 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAuditing Prompt Caching in Language Model APIs
Feb 11, 2025



Prompt caching in large language models (LLMs) results in data-dependent timing variations: cached prompts are processed faster than non-cached prompts. These timing differences introduce the risk of side-channel timing attacks. For example, if the cache is shared across users, an attacker could identify cached prompts from fast API response times to learn information about other users' prompts. Because prompt caching may cause privacy leakage, transparency around the caching policies of API providers is important. To this end, we develop and conduct statistical audits to detect prompt caching in real-world LLM API providers. We detect global cache sharing across users in seven API providers, including OpenAI, resulting in potential privacy leakage about users' prompts. Timing variations due to prompt caching can also result in leakage of information about model architecture. Namely, we find evidence that OpenAI's embedding model is a decoder-only Transformer, which was previously not publicly known.
Eliciting Language Model Behaviors with Investigator Agents
Feb 03, 2025Language models exhibit complex, diverse behaviors when prompted with free-form text, making it difficult to characterize the space of possible outputs. We study the problem of behavior elicitation, where the goal is to search for prompts that induce specific target behaviors (e.g., hallucinations or harmful responses) from a target language model. To navigate the exponentially large space of possible prompts, we train investigator models to map randomly-chosen target behaviors to a diverse distribution of outputs that elicit them, similar to amortized Bayesian inference. We do this through supervised fine-tuning, reinforcement learning via DPO, and a novel Frank-Wolfe training objective to iteratively discover diverse prompting strategies. Our investigator models surface a variety of effective and human-interpretable prompts leading to jailbreaks, hallucinations, and open-ended aberrant behaviors, obtaining a 100% attack success rate on a subset of AdvBench (Harmful Behaviors) and an 85% hallucination rate.
s1: Simple test-time scaling
Jan 31, 2025



Test-time scaling is a promising new approach to language modeling that uses extra test-time compute to improve performance. Recently, OpenAI's o1 model showed this capability but did not publicly share its methodology, leading to many replication efforts. We seek the simplest approach to achieve test-time scaling and strong reasoning performance. First, we curate a small dataset s1K of 1,000 questions paired with reasoning traces relying on three criteria we validate through ablations: difficulty, diversity, and quality. Second, we develop budget forcing to control test-time compute by forcefully terminating the model's thinking process or lengthening it by appending "Wait" multiple times to the model's generation when it tries to end. This can lead the model to double-check its answer, often fixing incorrect reasoning steps. After supervised finetuning the Qwen2.5-32B-Instruct language model on s1K and equipping it with budget forcing, our model s1 exceeds o1-preview on competition math questions by up to 27% (MATH and AIME24). Further, scaling s1 with budget forcing allows extrapolating beyond its performance without test-time intervention: from 50% to 57% on AIME24. Our model, data, and code are open-source at https://github.com/simplescaling/s1.
AutoBencher: Creating Salient, Novel, Difficult Datasets for Language Models
Jul 11, 2024



Evaluation is critical for assessing capabilities, tracking scientific progress, and informing model selection. In this paper, we present three desiderata for a good benchmark for language models: (i) salience (e.g., knowledge about World War II is more salient than a random day in history), (ii) novelty (i.e., the benchmark reveals new trends in model rankings not shown by previous benchmarks), and (iii) difficulty (i.e., the benchmark should be difficult for existing models, leaving headroom for future improvement). We operationalize these three desiderata and cast benchmark creation as a search problem, that of finding benchmarks that that satisfy all three desiderata. To tackle this search problem, we present AutoBencher, which uses a language model to automatically search for datasets that meet the three desiderata. AutoBencher uses privileged information (e.g. relevant documents) to construct reliable datasets, and adaptivity with reranking to optimize for the search objective. We use AutoBencher to create datasets for math, multilingual, and knowledge-intensive question answering. The scalability of AutoBencher allows it to test fine-grained categories and tail knowledge, creating datasets that are on average 27% more novel and 22% more difficult than existing benchmarks. A closer investigation of our constructed datasets shows that we can identify specific gaps in LM knowledge in language models that are not captured by existing benchmarks, such as Gemini Pro performing much worse on question answering about the Permian Extinction and Fordism, while OpenAGI-7B performing surprisingly well on QA about COVID-19.
Few-Shot Recalibration of Language Models
Mar 27, 2024


