 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFew-Shot Recalibration of Language Models
Mar 27, 2024


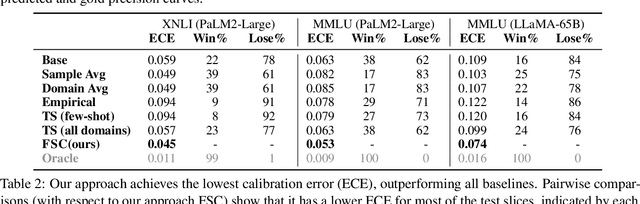
Recent work has uncovered promising ways to extract well-calibrated confidence estimates from language models (LMs), where the model's confidence score reflects how likely it is to be correct. However, while LMs may appear well-calibrated over broad distributions, this often hides significant miscalibration within narrower slices (e.g., systemic over-confidence in math can balance out systemic under-confidence in history, yielding perfect calibration in aggregate). To attain well-calibrated confidence estimates for any slice of a distribution, we propose a new framework for few-shot slice-specific recalibration. Specifically, we train a recalibration model that takes in a few unlabeled examples from any given slice and predicts a curve that remaps confidence scores to be more accurate for that slice. Our trained model can recalibrate for arbitrary new slices, without using any labeled data from that slice. This enables us to identify domain-specific confidence thresholds above which the LM's predictions can be trusted, and below which it should abstain. Experiments show that our few-shot recalibrator consistently outperforms existing calibration methods, for instance improving calibration error for PaLM2-Large on MMLU by 16%, as compared to temperature scaling.
From Pixels to UI Actions: Learning to Follow Instructions via Graphical User Interfaces
May 31, 2023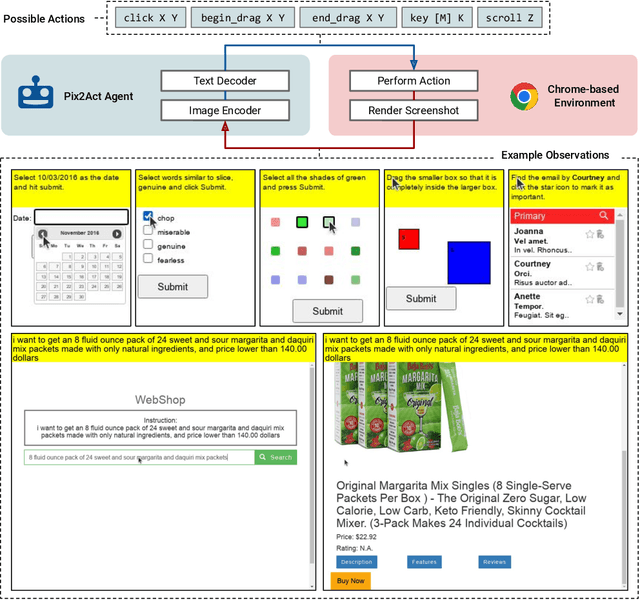
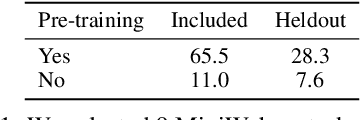
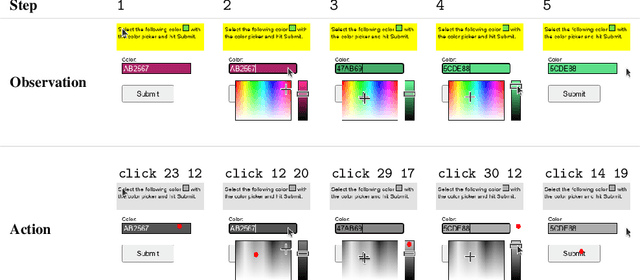
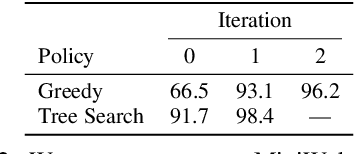
Much of the previous work towards digital agents for graphical user interfaces (GUIs) has relied on text-based representations (derived from HTML or other structured data sources), which are not always readily available. These input representations have been often coupled with custom, task-specific action spaces. This paper focuses on creating agents that interact with the digital world using the same conceptual interface that humans commonly use -- via pixel-based screenshots and a generic action space corresponding to keyboard and mouse actions. Building upon recent progress in pixel-based pretraining, we show, for the first time, that it is possible for such agents to outperform human crowdworkers on the MiniWob++ benchmark of GUI-based instruction following tasks.
