 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Prosocial Ranking Challenge: Reducing Polarization on Social Media without Sacrificing Engagement
Mar 20, 2026We report the first direct comparisons of multiple alternative social media algorithms on multiple platforms on outcomes of societal interest. We used a browser extension to modify which posts were shown to desktop social media users, randomly assigning 9,386 users to a control group or one of five alternative ranking algorithms which simultaneously altered content across three platforms for six months during the US 2024 presidential election. This reduced our preregistered index of affective polarization by an average of 0.03 standard deviations (p < 0.05), including a 1.5 degree decrease in differences between the 100 point inparty and outparty feeling thermometers. We saw reductions in active use time for Facebook (-0.37 min/day) and Reddit (-0.2 min/day), but an increase of 0.32 min/day (p < 0.01) for X/Twitter. We saw an increase in reports of negative social media experiences but found no effects on well-being, news knowledge, outgroup empathy, perceptions of and support for partisan violence. This implies that bridging content can improve some societal outcomes without necessarily conflicting with the engagement-driven business model of social media.
When People are Floods: Analyzing Dehumanizing Metaphors in Immigration Discourse with Large Language Models
Feb 18, 2025Metaphor, discussing one concept in terms of another, is abundant in politics and can shape how people understand important issues. We develop a computational approach to measure metaphorical language, focusing on immigration discourse on social media. Grounded in qualitative social science research, we identify seven concepts evoked in immigration discourse (e.g. "water" or "vermin"). We propose and evaluate a novel technique that leverages both word-level and document-level signals to measure metaphor with respect to these