 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLength-Controlled AlpacaEval: A Simple Way to Debias Automatic Evaluators
Apr 06, 2024



LLM-based auto-annotators have become a key component of the LLM development process due to their cost-effectiveness and scalability compared to human-based evaluation. However, these auto-annotators can introduce complex biases that are hard to remove. Even simple, known confounders such as preference for longer outputs remain in existing automated evaluation metrics. We propose a simple regression analysis approach for controlling biases in auto-evaluations. As a real case study, we focus on reducing the length bias of AlpacaEval, a fast and affordable benchmark for chat LLMs that uses LLMs to estimate response quality. Despite being highly correlated with human preferences, AlpacaEval is known to favor models that generate longer outputs. We introduce a length-controlled AlpacaEval that aims to answer the counterfactual question: "What would the preference be if the model's and baseline's output had the same length?". To achieve this, we first fit a generalized linear model to predict the biased output of interest (auto-annotator preferences) based on the mediators we want to control for (length difference) and other relevant features. We then obtain length-controlled preferences by predicting preferences while conditioning the GLM with a zero difference in lengths. Length-controlling not only improves the robustness of the metric to manipulations in model verbosity, we also find that it increases the Spearman correlation with LMSYS' Chatbot Arena from 0.94 to 0.98. We release the code and leaderboard at https://tatsu-lab.github.io/alpaca_eval/ .
Benchmarking Multi-Domain Active Learning on Image Classification
Dec 01, 2023



Active learning aims to enhance model performance by strategically labeling informative data points. While extensively studied, its effectiveness on large-scale, real-world datasets remains underexplored. Existing research primarily focuses on single-source data, ignoring the multi-domain nature of real-world data. We introduce a multi-domain active learning benchmark to bridge this gap. Our benchmark demonstrates that traditional single-domain active learning strategies are often less effective than random selection in multi-domain scenarios. We also introduce CLIP-GeoYFCC, a novel large-scale image dataset built around geographical domains, in contrast to existing genre-based domain datasets. Analysis on our benchmark shows that all multi-domain strategies exhibit significant tradeoffs, with no strategy outperforming across all datasets or all metrics, emphasizing the need for future research.
Proving Test Set Contamination in Black Box Language Models
Oct 26, 2023Large language models are trained on vast amounts of internet data, prompting concerns and speculation that they have memorized public benchmarks. Going from speculation to proof of contamination is challenging, as the pretraining data used by proprietary models are often not publicly accessible. We show that it is possible to provide provable guarantees of test set contamination in language models without access to pretraining data or model weights. Our approach leverages the fact that when there is no data contamination, all orderings of an exchangeable benchmark should be equally likely. In contrast, the tendency for language models to memorize example order means that a contaminated language model will find certain canonical orderings to be much more likely than others. Our test flags potential contamination whenever the likelihood of a canonically ordered benchmark dataset is significantly higher than the likelihood after shuffling the examples. We demonstrate that our procedure is sensitive enough to reliably prove test set contamination in challenging situations, including models as small as 1.4 billion parameters, on small test sets of only 1000 examples, and datasets that appear only a few times in the pretraining corpus. Using our test, we audit five popular publicly accessible language models for test set contamination and find little evidence for pervasive contamination.
One Step of Gradient Descent is Provably the Optimal In-Context Learner with One Layer of Linear Self-Attention
Jul 07, 2023Recent works have empirically analyzed in-context learning and shown that transformers trained on synthetic linear regression tasks can learn to implement ridge regression, which is the Bayes-optimal predictor, given sufficient capacity [Aky\"urek et al., 2023], while one-layer transformers with linear self-attention and no MLP layer will learn to implement one step of gradient descent (GD) on a least-squares linear regression objective [von Oswald et al., 2022]. However, the theory behind these observations remains poorly understood. We theoretically study transformers with a single layer of linear self-attention, trained on synthetic noisy linear regression data. First, we mathematically show that when the covariates are drawn from a standard Gaussian distribution, the one-layer transformer which minimizes the pre-training loss will implement a single step of GD on the least-squares linear regression objective. Then, we find that changing the distribution of the covariates and weight vector to a non-isotropic Gaussian distribution has a strong impact on the learned algorithm: the global minimizer of the pre-training loss now implements a single step of $\textit{pre-conditioned}$ GD. However, if only the distribution of the responses is changed, then this does not have a large effect on the learned algorithm: even when the response comes from a more general family of $\textit{nonlinear}$ functions, the global minimizer of the pre-training loss still implements a single step of GD on a least-squares linear regression objective.
Likelihood-Based Diffusion Language Models
May 30, 2023Despite a growing interest in diffusion-based language models, existing work has not shown that these models can attain nontrivial likelihoods on standard language modeling benchmarks. In this work, we take the first steps towards closing the likelihood gap between autoregressive and diffusion-based language models, with the goal of building and releasing a diffusion model which outperforms a small but widely-known autoregressive model. We pursue this goal through algorithmic improvements, scaling laws, and increased compute. On the algorithmic front, we introduce several methodological improvements for the maximum-likelihood training of diffusion language models. We then study scaling laws for our diffusion models and find compute-optimal training regimes which differ substantially from autoregressive models. Using our methods and scaling analysis, we train and release Plaid 1B, a large diffusion language model which outperforms GPT-2 124M in likelihood on benchmark datasets and generates fluent samples in unconditional and zero-shot control settings.
AlpacaFarm: A Simulation Framework for Methods that Learn from Human Feedback
May 22, 2023