Open-domain Visual Entity Recognition: Towards Recognizing Millions of Wikipedia Entities
Feb 24, 2023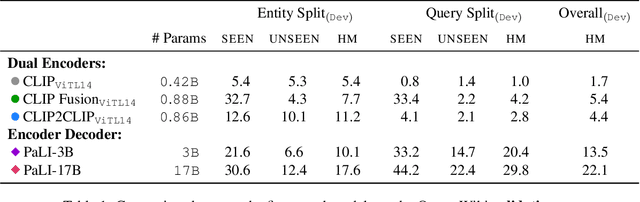
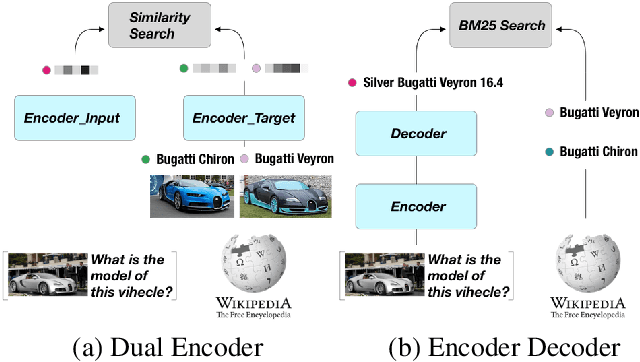
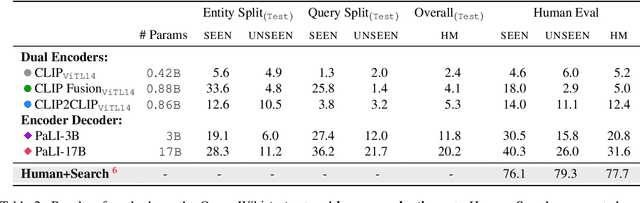

Large-scale multi-modal pre-training models such as CLIP and PaLI exhibit strong generalization on various visual domains and tasks. However, existing image classification benchmarks often evaluate recognition on a specific domain (e.g., outdoor images) or a specific task (e.g., classifying plant species), which falls short of evaluating whether pre-trained foundational models are universal visual recognizers. To address this, we formally present the task of Open-domain Visual Entity recognitioN (OVEN), where a model need to link an image onto a Wikipedia entity with respect to a text query. We construct OVEN-Wiki by re-purposing 14 existing datasets with all labels grounded onto one single label space: Wikipedia entities. OVEN challenges models to select among six million possible Wikipedia entities, making it a general visual recognition benchmark with the largest number of labels. Our study on state-of-the-art pre-trained models reveals large headroom in generalizing to the massive-scale label space. We show that a PaLI-based auto-regressive visual recognition model performs surprisingly well, even on Wikipedia entities that have never been seen during fine-tuning. We also find existing pretrained models yield different strengths: while PaLI-based models obtain higher overall performance, CLIP-based models are better at recognizing tail entities.
Pix2Struct: Screenshot Parsing as Pretraining for Visual Language Understanding
Oct 07, 2022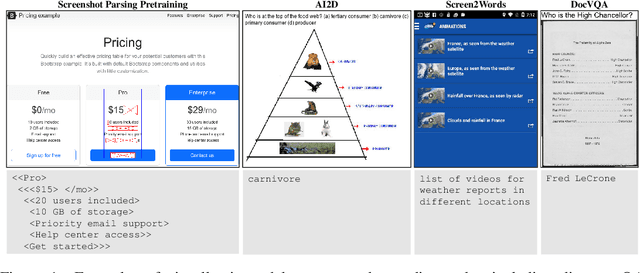


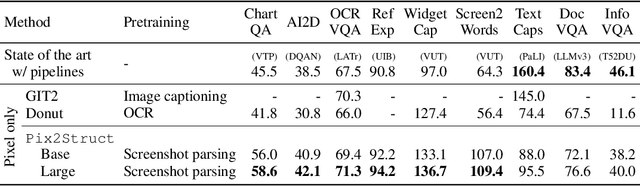
Visually-situated language is ubiquitous -- sources range from textbooks with diagrams to web pages with images and tables, to mobile apps with buttons and forms. Perhaps due to this diversity, previous work has typically relied on domain-specific recipes with limited sharing of the underlying data, model architectures, and objectives. We present Pix2Struct, a pretrained image-to-text model for purely visual language understanding, which can be finetuned on tasks containing visually-situated language. Pix2Struct is pretrained by learning to parse masked screenshots of web pages into simplified HTML. The web, with its richness of visual elements cleanly reflected in the HTML structure, provides a large source of pretraining data well suited to the diversity of downstream tasks. Intuitively, this objective subsumes common pretraining signals such as OCR, language modeling, image captioning. In addition to the novel pretraining strategy, we introduce a variable-resolution input representation and a more flexible integration of language and vision inputs, where language prompts such as questions are rendered directly on top of the input image. For the first time, we show that a single pretrained model can achieve state-of-the-art results in six out of nine tasks across four domains: documents, illustrations, user interfaces, and natural images.
