 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOptimizing Diversity and Quality through Base-Aligned Model Collaboration
Nov 07, 2025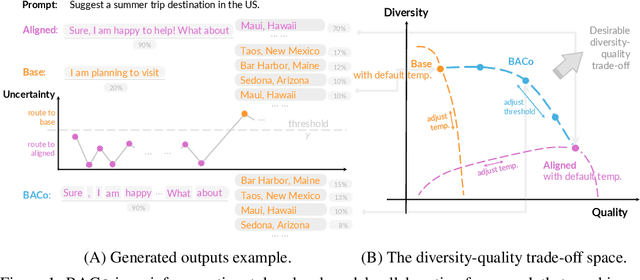
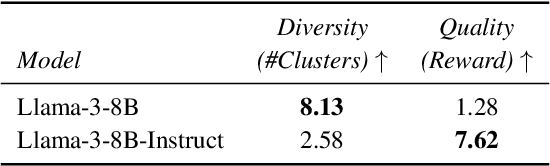
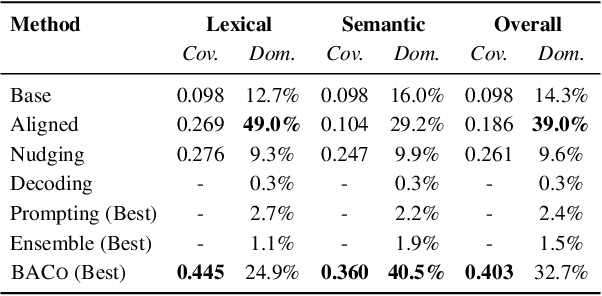
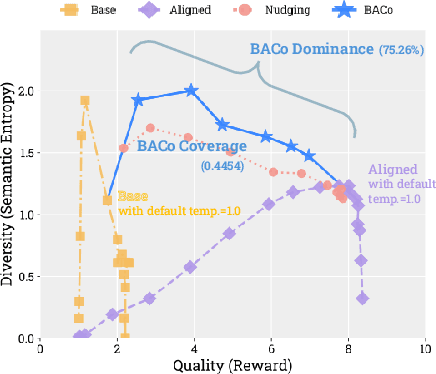
Alignment has greatly improved large language models (LLMs)' output quality at the cost of diversity, yielding highly similar outputs across generations. We propose Base-Aligned Model Collaboration (BACo), an inference-time token-level model collaboration framework that dynamically combines a base LLM with its aligned counterpart to optimize diversity and quality. Inspired by prior work (Fei et al., 2025), BACo employs routing strategies that determine, at each token, from which model to decode based on next-token prediction uncertainty and predicted contents' semantic role. Prior diversity-promoting methods, such as retraining, prompt engineering, and multi-sampling methods, improve diversity but often degrade quality or require costly decoding or post-training. In contrast, BACo achieves both high diversity and quality post hoc within a single pass, while offering strong controllability. We explore a family of routing strategies, across three open-ended generation tasks and 13 metrics covering diversity and quality, BACo consistently surpasses state-of-the-art inference-time baselines. With our best router, BACo achieves a 21.3% joint improvement in diversity and quality. Human evaluations also mirror these improvements. The results suggest that collaboration between base and aligned models can optimize and control diversity and quality.
Understanding, Protecting, and Augmenting Human Cognition with Generative AI: A Synthesis of the CHI 2025 Tools for Thought Workshop
Aug 28, 2025Generative AI (GenAI) radically expands the scope and capability of automation for work, education, and everyday tasks, a transformation posing both risks and opportunities for human cognition. How will human cognition change, and what opportunities are there for GenAI to augment it? Which theories, metrics, and other tools are needed to address these questions? The CHI 2025 workshop on Tools for Thought aimed to bridge an emerging science of how the use of GenAI affects human thought, from metacognition to critical thinking, memory, and creativity, with an emerging design practice for building GenAI tools that both protect and augment human thought. Fifty-six researchers, designers, and thinkers from across disciplines as well as industry and academia, along with 34 papers and portfolios, seeded a day of discussion, ideation, and community-building. We synthesize this material here to begin mapping the space of research and design opportunities and to catalyze a multidisciplinary community around this pressing area of research.
