 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDRACULA: Hunting for the Actions Users Want Deep Research Agents to Execute
Apr 26, 2026Scientific Deep Research (DR) agents answer user queries by synthesizing research papers into multi-section reports. User feedback can improve their utility, but existing protocols only score the final report, making it hard to study and learn which intermediate actions DR agents should take to improve reports. We collect DRACULA, the first dataset with user feedback on intermediate actions for DR. Over five weeks, nineteen expert CS researchers ask queries to a DR system that proposes actions (e.g., "Add a section on datasets"). Our users select actions they prefer, then judge whether an output report applied their selections successfully, yielding 8,103 action preferences and 5,230 execution judgments. After confirming a DR agent can execute DRACULA's actions, we study the predictability of user-preferred actions via simulation-how well LLMs predict the actions users select-a step toward learning to generate useful actions. We discover: (1) LLM judges initially struggle to predict action selections, but improve most when using a user's full selection history, rather than self-reported or extrapolated user context signals; (2) Users' selections for the same query differ based on unstated goals, bottlenecking simulation and motivating affordances that let users steer reports; and (3) Our simulation results inform an online intervention that generates new actions based on the user's past interactions, which users pick most often in follow-up studies. Overall, while work extensively studies execution, DRACULA reveals a key challenge is deciding which actions to execute in the first place. We open-source DRACULA's study design, user feedback, and simulation tasks to spur future work on action feedback for long-horizon agents.
LitPivot: Developing Well-Situated Research Ideas Through Dynamic Contextualization and Critique within the Literature Landscape
Apr 03, 2026Developing a novel research idea is hard. It must be distinct enough from prior work to claim a contribution while also building on it. This requires iteratively reviewing literature and refining an idea based on what a researcher reads; yet when an idea changes, the literature that matters often changes with it. Most tools offer limited support for this interplay: literature tools help researchers understand a fixed body of work, while ideation tools evaluate ideas against a static, pre-curated set of papers. We introduce literature-initiated pivots, a mechanism where engagement with literature prompts revision to a developing idea, and where that revision changes which literature is relevant. We operationalize this in LitPivot, where researchers concurrently draft and vet an idea. LitPivot dynamically retrieves clusters of papers relevant to a selected part of the idea and proposes literature-informed critiques for how to revise it. A lab study ($n{=}17$) shows researchers produced higher-rated ideas with stronger self-reported understanding of the literature space; an open-ended study ($n{=}5$) reveals how researchers use LitPivot to iteratively evolve their own ideas.
Improving Attributed Long-form Question Answering with Intent Awareness
Mar 28, 2026Large language models (LLMs) are increasingly being used to generate comprehensive, knowledge-intensive reports. However, while these models are trained on diverse academic papers and reports, they are not exposed to the reasoning processes and intents that guide authors in crafting these documents. We hypothesize that enhancing a model's intent awareness can significantly improve the quality of generated long-form reports. We develop and employ structured, tag-based schemes to better elicit underlying implicit intents to write or cite. We demonstrate that these extracted intents enhance both zero-shot generation capabilities in LLMs and enable the creation of high-quality synthetic data for fine-tuning smaller models. Our experiments reveal improved performance across various challenging scientific report generation tasks, with an average improvement of +2.9 and +12.3 absolute points for large and small models over baselines, respectively. Furthermore, our analysis illuminates how intent awareness enhances model citation usage and substantially improves report readability.
* 39 pages, 7 figures
Language Models Don't Know What You Want: Evaluating Personalization in Deep Research Needs Real Users
Mar 17, 2026Deep Research (DR) tools (e.g. OpenAI DR) help researchers cope with ballooning publishing counts. Such tools can synthesize scientific papers to answer researchers' queries, but lack understanding of their users. We change that in MyScholarQA (MySQA), a personalized DR tool that: 1) infers a profile of a user's research interests; 2) proposes personalized actions for a user's input query; and 3) writes a multi-section report for the query that follows user-approved actions. We first test MySQA with NLP's standard protocol: we design a benchmark of synthetic users and LLM judges, where MySQA beats baselines in citation metrics and personalized action-following. However, we suspect this process does not cover all aspects of personalized DR users value, so we interview users in an online version of MySQA to unmask them. We reveal nine nuanced errors of personalized DR undetectable by our LLM judges, and we study qualitative feedback to form lessons for future DR design. In all, we argue for a pillar of personalization that easy-to-use LLM judges can lead NLP to overlook: real progress in personalization is only possible with real users.