concepts. We then study the relationship between metaphor, political ideology, and user engagement in 400K US tweets about immigration. While conservatives tend to use dehumanizing metaphors more than liberals, this effect varies widely across concepts. Moreover, creature-related metaphor is associated with more retweets, especially for liberal authors. Our work highlights the potential for computational methods to complement qualitative approaches in understanding subtle and implicit language in political discourse.
Plurals: A System for Guiding LLMs Via Simulated Social Ensembles
Sep 25, 2024
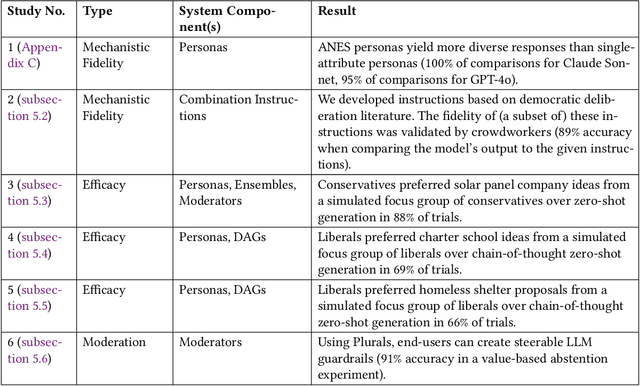
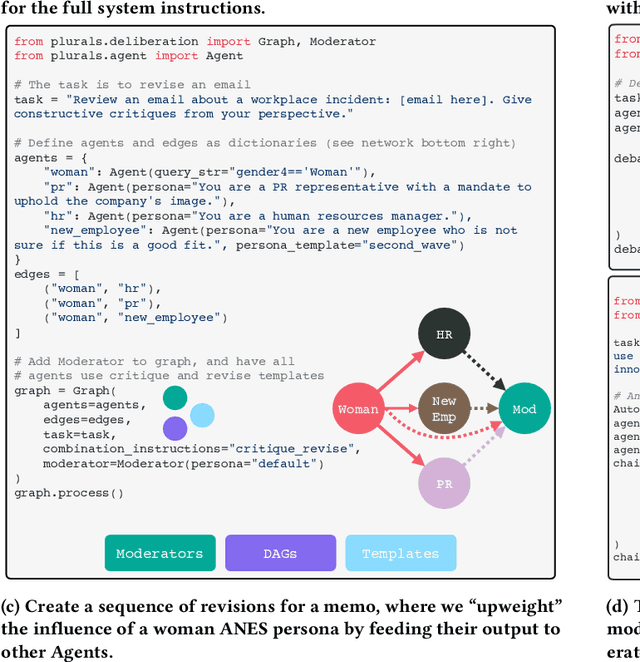
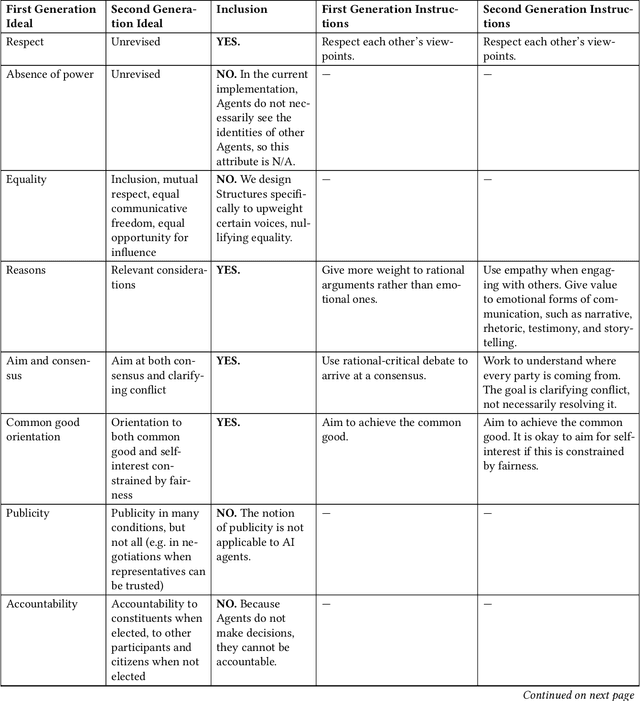
Recent debates raised concerns that language models may favor certain viewpoints. But what if the solution is not to aim for a 'view from nowhere' but rather to leverage different viewpoints? We introduce Plurals, a system and Python library for pluralistic AI deliberation. Plurals consists of Agents (LLMs, optionally with personas) which deliberate within customizable Structures, with Moderators overseeing deliberation. Plurals is a generator of simulated social ensembles. Plurals integrates with government datasets to create nationally representative personas, includes deliberation templates inspired by democratic deliberation theory, and allows users to customize both information-sharing structures and deliberation behavior within Structures. Six case studies demonstrate fidelity to theoretical constructs and efficacy. Three randomized experiments show simulated focus groups produced output resonant with an online sample of the relevant audiences (chosen over zero-shot generation in 75% of trials). Plurals is both a paradigm and a concrete system for pluralistic AI. The Plurals library is available at https://github.com/josh-ashkinaze/plurals and will be continually updated.
Seeing Like an AI: How LLMs Apply (and Misapply) Wikipedia Neutrality Norms
