaying a classic bias-variance tradeoff. We use expected validation performance to compare between different models, and analyze how frequently each estimator leads to drawing incorrect conclusions about which of two models performs best. We find that the two biased estimators lead to the fewest incorrect conclusions, which hints at the importance of minimizing variance and MSE.
On the Opportunities and Risks of Foundation Models
Aug 18, 2021



AI is undergoing a paradigm shift with the rise of models (e.g., BERT, DALL-E, GPT-3) that are trained on broad data at scale and are adaptable to a wide range of downstream tasks. We call these models foundation models to underscore their critically central yet incomplete character. This report provides a thorough account of the opportunities and risks of foundation models, ranging from their capabilities (e.g., language, vision, robotics, reasoning, human interaction) and technical principles(e.g., model architectures, training procedures, data, systems, security, evaluation, theory) to their applications (e.g., law, healthcare, education) and societal impact (e.g., inequity, misuse, economic and environmental impact, legal and ethical considerations). Though foundation models are based on standard deep learning and transfer learning, their scale results in new emergent capabilities,and their effectiveness across so many tasks incentivizes homogenization. Homogenization provides powerful leverage but demands caution, as the defects of the foundation model are inherited by all the adapted models downstream. Despite the impending widespread deployment of foundation models, we currently lack a clear understanding of how they work, when they fail, and what they are even capable of due to their emergent properties. To tackle these questions, we believe much of the critical research on foundation models will require deep interdisciplinary collaboration commensurate with their fundamentally sociotechnical nature.