Understanding Usage and Engagement in AI-Powered Scientific Research Tools: The Asta Interaction Dataset
Feb 26, 2026AI-powered scientific research tools are rapidly being integrated into research workflows, yet the field lacks a clear lens into how researchers use these systems in real-world settings. We present and analyze the Asta Interaction Dataset, a large-scale resource comprising over 200,000 user queries and interaction logs from two deployed tools (a literature discovery interface and a scientific question-answering interface) within an LLM-powered retrieval-augmented generation platform. Using this dataset, we characterize query patterns, engagement behaviors, and how usage evolves with experience. We find that users submit longer and more complex queries than in traditional search, and treat the system as a collaborative research partner, delegating tasks such as drafting content and identifying research gaps. Users treat generated responses as persistent artifacts, revisiting and navigating among outputs and cited evidence in non-linear ways. With experience, users issue more targeted queries and engage more deeply with supporting citations, although keyword-style queries persist even among experienced users. We release the anonymized dataset and analysis with a new query intent taxonomy to inform future designs of real-world AI research assistants and to support realistic evaluation.
Penalizing Transparency? How AI Disclosure and Author Demographics Shape Human and AI Judgments About Writing
Jul 02, 2025


As AI integrates in various types of human writing, calls for transparency around AI assistance are growing. However, if transparency operates on uneven ground and certain identity groups bear a heavier cost for being honest, then the burden of openness becomes asymmetrical. This study investigates how AI disclosure statement affects perceptions of writing quality, and whether these effects vary by the author's race and gender. Through a large-scale controlled experiment, both human raters (n = 1,970) and LLM raters (n = 2,520) evaluated a single human-written news article while disclosure statements and author demographics were systematically varied. This approach reflects how both human and algorithmic decisions now influence access to opportunities (e.g., hiring, promotion) and social recognition (e.g., content recommendation algorithms). We find that both human and LLM raters consistently penalize disclosed AI use. However, only LLM raters exhibit demographic interaction effects: they favor articles attributed to women or Black authors when no disclosure is present. But these advantages disappear when AI assistance is revealed. These findings illuminate the complex relationships between AI disclosure and author identity, highlighting disparities between machine and human evaluation patterns.
SciArena: An Open Evaluation Platform for Foundation Models in Scientific Literature Tasks
Jul 01, 2025
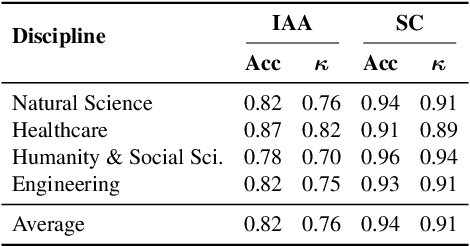

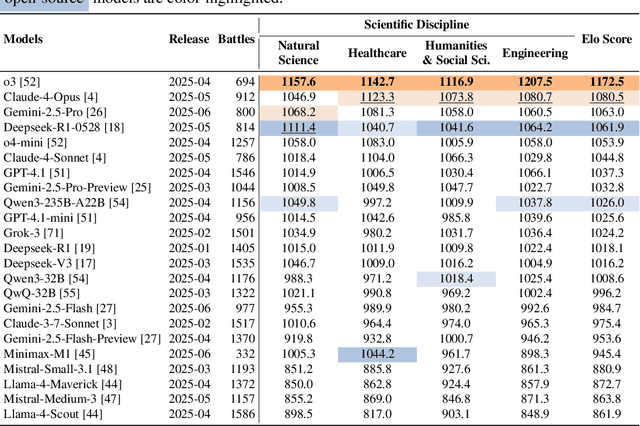
We present SciArena, an open and collaborative platform for evaluating foundation models on scientific literature tasks. Unlike traditional benchmarks for scientific literature understanding and synthesis, SciArena engages the research community directly, following the Chatbot Arena evaluation approach of community voting on model comparisons. By leveraging collective intelligence, SciArena offers a community-driven evaluation of model performance on open-ended scientific tasks that demand literature-grounded, long-form responses. The platform currently supports 23 open-source and proprietary foundation models and has collected over 13,000 votes from trusted researchers across diverse scientific domains. We analyze the data collected so far and confirm that the submitted questions are diverse, aligned with real-world literature needs, and that participating researchers demonstrate strong self-consistency and inter-annotator agreement in their evaluations. We discuss the results and insights based on the model ranking leaderboard. To further promote research in building model-based automated evaluation systems for literature tasks, we release SciArena-Eval, a meta-evaluation benchmark based on our collected preference data. The benchmark measures the accuracy of models in judging answer quality by comparing their pairwise assessments with human votes. Our experiments highlight the benchmark's challenges and emphasize the need for more reliable automated evaluation methods.