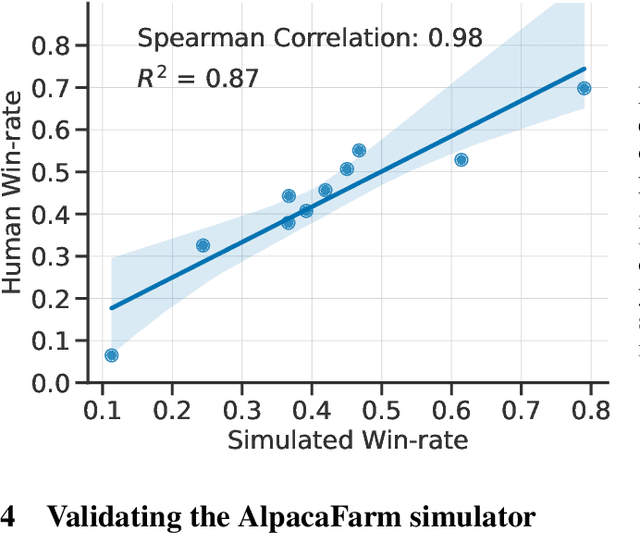
Large language models (LLMs) such as ChatGPT have seen widespread adoption due to their ability to follow user instructions well. Developing these LLMs involves a complex yet poorly understood workflow requiring training with human feedback. Replicating and understanding this instruction-following process faces three major challenges: the high cost of data collection, the lack of trustworthy evaluation, and the absence of reference method implementations. We address these challenges with AlpacaFarm, a simulator that enables research and development for learning from feedback at a low cost. First, we design LLM prompts to simulate human feedback that are 45x cheaper than crowdworkers and display high agreement with humans. Second, we propose an automatic evaluation and validate it against human instructions obtained on real-world interactions. Third, we contribute reference implementations for several methods (PPO, best-of-n, expert iteration, and more) that learn from pairwise feedback. Finally, as an end-to-end validation of AlpacaFarm, we train and evaluate eleven models on 10k pairs of real human feedback and show that rankings of models trained in AlpacaFarm match rankings of models trained on human data. As a demonstration of the research possible in AlpacaFarm, we find that methods that use a reward model can substantially improve over supervised fine-tuning and that our reference PPO implementation leads to a +10% improvement in win-rate against Davinci003. We release all components of AlpacaFarm at https://github.com/tatsu-lab/alpaca_farm.
Benchmarking Large Language Models for News Summarization
Jan 31, 2023Large language models (LLMs) have shown promise for automatic summarization but the reasons behind their successes are poorly understood. By conducting a human evaluation on ten LLMs across different pretraining methods, prompts, and model scales, we make two important observations. First, we find instruction tuning, and not model size, is the key to the LLM's zero-shot summarization capability. Second, existing studies have been limited by low-quality references, leading to underestimates of human performance and lower few-shot and finetuning performance. To better evaluate LLMs, we perform human evaluation over high-quality summaries we collect from freelance writers. Despite major stylistic differences such as the amount of paraphrasing, we find that LMM summaries are judged to be on par with human written summaries.
Coder Reviewer Reranking for Code Generation
Nov 29, 2022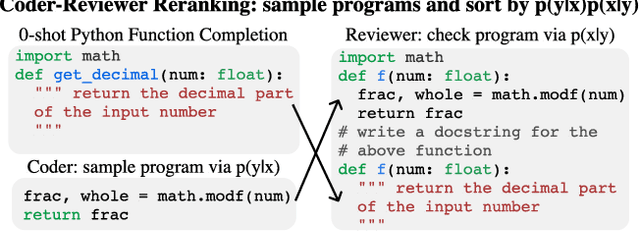
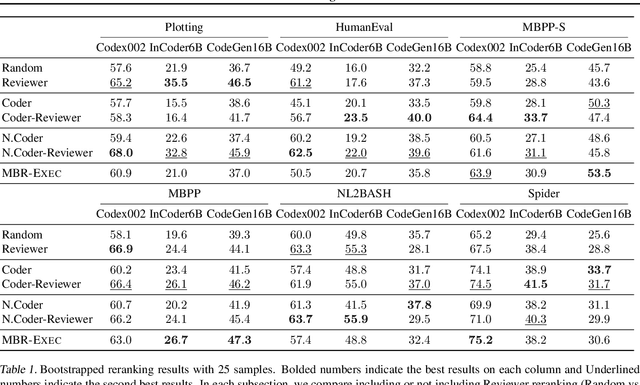
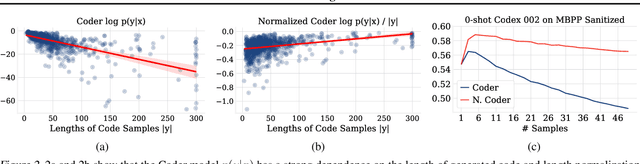