Jul 04, 2024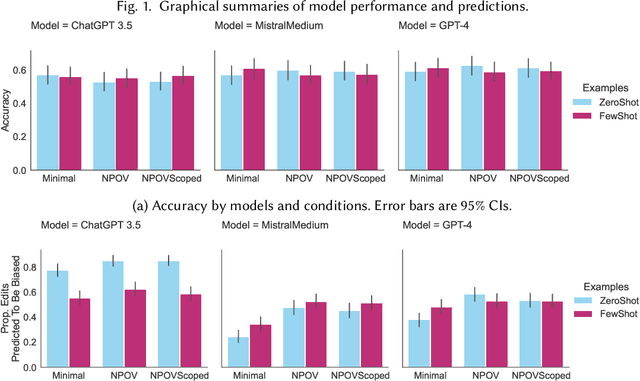
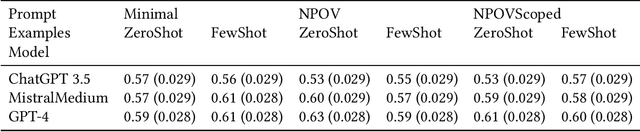
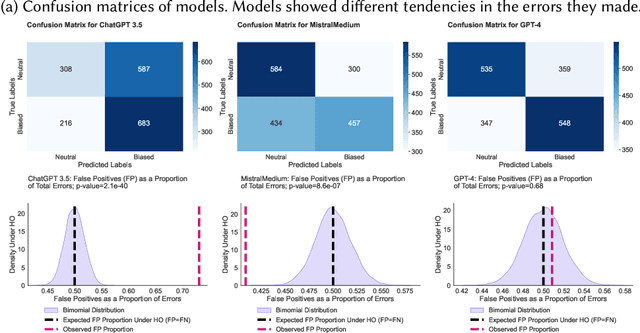
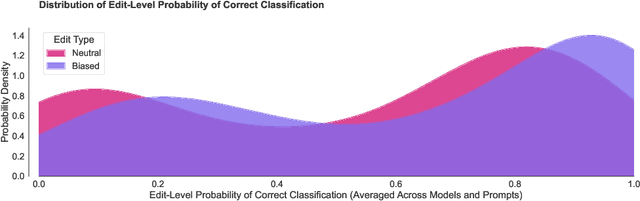
Large language models (LLMs) are trained on broad corpora and then used in communities with specialized norms. Is providing LLMs with community rules enough for models to follow these norms? We evaluate LLMs' capacity to detect (Task 1) and correct (Task 2) biased Wikipedia edits according to Wikipedia's Neutral Point of View (NPOV) policy. LLMs struggled with bias detection, achieving only 64% accuracy on a balanced dataset. Models exhibited contrasting biases (some under- and others over-predicted bias), suggesting distinct priors about neutrality. LLMs performed better at generation, removing 79% of words removed by Wikipedia editors. However, LLMs made additional changes beyond Wikipedia editors' simpler neutralizations, resulting in high-recall but low-precision editing. Interestingly, crowdworkers rated AI rewrites as more neutral (70%) and fluent (61%) than Wikipedia-editor rewrites. Qualitative analysis found LLMs sometimes applied NPOV more comprehensively than Wikipedia editors but often made extraneous non-NPOV-related changes (such as grammar). LLMs may apply rules in ways that resonate with the public but diverge from community experts. While potentially effective for generation, LLMs may reduce editor agency and increase moderation workload (e.g., verifying additions). Even when rules are easy to articulate, having LLMs apply them like community members may still be difficult.
Framing Social Movements on Social Media: Unpacking Diagnostic, Prognostic, and Motivational Strategies
Jun 19, 2024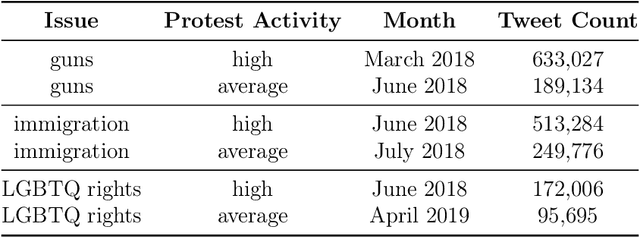
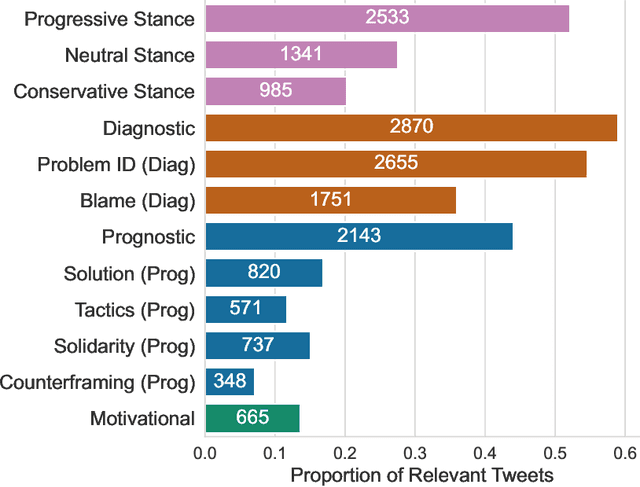
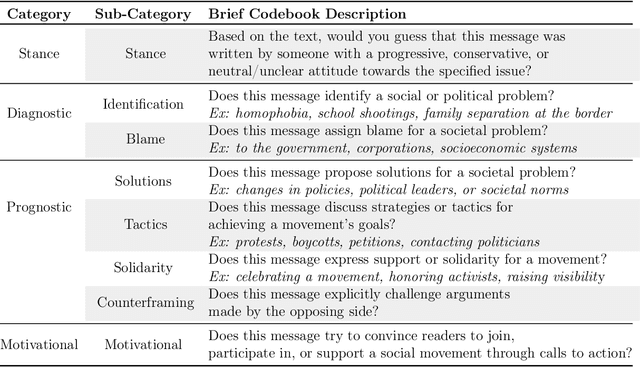
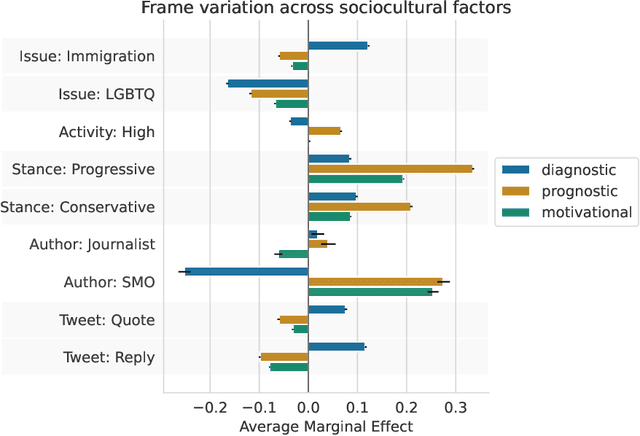
