 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLMs as Research Tools: A Large Scale Survey of Researchers' Usage and Perceptions
Oct 30, 2024



The rise of large language models (LLMs) has led many researchers to consider their usage for scientific work. Some have found benefits using LLMs to augment or automate aspects of their research pipeline, while others have urged caution due to risks and ethical concerns. Yet little work has sought to quantify and characterize how researchers use LLMs and why. We present the first large-scale survey of 816 verified research article authors to understand how the research community leverages and perceives LLMs as research tools. We examine participants' self-reported LLM usage, finding that 81% of researchers have already incorporated LLMs into different aspects of their research workflow. We also find that traditionally disadvantaged groups in academia (non-White, junior, and non-native English speaking researchers) report higher LLM usage and perceived benefits, suggesting potential for improved research equity. However, women, non-binary, and senior researchers have greater ethical concerns, potentially hindering adoption.
The Semantic Reader Project: Augmenting Scholarly Documents through AI-Powered Interactive Reading Interfaces
Mar 25, 2023



Scholarly publications are key to the transfer of knowledge from scholars to others. However, research papers are information-dense, and as the volume of the scientific literature grows, the need for new technology to support the reading process grows. In contrast to the process of finding papers, which has been transformed by Internet technology, the experience of reading research papers has changed little in decades. The PDF format for sharing research papers is widely used due to its portability, but it has significant downsides including: static content, poor accessibility for low-vision readers, and difficulty reading on mobile devices. This paper explores the question "Can recent advances in AI and HCI power intelligent, interactive, and accessible reading interfaces -- even for legacy PDFs?" We describe the Semantic Reader Project, a collaborative effort across multiple institutions to explore automatic creation of dynamic reading interfaces for research papers. Through this project, we've developed ten research prototype interfaces and conducted usability studies with more than 300 participants and real-world users showing improved reading experiences for scholars. We've also released a production reading interface for research papers that will incorporate the best features as they mature. We structure this paper around challenges scholars and the public face when reading research papers -- Discovery, Efficiency, Comprehension, Synthesis, and Accessibility -- and present an overview of our progress and remaining open challenges.
FeedLens: Polymorphic Lenses for Personalizing Exploratory Search over Knowledge Graphs
Aug 16, 2022

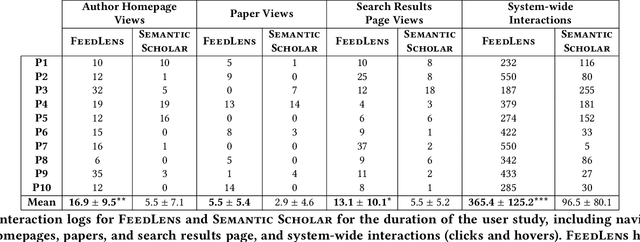
The vast scale and open-ended nature of knowledge graphs (KGs) make exploratory search over them cognitively demanding for users. We introduce a new technique, polymorphic lenses, that improves exploratory search over a KG by obtaining new leverage from the existing preference models that KG-based systems maintain for recommending content. The approach is based on a simple but powerful observation: in a KG, preference models can be re-targeted to recommend not only entities of a single base entity type (e.g., papers in the scientific literature KG, products in an e-commerce KG), but also all other types (e.g., authors, conferences, institutions; sellers, buyers). We implement our technique in a novel system, FeedLens, which is built over Semantic Scholar, a production system for navigating the scientific literature KG. FeedLens reuses the existing preference models on Semantic Scholar -- people's curated research feeds -- as lenses for exploratory search. Semantic Scholar users can curate multiple feeds/lenses for different topics of interest, e.g., one for human-centered AI and another for document embeddings. Although these lenses are defined in terms of papers, FeedLens re-purposes them to also guide search over authors, institutions, venues, etc. Our system design is based on feedback from intended users via two pilot surveys (n=17 and n=13, respectively). We compare FeedLens and Semantic Scholar via a third (within-subjects) user study (n=15) and find that FeedLens increases user engagement while reducing the cognitive effort required to complete a short literature review task. Our qualitative results also highlight people's preference for this more effective exploratory search experience enabled by FeedLens.