Penalizing Transparency? How AI Disclosure and Author Demographics Shape Human and AI Judgments About Writing
Jul 02, 2025


As AI integrates in various types of human writing, calls for transparency around AI assistance are growing. However, if transparency operates on uneven ground and certain identity groups bear a heavier cost for being honest, then the burden of openness becomes asymmetrical. This study investigates how AI disclosure statement affects perceptions of writing quality, and whether these effects vary by the author's race and gender. Through a large-scale controlled experiment, both human raters (n = 1,970) and LLM raters (n = 2,520) evaluated a single human-written news article while disclosure statements and author demographics were systematically varied. This approach reflects how both human and algorithmic decisions now influence access to opportunities (e.g., hiring, promotion) and social recognition (e.g., content recommendation algorithms). We find that both human and LLM raters consistently penalize disclosed AI use. However, only LLM raters exhibit demographic interaction effects: they favor articles attributed to women or Black authors when no disclosure is present. But these advantages disappear when AI assistance is revealed. These findings illuminate the complex relationships between AI disclosure and author identity, highlighting disparities between machine and human evaluation patterns.
Unraveling Misinformation Propagation in LLM Reasoning
May 24, 2025



Large Language Models (LLMs) have demonstrated impressive capabilities in reasoning, positioning them as promising tools for supporting human problem-solving. However, what happens when their performance is affected by misinformation, i.e., incorrect inputs introduced by users due to oversights or gaps in knowledge? Such misinformation is prevalent in real-world interactions with LLMs, yet how it propagates within LLMs' reasoning process remains underexplored. Focusing on mathematical reasoning, we present a comprehensive analysis of how misinformation affects intermediate reasoning steps and final answers. We also examine how effectively LLMs can correct misinformation when explicitly instructed to do so. Even with explicit instructions, LLMs succeed less than half the time in rectifying misinformation, despite possessing correct internal knowledge, leading to significant accuracy drops (10.02% - 72.20%). Further analysis shows that applying factual corrections early in the reasoning process most effectively reduces misinformation propagation, and fine-tuning on synthesized data with early-stage corrections significantly improves reasoning factuality. Our work offers a practical approach to mitigating misinformation propagation.