With Little Power Comes Great Responsibility
Oct 13, 2020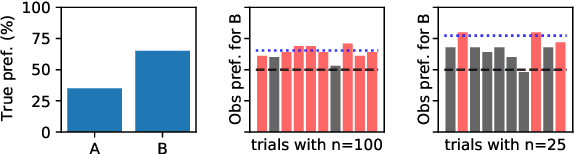

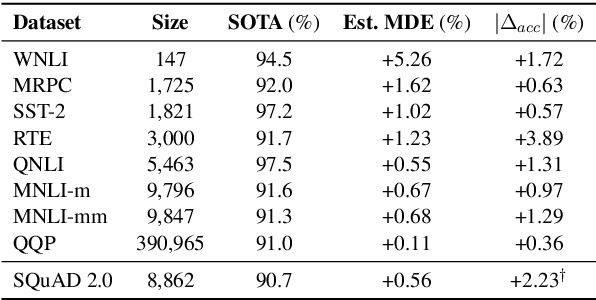
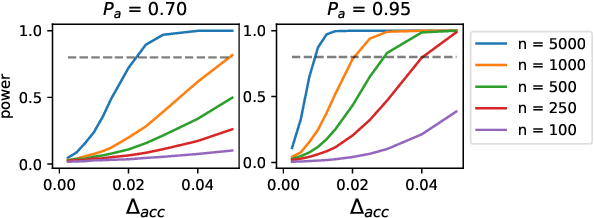
Despite its importance to experimental design, statistical power (the probability that, given a real effect, an experiment will reject the null hypothesis) has largely been ignored by the NLP community. Underpowered experiments make it more difficult to discern the difference between statistical noise and meaningful model improvements, and increase the chances of exaggerated findings. By meta-analyzing a set of existing NLP papers and datasets, we characterize typical power for a variety of settings and conclude that underpowered experiments are common in the NLP literature. In particular, for several tasks in the popular GLUE benchmark, small test sets mean that most attempted comparisons to state of the art models will not be adequately powered. Similarly, based on reasonable assumptions, we find that the most typical experimental design for human rating studies will be underpowered to detect small model differences, of the sort that are frequently studied. For machine translation, we find that typical test sets of 2000 sentences have approximately 75% power to detect differences of 1 BLEU point. To improve the situation going forward, we give an overview of best practices for power analysis in NLP and release a series of notebooks to assist with future power analyses.
Nearest Neighbor Machine Translation
Oct 01, 2020
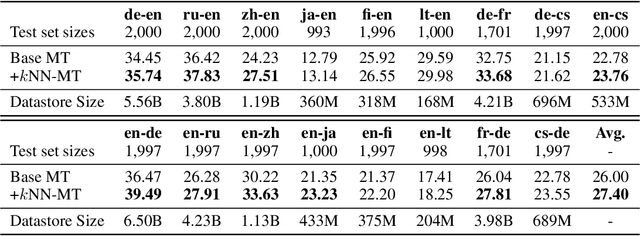
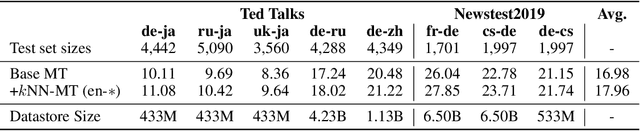

We introduce $k$-nearest-neighbor machine translation ($k$NN-MT), which predicts tokens with a nearest neighbor classifier over a large datastore of cached examples, using representations from a neural translation model for similarity search. This approach requires no additional training and scales to give the decoder direct access to billions of examples at test time, resulting in a highly expressive model that consistently improves performance across many settings. Simply adding nearest neighbor search improves a state-of-the-art German-English translation model by 1.5 BLEU. $k$NN-MT allows a single model to be adapted to diverse domains by using a domain-specific datastore, improving results by an average of 9.2 BLEU over zero-shot transfer, and achieving new state-of-the-art results---without training on these domains. A massively multilingual model can also be specialized for particular language pairs, with improvements of 3 BLEU for translating from English into German and Chinese. Qualitatively, $k$NN-MT is easily interpretable; it combines source and target context to retrieve highly relevant examples.