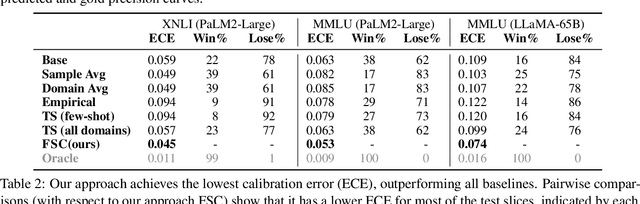
Recent work has uncovered promising ways to extract well-calibrated confidence estimates from language models (LMs), where the model's confidence score reflects how likely it is to be correct. However, while LMs may appear well-calibrated over broad distributions, this often hides significant miscalibration within narrower slices (e.g., systemic over-confidence in math can balance out systemic under-confidence in history, yielding perfect calibration in aggregate). To attain well-calibrated confidence estimates for any slice of a distribution, we propose a new framework for few-shot slice-specific recalibration. Specifically, we train a recalibration model that takes in a few unlabeled examples from any given slice and predicts a curve that remaps confidence scores to be more accurate for that slice. Our trained model can recalibrate for arbitrary new slices, without using any labeled data from that slice. This enables us to identify domain-specific confidence thresholds above which the LM's predictions can be trusted, and below which it should abstain. Experiments show that our few-shot recalibrator consistently outperforms existing calibration methods, for instance improving calibration error for PaLM2-Large on MMLU by 16%, as compared to temperature scaling.
On the Learnability of Watermarks for Language Models
Dec 07, 2023Watermarking of language model outputs enables statistical detection of model-generated text, which has many applications in the responsible deployment of language models. Existing watermarking strategies operate by altering the decoder of an existing language model, and the ability for a language model to directly learn to generate the watermark would have significant implications for the real-world deployment of watermarks. First, learned watermarks could be used to build open models that naturally generate watermarked text, allowing for open models to benefit from watermarking. Second, if watermarking is used to determine the provenance of generated text, an adversary can hurt the reputation of a victim model by spoofing its watermark and generating damaging watermarked text. To investigate the learnability of watermarks, we propose watermark distillation, which trains a student model to behave like a teacher model that uses decoding-based watermarking. We test our approach on three distinct decoding-based watermarking strategies and various hyperparameter settings, finding that models can learn to generate watermarked text with high detectability. We also find limitations to learnability, including the loss of watermarking capabilities under fine-tuning on normal text and high sample complexity when learning low-distortion watermarks.
Benchmarking and Improving Generator-Validator Consistency of Language Models
Oct 03, 2023As of September 2023, ChatGPT correctly answers "what is 7+8" with 15, but when asked "7+8=15, True or False" it responds with "False". This inconsistency between generating and validating an answer is prevalent in language models (LMs) and erodes trust. In this paper, we propose a framework for measuring the consistency between generation and validation (which we call generator-validator consistency, or GV-consistency), finding that even GPT-4, a state-of-the-art LM, is GV-consistent only 76% of the time. To improve the consistency of LMs, we propose to finetune on the filtered generator and validator responses that are GV-consistent, and call this approach consistency fine-tuning. We find that this approach improves GV-consistency of Alpaca-30B from 60% to 93%, and the improvement extrapolates to unseen tasks and domains (e.g., GV-consistency for positive style transfers extrapolates to unseen styles like humor). In addition to improving consistency, consistency fine-tuning improves both generator quality and validator accuracy without using any labeled data. Evaluated across 6 tasks, including math questions, knowledge-intensive QA, and instruction following, our method improves the generator quality by 16% and the validator accuracy by 6.3% across all tasks.
Learning to Compress Prompts with Gist Tokens
Apr 17, 2023
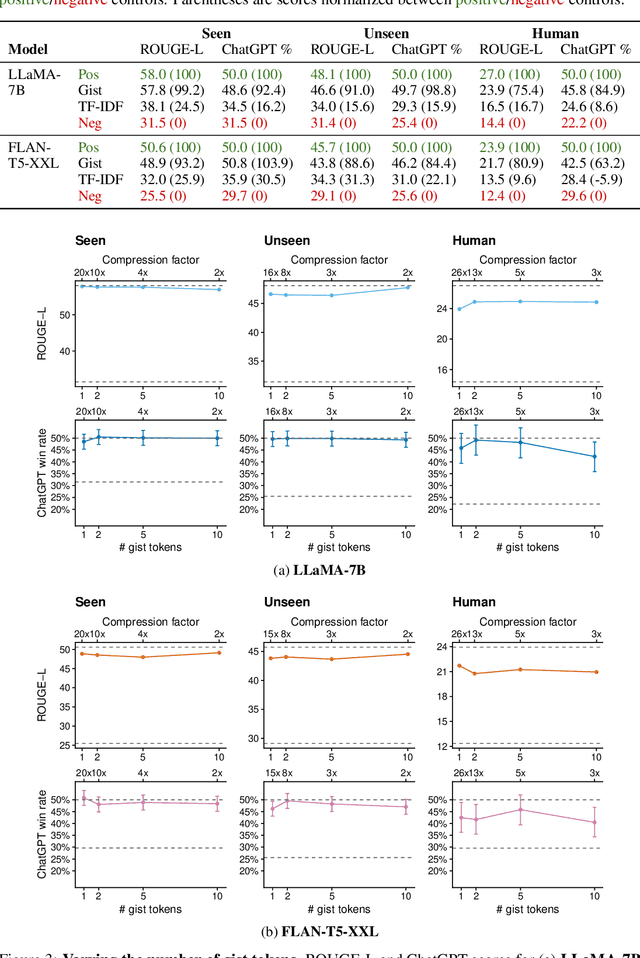
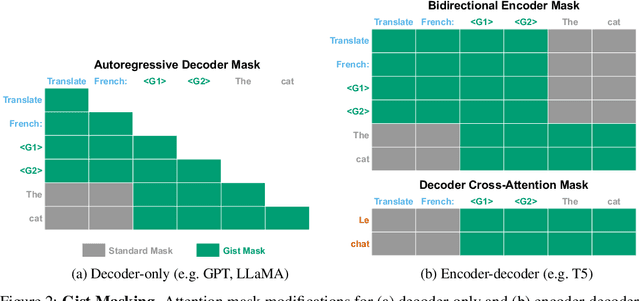