How Problematic Writer-AI Interactions (Rather than Problematic AI) Hinder Writers' Idea Generation
Mar 14, 2025



Writing about a subject enriches writers' understanding of that subject. This cognitive benefit of writing -- known as constructive learning -- is essential to how students learn in various disciplines. However, does this benefit persist when students write with generative AI writing assistants? Prior research suggests the answer varies based on the type of AI, e.g., auto-complete systems tend to hinder ideation, while assistants that pose Socratic questions facilitate it. This paper adds an additional perspective. Through a case study, we demonstrate that the impact of genAI on students' idea development depends not only on the AI but also on the students and, crucially, their interactions in between. Students who proactively explored ideas gained new ideas from writing, regardless of whether they used auto-complete or Socratic AI assistants. Those who engaged in prolonged, mindless copyediting developed few ideas even with a Socratic AI. These findings suggest opportunities in designing AI writing assistants, not merely by creating more thought-provoking AI, but also by fostering more thought-provoking writer-AI interactions.
Building Machines that Learn and Think with People
Jul 22, 2024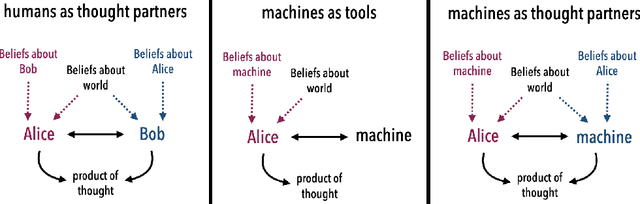
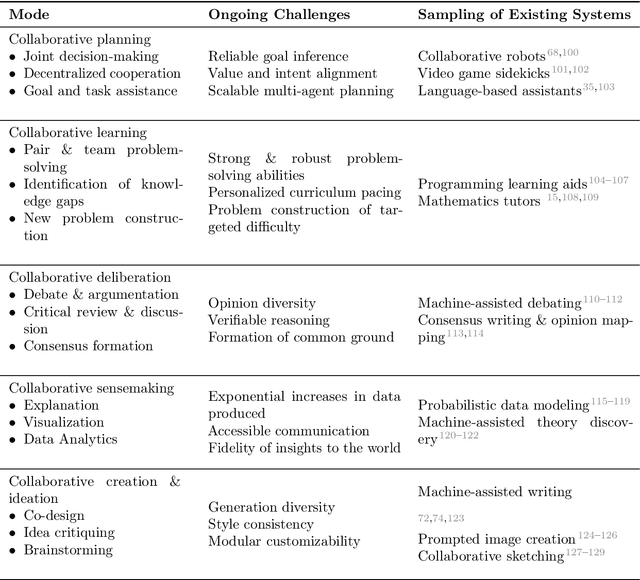
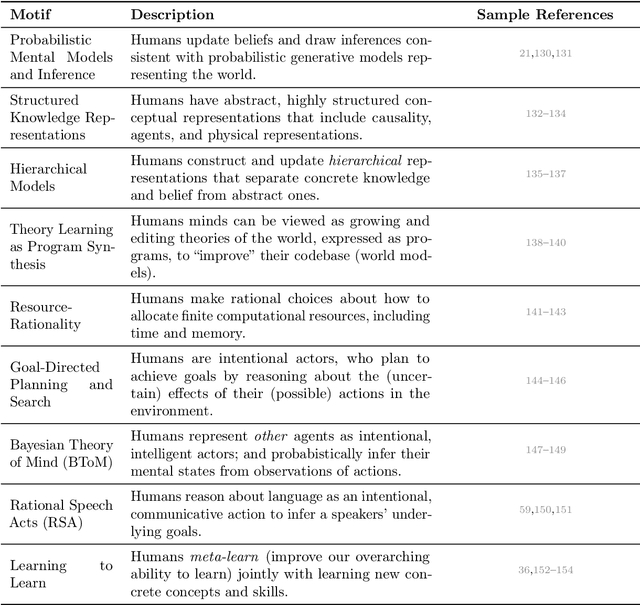
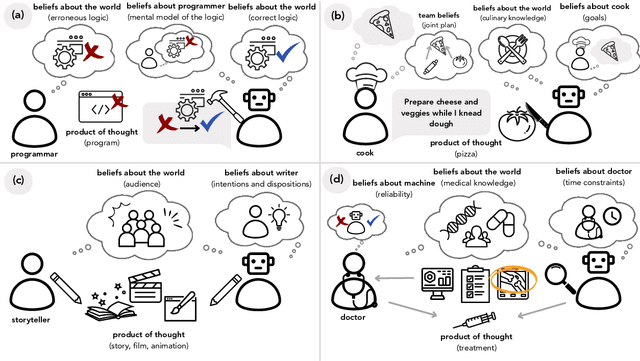
What do we want from machine intelligence? We envision machines that are not just tools for thought, but partners in thought: reasonable, insightful, knowledgeable, reliable, and trustworthy systems that think with us. Current artificial intelligence (AI) systems satisfy some of these criteria, some of the time. In this Perspective, we show how the science of collaborative cognition can be put to work to engineer systems that really can be called ``thought partners,'' systems built to meet our expectations and complement our limitations. We lay out several modes of collaborative thought in which humans and AI thought partners can engage and propose desiderata for human-compatible thought partnerships. Drawing on motifs from computational cognitive science, we motivate an alternative scaling path for the design of thought partners and ecosystems around their use through a Bayesian lens, whereby the partners we construct actively build and reason over models of the human and world.
