 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePlurals: A System for Guiding LLMs Via Simulated Social Ensembles
Sep 25, 2024
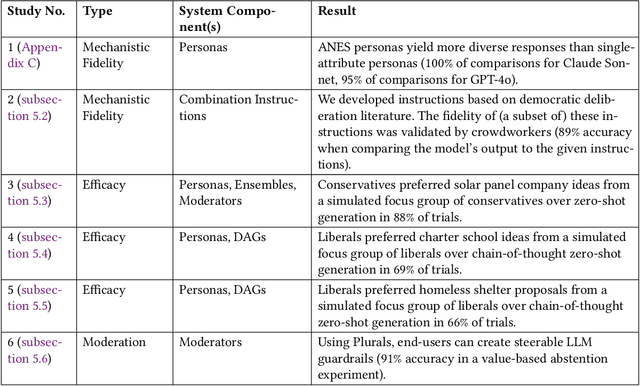
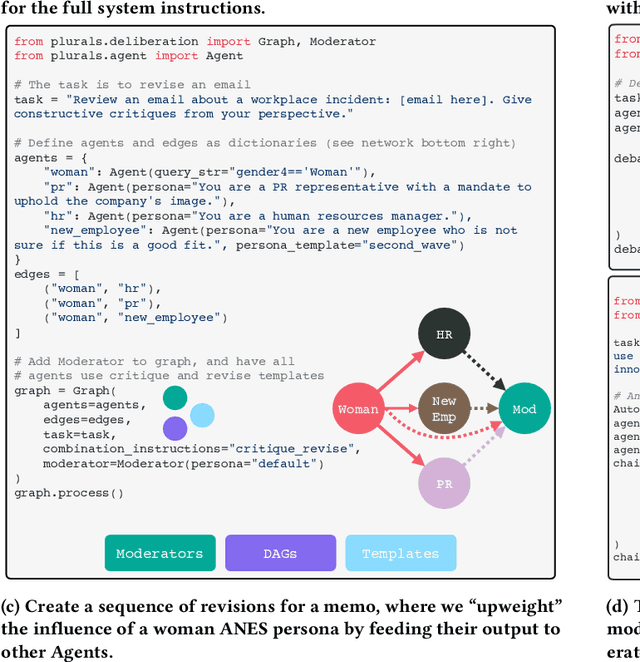
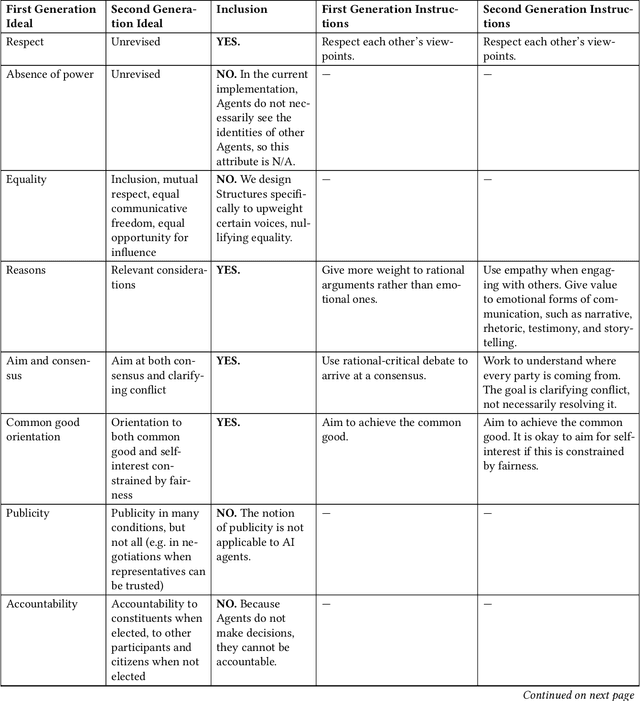
Recent debates raised concerns that language models may favor certain viewpoints. But what if the solution is not to aim for a 'view from nowhere' but rather to leverage different viewpoints? We introduce Plurals, a system and Python library for pluralistic AI deliberation. Plurals consists of Agents (LLMs, optionally with personas) which deliberate within customizable Structures, with Moderators overseeing deliberation. Plurals is a generator of simulated social ensembles. Plurals integrates with government datasets to create nationally representative personas, includes deliberation templates inspired by democratic deliberation theory, and allows users to customize both information-sharing structures and deliberation behavior within Structures. Six case studies demonstrate fidelity to theoretical constructs and efficacy. Three randomized experiments show simulated focus groups produced output resonant with an online sample of the relevant audiences (chosen over zero-shot generation in 75% of trials). Plurals is both a paradigm and a concrete system for pluralistic AI. The Plurals library is available at https://github.com/josh-ashkinaze/plurals and will be continually updated.