Sampling diverse programs from a code language model and reranking with model likelihood is a popular method for code generation but it is prone to preferring degenerate solutions. Inspired by collaborative programming, we propose Coder-Reviewer reranking. We augment Coder language models from past work, which generate programs given language instructions, with Reviewer models, which evaluate the likelihood of the instruction given the generated programs. We perform an extensive study across six datasets with eight models from three model families. Experimental results show that Coder-Reviewer reranking leads to consistent and significant improvement (up to 17% absolute accuracy gain) over reranking with the Coder model only. When combined with executability filtering, Coder-Reviewer reranking can often outperform the minimum Bayes risk method. Coder-Reviewer reranking is easy to implement by prompting, can generalize to different programming languages, and works well with off-the-shelf hyperparameters.
Data Feedback Loops: Model-driven Amplification of Dataset Biases
Sep 08, 2022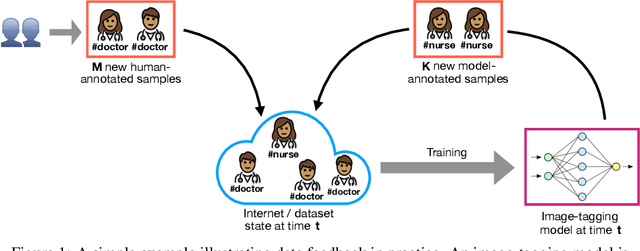

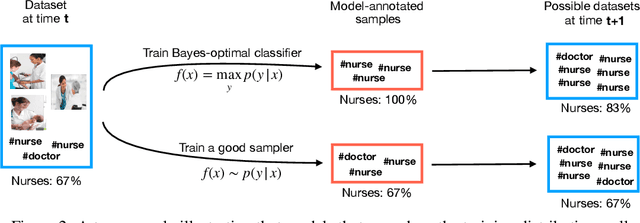

Datasets scraped from the internet have been critical to the successes of large-scale machine learning. Yet, this very success puts the utility of future internet-derived datasets at potential risk, as model outputs begin to replace human annotations as a source of supervision. In this work, we first formalize a system where interactions with one model are recorded as history and scraped as training data in the future. We then analyze its stability over time by tracking changes to a test-time bias statistic (e.g. gender bias of model predictions). We find that the degree of bias amplification is closely linked to whether the model's outputs behave like samples from the training distribution, a behavior which we characterize and define as consistent calibration. Experiments in three conditional prediction scenarios - image classification, visual role-labeling, and language generation - demonstrate that models that exhibit a sampling-like behavior are more calibrated and thus more stable. Based on this insight, we propose an intervention to help calibrate and stabilize unstable feedback systems. Code is available at https://github.com/rtaori/data_feedback.
Diffusion-LM Improves Controllable Text Generation
May 27, 2022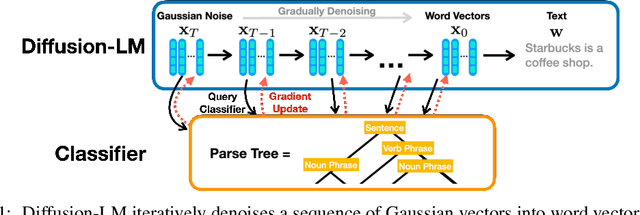

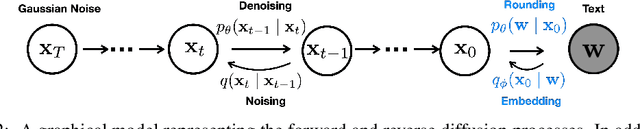
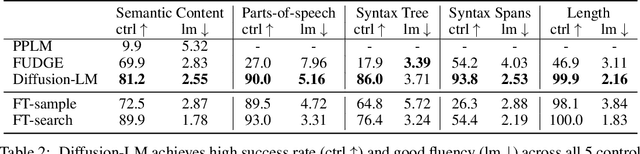
Controlling the behavior of language models (LMs) without re-training is a major open problem in natural language generation. While recent works have demonstrated successes on controlling simple sentence attributes (e.g., sentiment), there has been little progress on complex, fine-grained controls (e.g., syntactic structure). To address this challenge, we develop a new non-autoregressive language model based on continuous diffusions that we call Diffusion-LM. Building upon the recent successes of diffusion models in continuous domains, Diffusion-LM iteratively denoises a sequence of Gaussian vectors into word vectors, yielding a sequence of intermediate latent variables. The continuous, hierarchical nature of these intermediate variables enables a simple gradient-based algorithm to perform complex, controllable generation tasks. We demonstrate successful control of Diffusion-LM for six challenging fine-grained control tasks, significantly outperforming prior work.