Prompting is now the primary way to utilize the multitask capabilities of language models (LMs), but prompts occupy valuable space in the input context window, and re-encoding the same prompt is computationally inefficient. Finetuning and distillation methods allow for specialization of LMs without prompting, but require retraining the model for each task. To avoid this trade-off entirely, we present gisting, which trains an LM to compress prompts into smaller sets of "gist" tokens which can be reused for compute efficiency. Gist models can be easily trained as part of instruction finetuning via a restricted attention mask that encourages prompt compression. On decoder (LLaMA-7B) and encoder-decoder (FLAN-T5-XXL) LMs, gisting enables up to 26x compression of prompts, resulting in up to 40% FLOPs reductions, 4.2% wall time speedups, storage savings, and minimal loss in output quality.
Demonstrate-Search-Predict: Composing retrieval and language models for knowledge-intensive NLP
Dec 28, 2022


Retrieval-augmented in-context learning has emerged as a powerful approach for addressing knowledge-intensive tasks using frozen language models (LM) and retrieval models (RM). Existing work has combined these in simple "retrieve-then-read" pipelines in which the RM retrieves passages that are inserted into the LM prompt. To begin to fully realize the potential of frozen LMs and RMs, we propose Demonstrate-Search-Predict (DSP), a framework that relies on passing natural language texts in sophisticated pipelines between an LM and an RM. DSP can express high-level programs that bootstrap pipeline-aware demonstrations, search for relevant passages, and generate grounded predictions, systematically breaking down problems into small transformations that the LM and RM can handle more reliably. We have written novel DSP programs for answering questions in open-domain, multi-hop, and conversational settings, establishing in early evaluations new state-of-the-art in-context learning results and delivering 37-200%, 8-40%, and 80-290% relative gains against vanilla LMs, a standard retrieve-then-read pipeline, and a contemporaneous self-ask pipeline, respectively.
Evaluating Human-Language Model Interaction
Dec 20, 2022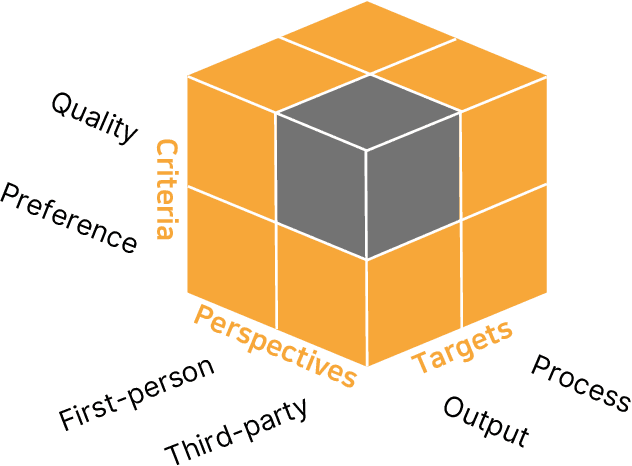
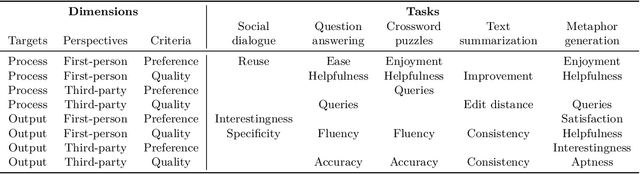
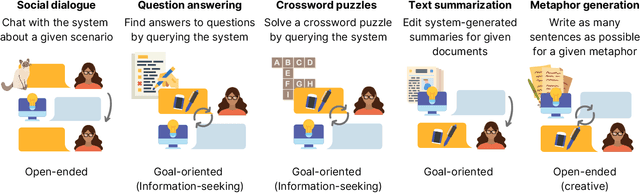

Many real-world applications of language models (LMs), such as code autocomplete and writing assistance, involve human-LM interaction. However, the main LM benchmarks are non-interactive in that a system produces output without human involvement. To evaluate human-LM interaction, we develop a new framework, Human-AI Language-based Interaction Evaluation (HALIE), that expands non-interactive evaluation along three dimensions, capturing (i) the interactive process, not only the final output; (ii) the first-person subjective experience, not just a third-party assessment; and (iii) notions of preference beyond quality. We then design five tasks ranging from goal-oriented to open-ended to capture different forms of interaction. On four state-of-the-art LMs (three variants of OpenAI's GPT-3 and AI21's J1-Jumbo), we find that non-interactive performance does not always result in better human-LM interaction and that first-person and third-party metrics can diverge, suggesting the importance of examining the nuances of human-LM interaction.