Seeing Like an AI: How LLMs Apply (and Misapply) Wikipedia Neutrality Norms
Jul 04, 2024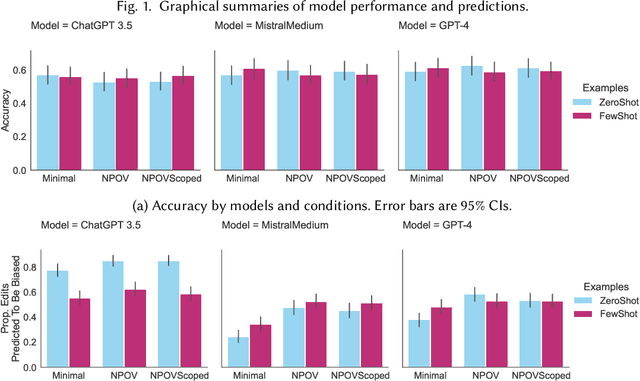
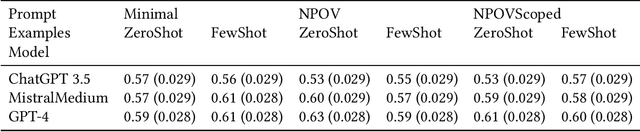
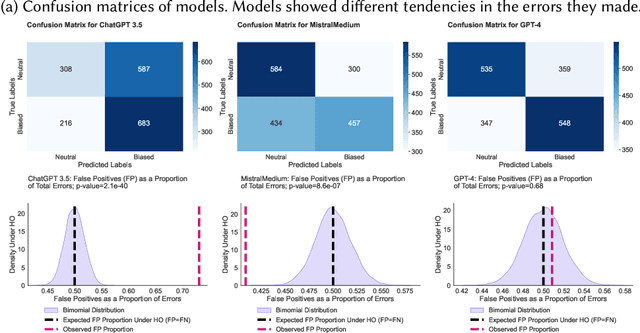
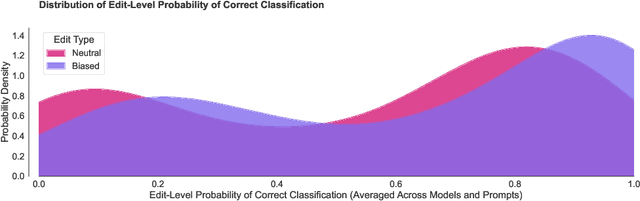
Large language models (LLMs) are trained on broad corpora and then used in communities with specialized norms. Is providing LLMs with community rules enough for models to follow these norms? We evaluate LLMs' capacity to detect (Task 1) and correct (Task 2) biased Wikipedia edits according to Wikipedia's Neutral Point of View (NPOV) policy. LLMs struggled with bias detection, achieving only 64% accuracy on a balanced dataset. Models exhibited contrasting biases (some under- and others over-predicted bias), suggesting distinct priors about neutrality. LLMs performed better at generation, removing 79% of words removed by Wikipedia editors. However, LLMs made additional changes beyond Wikipedia editors' simpler neutralizations, resulting in high-recall but low-precision editing. Interestingly, crowdworkers rated AI rewrites as more neutral (70%) and fluent (61%) than Wikipedia-editor rewrites. Qualitative analysis found LLMs sometimes applied NPOV more comprehensively than Wikipedia editors but often made extraneous non-NPOV-related changes (such as grammar). LLMs may apply rules in ways that resonate with the public but diverge from community experts. While potentially effective for generation, LLMs may reduce editor agency and increase moderation workload (e.g., verifying additions). Even when rules are easy to articulate, having LLMs apply them like community members may still be difficult.