A Design Space for Intelligent and Interactive Writing Assistants
Mar 26, 2024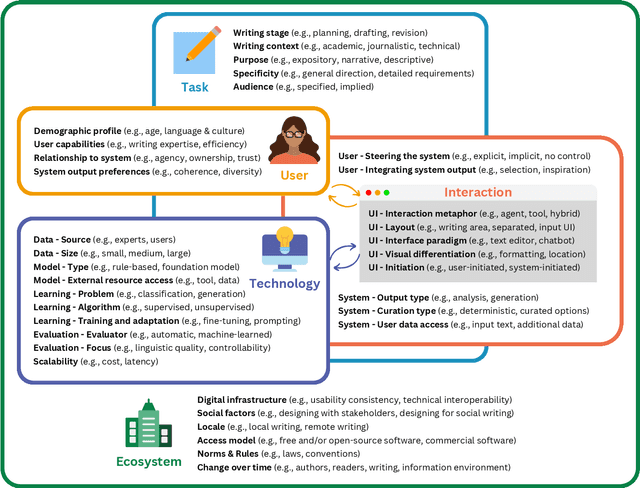
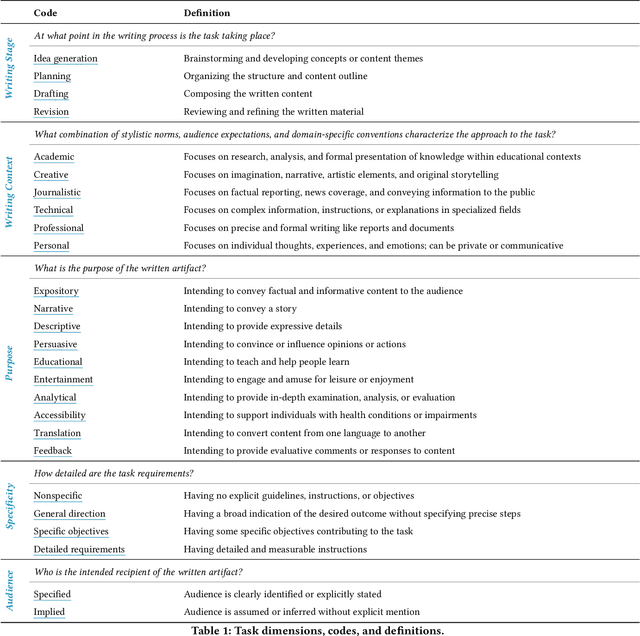
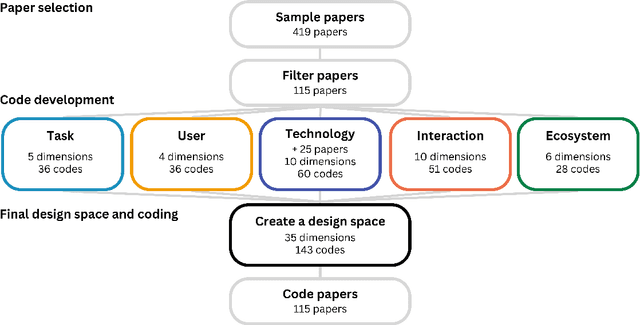
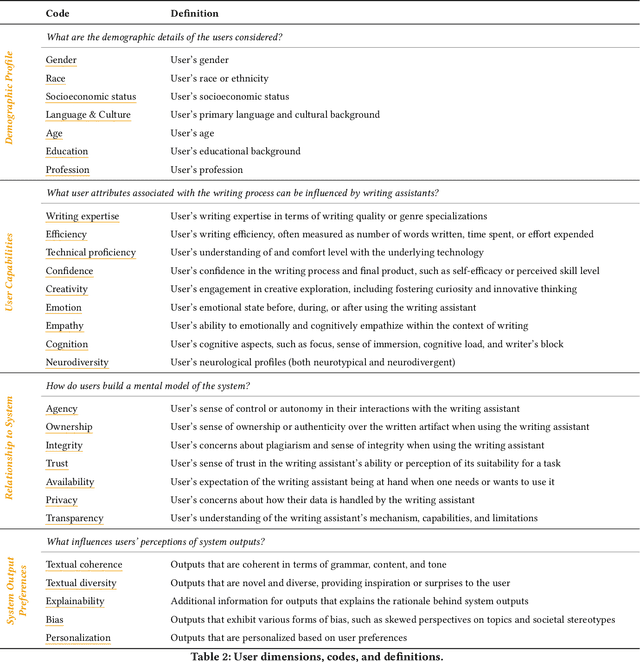
In our era of rapid technological advancement, the research landscape for writing assistants has become increasingly fragmented across various research communities. We seek to address this challenge by proposing a design space as a structured way to examine and explore the multidimensional space of intelligent and interactive writing assistants. Through a large community collaboration, we explore five aspects of writing assistants: task, user, technology, interaction, and ecosystem. Within each aspect, we define dimensions (i.e., fundamental components of an aspect) and codes (i.e., potential options for each dimension) by systematically reviewing 115 papers. Our design space aims to offer researchers and designers a practical tool to navigate, comprehend, and compare the various possibilities of writing assistants, and aid in the envisioning and design of new writing assistants.
Towards Explainable AI Writing Assistants for Non-native English Speakers
Apr 05, 2023



We highlight the challenges faced by non-native speakers when using AI writing assistants to paraphrase text. Through an interview study with 15 non-native English speakers (NNESs) with varying levels of English proficiency, we observe that they face difficulties in assessing paraphrased texts generated by AI writing assistants, largely due to the lack of explanations accompanying the suggested paraphrases. Furthermore, we examine their strategies to assess AI-generated texts in the absence of such explanations. Drawing on the needs of NNESs identified in our interview, we propose four potential user interfaces to enhance the writing experience of NNESs using AI writing assistants. The proposed designs focus on incorporating explanations to better support NNESs in understanding and evaluating the AI-generated paraphrasing suggestions.