Generalization through Memorization: Nearest Neighbor Language Models
Nov 01, 2019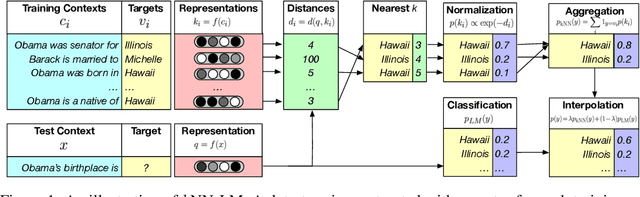
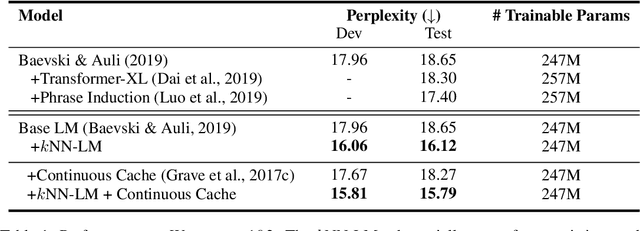

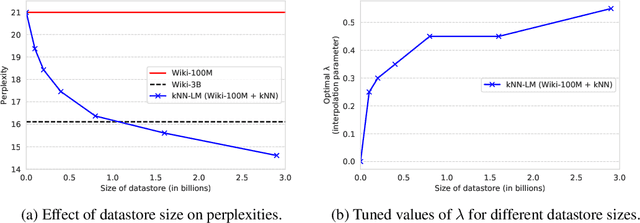
We introduce $k$NN-LMs, which extend a pre-trained neural language model (LM) by linearly interpolating it with a $k$-nearest neighbors ($k$NN) model. The nearest neighbors are computed according to distance in the pre-trained LM embedding space, and can be drawn from any text collection, including the original LM training data. Applying this augmentation to a strong Wikitext-103 LM, with neighbors drawn from the original training set, our $k$NN-LM achieves a new state-of-the-art perplexity of 15.79 - a 2.9 point improvement with no additional training. We also show that this approach has implications for efficiently scaling up to larger training sets and allows for effective domain adaptation, by simply varying the nearest neighbor datastore, again without further training. Qualitatively, the model is particularly helpful in predicting rare patterns, such as factual knowledge. Together, these results strongly suggest that learning similarity between sequences of text is easier than predicting the next word, and that nearest neighbor search is an effective approach for language modeling in the long tail.
BAM! Born-Again Multi-Task Networks for Natural Language Understanding
Jul 10, 2019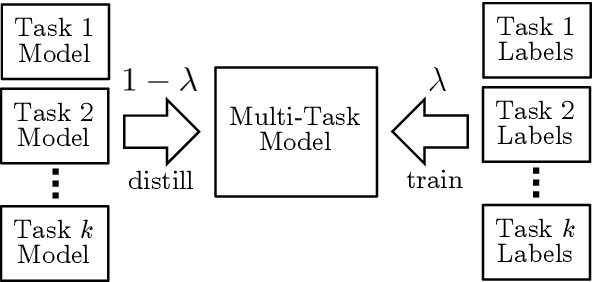
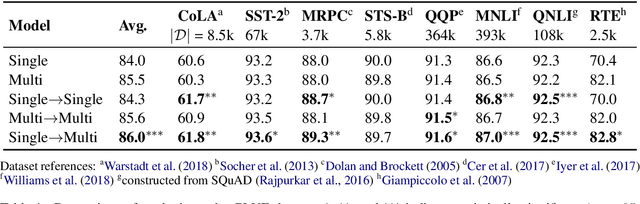

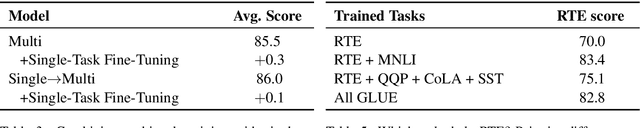
It can be challenging to train multi-task neural networks that outperform or even match their single-task counterparts. To help address this, we propose using knowledge distillation where single-task models teach a multi-task model. We enhance this training with teacher annealing, a novel method that gradually transitions the model from distillation to supervised learning, helping the multi-task model surpass its single-task teachers. We evaluate our approach by multi-task fine-tuning BERT on the GLUE benchmark. Our method consistently improves over standard single-task and multi-task training.
