 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Expert Schema for Evaluating Large Language Model Errors in Scholarly Question-Answering Systems
Feb 24, 2026Large Language Models (LLMs) are transforming scholarly tasks like search and summarization, but their reliability remains uncertain. Current evaluation metrics for testing LLM reliability are primarily automated approaches that prioritize efficiency and scalability, but lack contextual nuance and fail to reflect how scientific domain experts assess LLM outputs in practice. We developed and validated a schema for evaluating LLM errors in scholarly question-answering systems that reflects the assessment strategies of practicing scientists. In collaboration with domain experts, we identified 20 error patterns across seven categories through thematic analysis of 68 question-answer pairs. We validated this schema through contextual inquiries with 10 additional scientists, which showed not only which errors experts naturally identify but also how structured evaluation schemas can help them detect previously overlooked issues. Domain experts use systematic assessment strategies, including technical precision testing, value-based evaluation, and meta-evaluation of their own practices. We discuss implications for supporting expert evaluation of LLM outputs, including opportunities for personalized, schema-driven tools that adapt to individual evaluation patterns and expertise levels.
PaperTrail: A Claim-Evidence Interface for Grounding Provenance in LLM-based Scholarly Q&A
Feb 24, 2026Large language models (LLMs) are increasingly used in scholarly question-answering (QA) systems to help researchers synthesize vast amounts of literature. However, these systems often produce subtle errors (e.g., unsupported claims, errors of omission), and current provenance mechanisms like source citations are not granular enough for the rigorous verification that scholarly domain requires. To address this, we introduce PaperTrail, a novel interface that decomposes both LLM answers and source documents into discrete claims and evidence, mapping them to reveal supported assertions, unsupported claims, and information omitted from the source texts. We evaluated PaperTrail in a within-subjects study with 26 researchers who performed two scholarly editing tasks using PaperTrail and a baseline interface. Our results show that PaperTrail significantly lowered participants' trust compared to the baseline. However, this increased caution did not translate to behavioral changes, as people continued to rely on LLM-generated scholarly edits to avoid a cognitively burdensome task. We discuss the value of claim-evidence matching for understanding LLM trustworthiness in scholarly settings, and present design implications for cognition-friendly communication of provenance information.
FeedLens: Polymorphic Lenses for Personalizing Exploratory Search over Knowledge Graphs
Aug 16, 2022
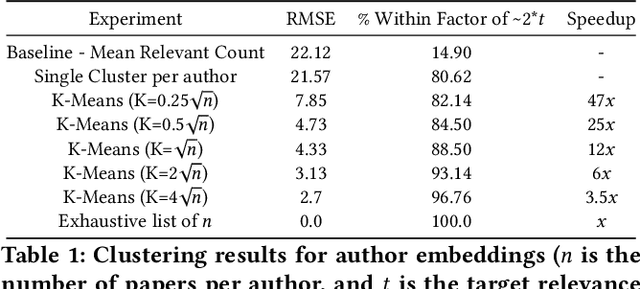

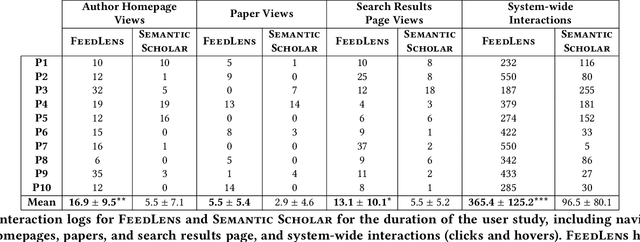
The vast scale and open-ended nature of knowledge graphs (KGs) make exploratory search over them cognitively demanding for users. We introduce a new technique, polymorphic lenses, that improves exploratory search over a KG by obtaining new leverage from the existing preference models that KG-based systems maintain for recommending content. The approach is based on a simple but powerful observation: in a KG, preference models can be re-targeted to recommend not only entities of a single base entity type (e.g., papers in the scientific literature KG, products in an e-commerce KG), but also all other types (e.g., authors, conferences, institutions; sellers, buyers). We implement our technique in a novel system, FeedLens, which is built over Semantic Scholar, a production system for navigating the scientific literature KG. FeedLens reuses the existing preference models on Semantic Scholar -- people's curated research feeds -- as lenses for exploratory search. Semantic Scholar users can curate multiple feeds/lenses for different topics of interest, e.g., one for human-centered AI and another for document embeddings. Although these lenses are defined in terms of papers, FeedLens re-purposes them to also guide search over authors, institutions, venues, etc. Our system design is based on feedback from intended users via two pilot surveys (n=17 and n=13, respectively). We compare FeedLens and Semantic Scholar via a third (within-subjects) user study (n=15) and find that FeedLens increases user engagement while reducing the cognitive effort required to complete a short literature review task. Our qualitative results also highlight people's preference for this more effective exploratory search experience enabled by FeedLens.
Sensible AI: Re-imagining Interpretability and Explainability using Sensemaking Theory
May 10, 2022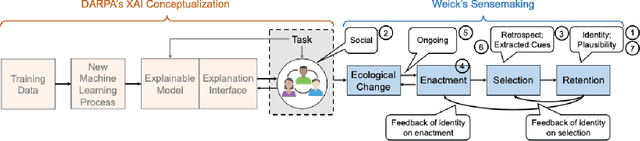