HCC Is All You Need: Alignment-The Sensible Kind Anyway-Is Just Human-Centered Computing
Apr 30, 2024This article argues that AI Alignment is a type of Human-Centered Computing.
How AI Ideas Affect the Creativity, Diversity, and Evolution of Human Ideas: Evidence From a Large, Dynamic Experiment
Jan 24, 2024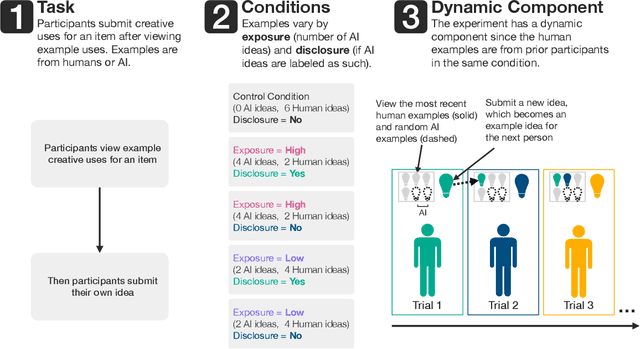
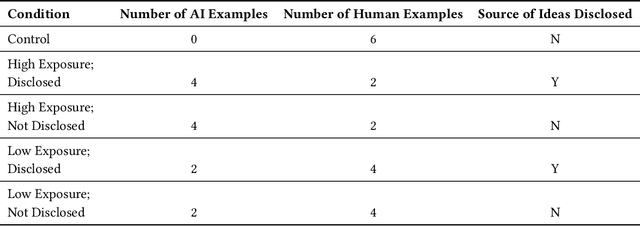


Exposure to large language model output is rapidly increasing. How will seeing AI-generated ideas affect human ideas? We conducted an experiment (800+ participants, 40+ countries) where participants viewed creative ideas that were from ChatGPT or prior experimental participants and then brainstormed their own idea. We varied the number of AI-generated examples (none, low, or high exposure) and if the examples were labeled as 'AI' (disclosure). Our dynamic experiment design -- ideas from prior participants in an experimental condition are used as stimuli for future participants in the same experimental condition -- mimics the interdependent process of cultural creation: creative ideas are built upon prior ideas. Hence, we capture the compounding effects of having LLMs 'in the culture loop'. We find that high AI exposure (but not low AI exposure) did not affect the creativity of individual ideas but did increase the average amount and rate of change of collective idea diversity. AI made ideas different, not better. There were no main effects of disclosure. We also found that self-reported creative people were less influenced by knowing an idea was from AI, and that participants were more likely to knowingly adopt AI ideas when the task was difficult. Our findings suggest that introducing AI ideas into society may increase collective diversity but not individual creativity.
Sensible AI: Re-imagining Interpretability and Explainability using Sensemaking Theory
May 10, 2022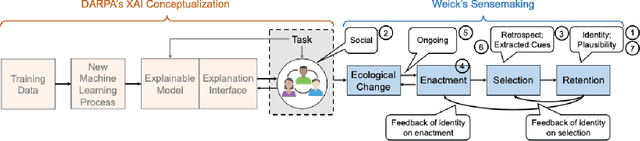


Understanding how ML models work is a prerequisite for responsibly designing, deploying, and using ML-based systems. With interpretability approaches, ML can now offer explanations for its outputs to aid human understanding. Though these approaches rely on guidelines for how humans explain things to each other, they ultimately solve for improving the artifact -- an explanation. In this paper, we propose an alternate framework for interpretability grounded in Weick's sensemaking theory, which focuses on who the explanation is intended for. Recent work has advocated for the importance of understanding stakeholders' needs -- we build on this by providing concrete properties (e.g., identity, social context, environmental cues, etc.) that shape human understanding. We use an application of sensemaking in organizations as a template for discussing design guidelines for Sensible AI, AI that factors in the nuances of human cognition when trying to explain itself.