What Does BERT Look At? An Analysis of BERT's Attention
Jun 11, 2019
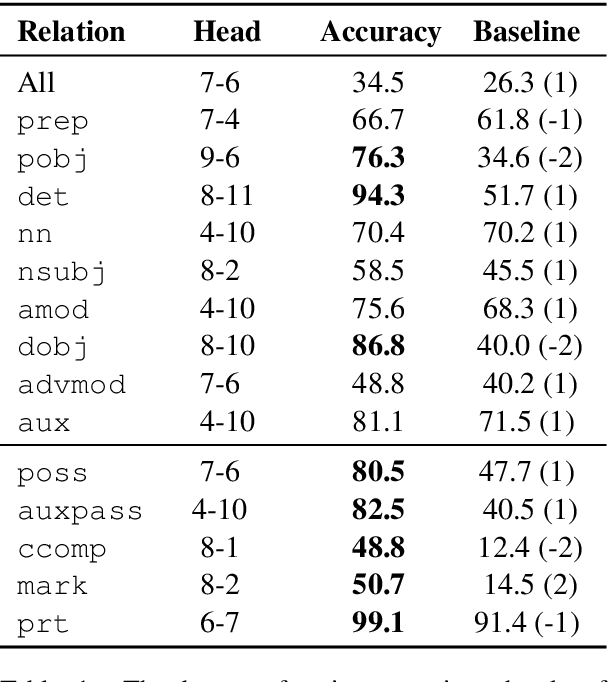
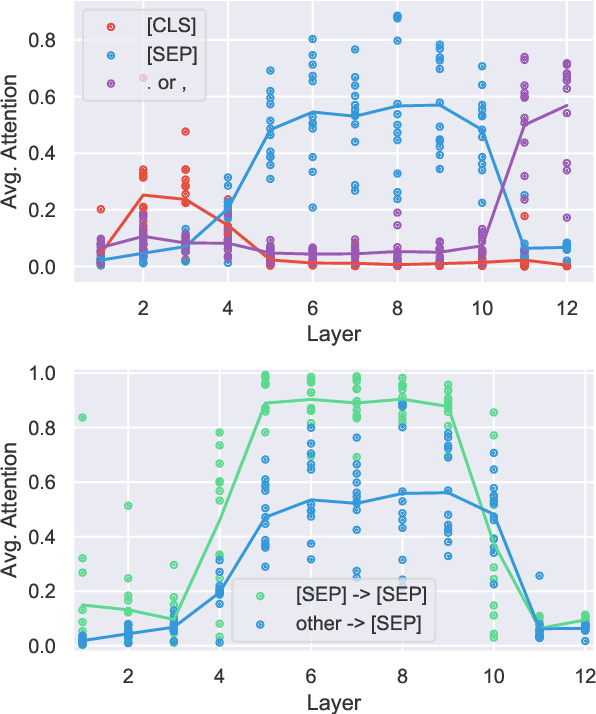
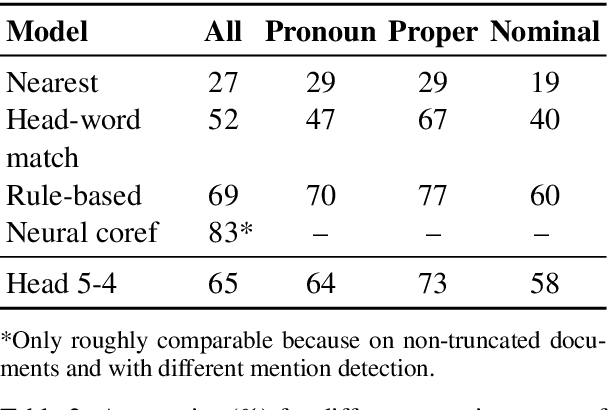
Large pre-trained neural networks such as BERT have had great recent success in NLP, motivating a growing body of research investigating what aspects of language they are able to learn from unlabeled data. Most recent analysis has focused on model outputs (e.g., language model surprisal) or internal vector representations (e.g., probing classifiers). Complementary to these works, we propose methods for analyzing the attention mechanisms of pre-trained models and apply them to BERT. BERT's attention heads exhibit patterns such as attending to delimiter tokens, specific positional offsets, or broadly attending over the whole sentence, with heads in the same layer often exhibiting similar behaviors. We further show that certain attention heads correspond well to linguistic notions of syntax and coreference. For example, we find heads that attend to the direct objects of verbs, determiners of nouns, objects of prepositions, and coreferent mentions with remarkably high accuracy. Lastly, we propose an attention-based probing classifier and use it to further demonstrate that substantial syntactic information is captured in BERT's attention.