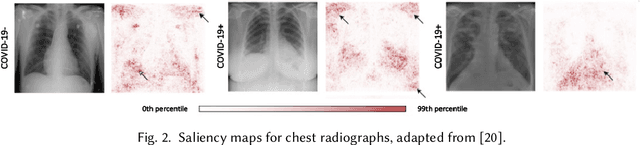

Understanding how ML models work is a prerequisite for responsibly designing, deploying, and using ML-based systems. With interpretability approaches, ML can now offer explanations for its outputs to aid human understanding. Though these approaches rely on guidelines for how humans explain things to each other, they ultimately solve for improving the artifact -- an explanation. In this paper, we propose an alternate framework for interpretability grounded in Weick's sensemaking theory, which focuses on who the explanation is intended for. Recent work has advocated for the importance of understanding stakeholders' needs -- we build on this by providing concrete properties (e.g., identity, social context, environmental cues, etc.) that shape human understanding. We use an application of sensemaking in organizations as a template for discussing design guidelines for Sensible AI, AI that factors in the nuances of human cognition when trying to explain itself.
A Human-Centered Interpretability Framework Based on Weight of Evidence
Apr 27, 2021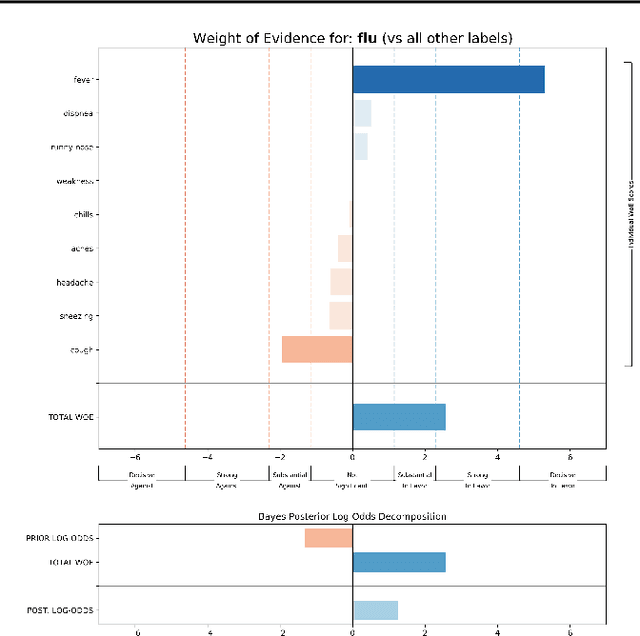
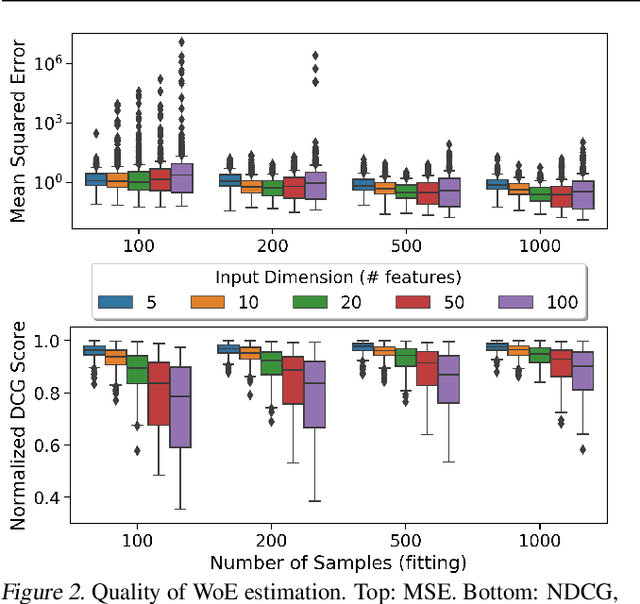
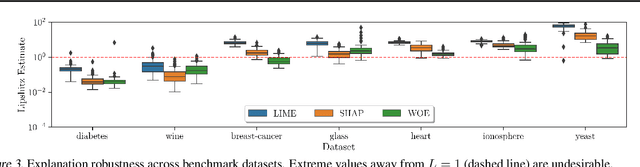
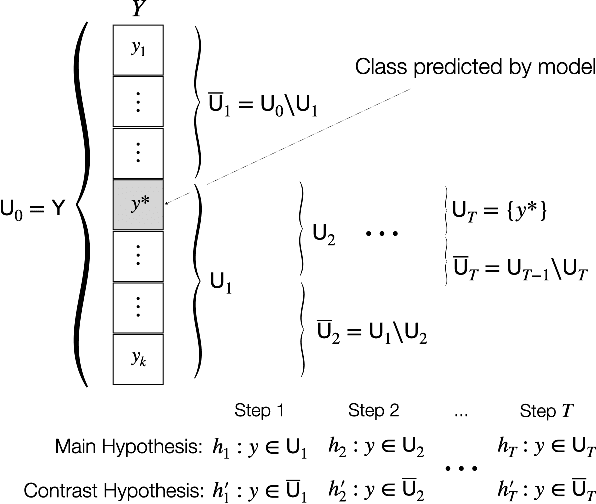
In this paper, we take a human-centered approach to interpretable machine learning. First, drawing inspiration from the study of explanation in philosophy, cognitive science, and the social sciences, we propose a list of design principles for machine-generated explanations that are meaningful to humans. Using the concept of weight of evidence from information theory, we develop a method for producing explanations that adhere to these principles. We show that this method can be adapted to handle high-dimensional, multi-class settings, yielding a flexible meta-algorithm for generating explanations. We demonstrate that these explanations can be estimated accurately from finite samples and are robust to small perturbations of the inputs. We also evaluate our method through a qualitative user study with machine learning practitioners, where we observe that the resulting explanations are usable despite some participants struggling with background concepts like prior class probabilities. Finally, we conclude by surfacing design implications for interpretability tools