Social media enables activists to directly communicate with the public and provides a space for movement leaders, participants, bystanders, and opponents to collectively construct and contest narratives. Focusing on Twitter messages from social movements surrounding three issues in 2018-2019 (guns, immigration, and LGBTQ rights), we create a codebook, annotated dataset, and computational models to detect diagnostic (problem identification and attribution), prognostic (proposed solutions and tactics), and motivational (calls to action) framing strategies. We conduct an in-depth unsupervised linguistic analysis of each framing strategy, and uncover cross-movement similarities in associations between framing and linguistic features such as pronouns and deontic modal verbs. Finally, we compare framing strategies across issues and other social, cultural, and interactional contexts. For example, we show that diagnostic framing is more common in replies than original broadcast posts, and that social movement organizations focus much more on prognostic and motivational framing than journalists and ordinary citizens.
* Published in ICWSM Special Issue of the Journal of Quantitative Description: Digital Media
How AI Ideas Affect the Creativity, Diversity, and Evolution of Human Ideas: Evidence From a Large, Dynamic Experiment
Jan 24, 2024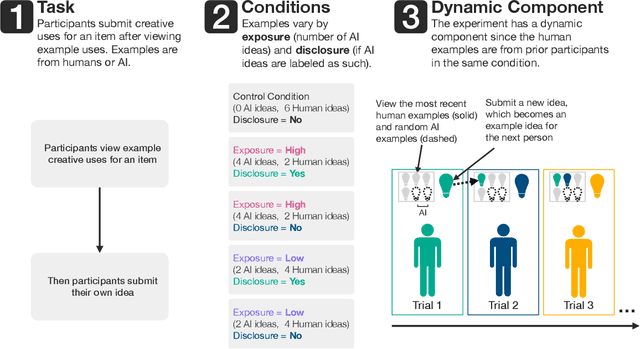
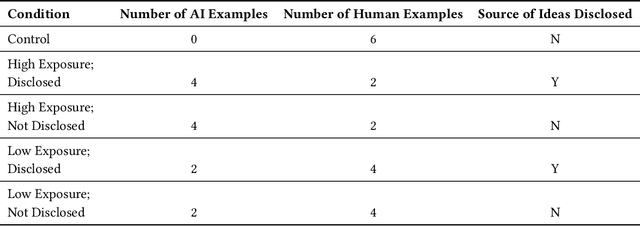


Exposure to large language model output is rapidly increasing. How will seeing AI-generated ideas affect human ideas? We conducted an experiment (800+ participants, 40+ countries) where participants viewed creative ideas that were from ChatGPT or prior experimental participants and then brainstormed their own idea. We varied the number of AI-generated examples (none, low, or high exposure) and if the examples were labeled as 'AI' (disclosure). Our dynamic experiment design -- ideas from prior participants in an experimental condition are used as stimuli for future participants in the same experimental condition -- mimics the interdependent process of cultural creation: creative ideas are built upon prior ideas. Hence, we capture the compounding effects of having LLMs 'in the culture loop'. We find that high AI exposure (but not low AI exposure) did not affect the creativity of individual ideas but did increase the average amount and rate of change of collective idea diversity. AI made ideas different, not better. There were no main effects of disclosure. We also found that self-reported creative people were less influenced by knowing an idea was from AI, and that participants were more likely to knowingly adopt AI ideas when the task was difficult. Our findings suggest that introducing AI ideas into society may increase collective diversity but not individual creativity.
Bridging Nations: Quantifying the Role of Multilinguals in Communication on Social Media
Apr 07, 2023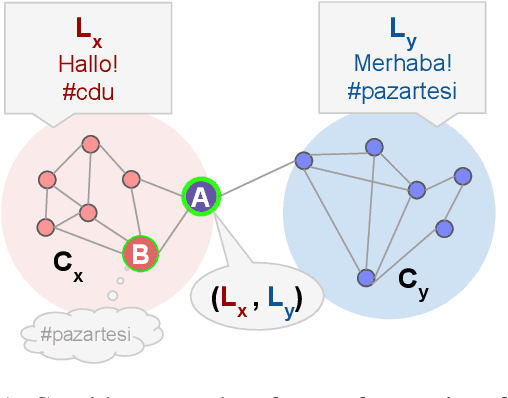
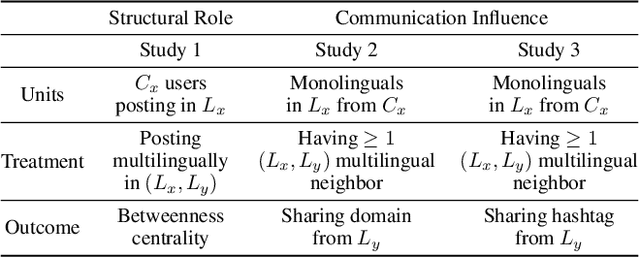

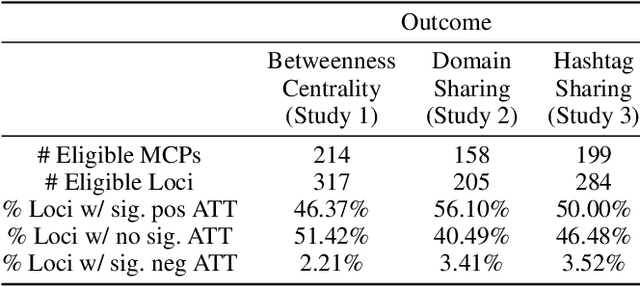
Social media enables the rapid spread of many kinds of information, from memes to social movements. However, little is known about how information crosses linguistic boundaries. We apply causal inference techniques on the European Twitter network to quantify multilingual users' structural role and communication influence in cross-lingual information exchange. Overall, multilinguals play an essential role; posting in multiple languages increases betweenness centrality by 13%, and having a multilingual network neighbor increases monolinguals' odds of sharing domains and hashtags from another language 16-fold and 4-fold, respectively. We further show that multilinguals have a greater impact on diffusing information less accessible to their monolingual compatriots, such as information from far-away countries and content about regional politics, nascent social movements, and job opportunities. By highlighting information exchange across borders, this work sheds light on a crucial component of how information and ideas spread around the world.