Passively Addressed Morphing Surface (PARMS) Based on Machine Learning
Jan 30, 2023Reconfigurable morphing surfaces provide new opportunities for advanced human-machine interfaces and bio-inspired robotics. Morphing into arbitrary surfaces on demand requires a device with a sufficiently large number of actuators and an inverse control strategy that can calculate the actuator stimulation necessary to achieve a target surface. The programmability of a morphing surface can be improved by increasing the number of independent actuators, but this increases the complexity of the control system. Thus, developing compact and efficient control interfaces and control algorithms is a crucial knowledge gap for the adoption of morphing surfaces in broad applications. In this work, we describe a passively addressed robotic morphing surface (PARMS) composed of matrix-arranged ionic actuators. To reduce the complexity of the physical control interface, we introduce passive matrix addressing. Matrix addressing allows the control of independent actuators using only 2N control inputs, which is significantly lower than control inputs required for traditional direct addressing. Our control algorithm is based on machine learning using finite element simulations as the training data. This machine learning approach allows both forward and inverse control with high precision in real time. Inverse control demonstrations show that the PARMS can dynamically morph into arbitrary pre-defined surfaces on demand. These innovations in actuator matrix control may enable future implementation of PARMS in wearables, haptics, and augmented reality/virtual reality (AR/VR).
Evaluating Human-Language Model Interaction
Dec 20, 2022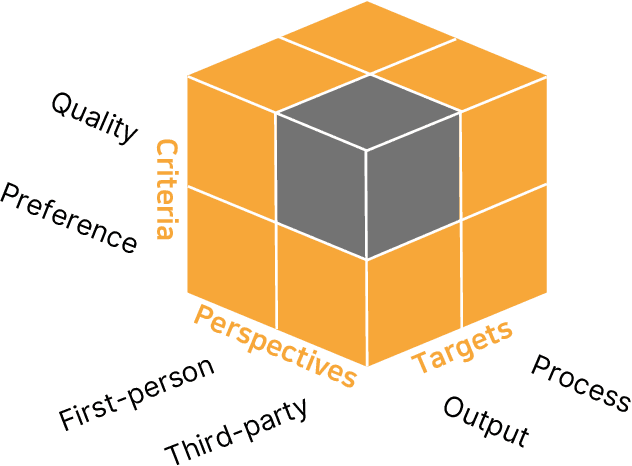
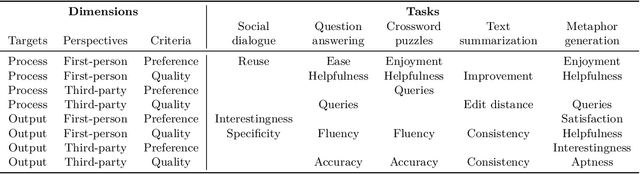
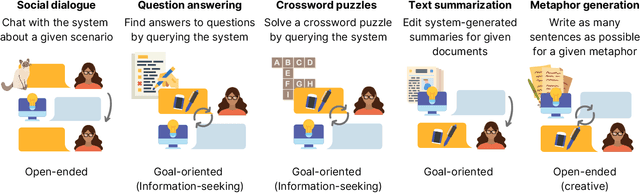

Many real-world applications of language models (LMs), such as code autocomplete and writing assistance, involve human-LM interaction. However, the main LM benchmarks are non-interactive in that a system produces output without human involvement. To evaluate human-LM interaction, we develop a new framework, Human-AI Language-based Interaction Evaluation (HALIE), that expands non-interactive evaluation along three dimensions, capturing (i) the interactive process, not only the final output; (ii) the first-person subjective experience, not just a third-party assessment; and (iii) notions of preference beyond quality. We then design five tasks ranging from goal-oriented to open-ended to capture different forms of interaction. On four state-of-the-art LMs (three variants of OpenAI's GPT-3 and AI21's J1-Jumbo), we find that non-interactive performance does not always result in better human-LM interaction and that first-person and third-party metrics can diverge, suggesting the importance of examining the nuances of human-LM interaction.