Ai2 Scholar QA: Organized Literature Synthesis with Attribution
Apr 15, 2025Retrieval-augmented generation is increasingly effective in answering scientific questions from literature, but many state-of-the-art systems are expensive and closed-source. We introduce Ai2 Scholar QA, a free online scientific question answering application. To facilitate research, we make our entire pipeline public: as a customizable open-source Python package and interactive web app, along with paper indexes accessible through public APIs and downloadable datasets. We describe our system in detail and present experiments analyzing its key design decisions. In an evaluation on a recent scientific QA benchmark, we find that Ai2 Scholar QA outperforms competing systems.
Cocoa: Co-Planning and Co-Execution with AI Agents
Dec 14, 2024



We present Cocoa, a system that implements a novel interaction design pattern -- interactive plans -- for users to collaborate with an AI agent on complex, multi-step tasks in a document editor. Cocoa harmonizes human and AI efforts and enables flexible delegation of agency through two actions: Co-planning (where users collaboratively compose a plan of action with the agent) and Co-execution (where users collaboratively execute plan steps with the agent). Using scientific research as a sample domain, we motivate the design of Cocoa through a formative study with 9 researchers while also drawing inspiration from the design of computational notebooks. We evaluate Cocoa through a user study with 16 researchers and find that when compared to a strong chat baseline, Cocoa improved agent steerability without sacrificing ease of use. A deeper investigation of the general utility of both systems uncovered insights into usage contexts where interactive plans may be more appropriate than chat, and vice versa. Our work surfaces numerous practical implications and paves new paths for interactive interfaces that foster more effective collaboration between humans and agentic AI systems.
OpenScholar: Synthesizing Scientific Literature with Retrieval-augmented LMs
Nov 21, 2024



Scientific progress depends on researchers' ability to synthesize the growing body of literature. Can large language models (LMs) assist scientists in this task? We introduce OpenScholar, a specialized retrieval-augmented LM that answers scientific queries by identifying relevant passages from 45 million open-access papers and synthesizing citation-backed responses. To evaluate OpenScholar, we develop ScholarQABench, the first large-scale multi-domain benchmark for literature search, comprising 2,967 expert-written queries and 208 long-form answers across computer science, physics, neuroscience, and biomedicine. On ScholarQABench, OpenScholar-8B outperforms GPT-4o by 5% and PaperQA2 by 7% in correctness, despite being a smaller, open model. While GPT4o hallucinates citations 78 to 90% of the time, OpenScholar achieves citation accuracy on par with human experts. OpenScholar's datastore, retriever, and self-feedback inference loop also improves off-the-shelf LMs: for instance, OpenScholar-GPT4o improves GPT-4o's correctness by 12%. In human evaluations, experts preferred OpenScholar-8B and OpenScholar-GPT4o responses over expert-written ones 51% and 70% of the time, respectively, compared to GPT4o's 32%. We open-source all of our code, models, datastore, data and a public demo.