Modeling Framing in Immigration Discourse on Social Media
Apr 13, 2021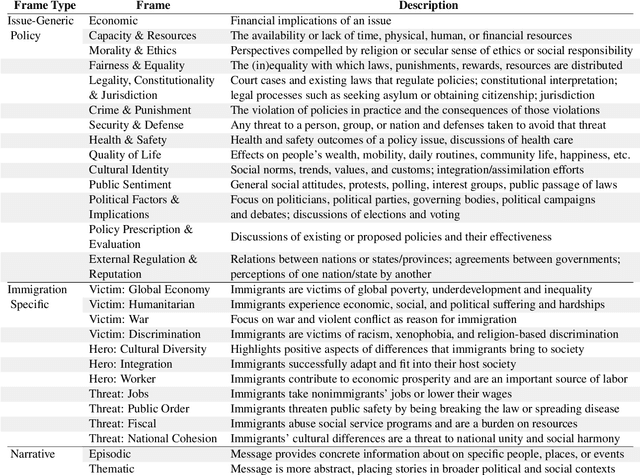
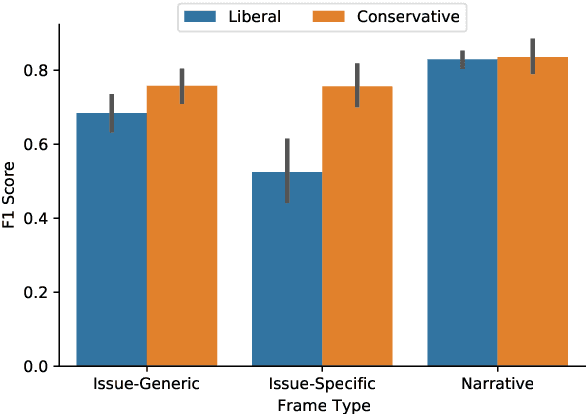
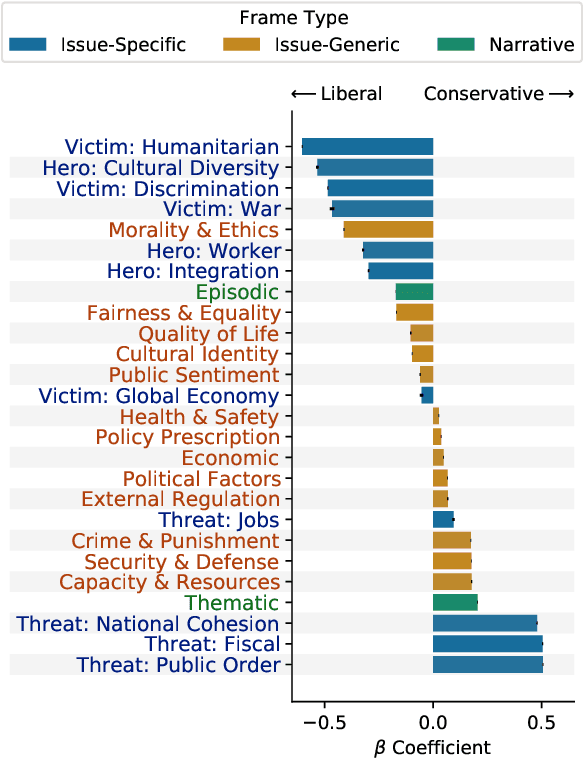

The framing of political issues can influence policy and public opinion. Even though the public plays a key role in creating and spreading frames, little is known about how ordinary people on social media frame political issues. By creating a new dataset of immigration-related tweets labeled for multiple framing typologies from political communication theory, we develop supervised models to detect frames. We demonstrate how users' ideology and region impact framing choices, and how a message's framing influences audience responses. We find that the more commonly-used issue-generic frames obscure important ideological and regional patterns that are only revealed by immigration-specific frames. Furthermore, frames oriented towards human interests, culture, and politics are associated with higher user engagement. This large-scale analysis of a complex social and linguistic phenomenon contributes to both NLP and social science research.