Sample Efficient Text Summarization Using a Single Pre-Trained Transformer
May 21, 2019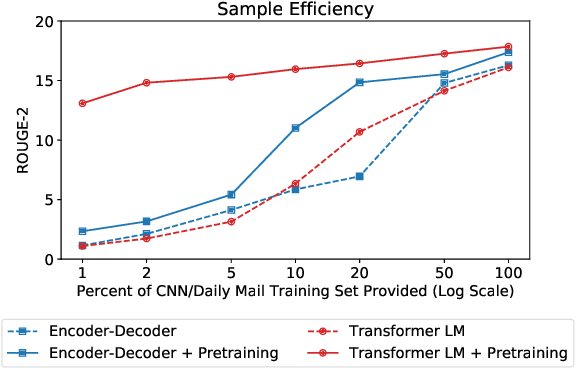
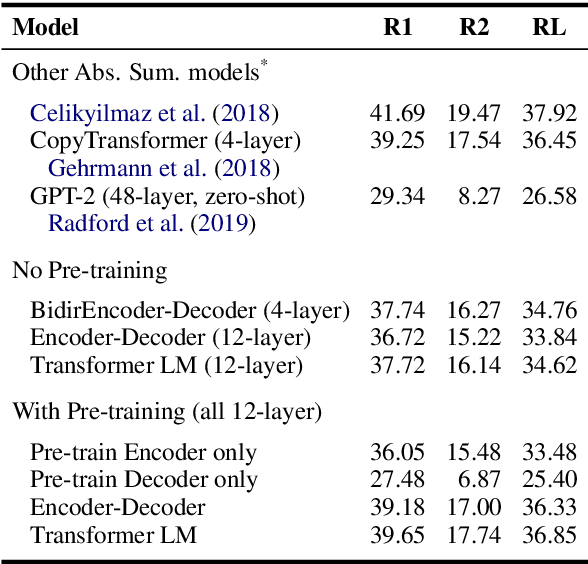
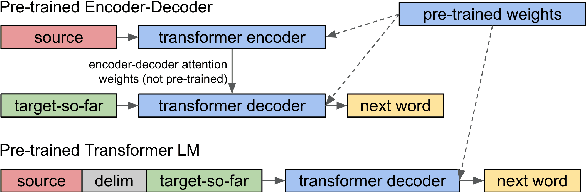

Language model (LM) pre-training has resulted in impressive performance and sample efficiency on a variety of language understanding tasks. However, it remains unclear how to best use pre-trained LMs for generation tasks such as abstractive summarization, particularly to enhance sample efficiency. In these sequence-to-sequence settings, prior work has experimented with loading pre-trained weights into the encoder and/or decoder networks, but used non-pre-trained encoder-decoder attention weights. We instead use a pre-trained decoder-only network, where the same Transformer LM both encodes the source and generates the summary. This ensures that all parameters in the network, including those governing attention over source states, have been pre-trained before the fine-tuning step. Experiments on the CNN/Daily Mail dataset show that our pre-trained Transformer LM substantially improves over pre-trained Transformer encoder-decoder networks in limited-data settings. For instance, it achieves 13.1 ROUGE-2 using only 1% of the training data (~3000 examples), while pre-trained encoder-decoder models score 2.3 ROUGE-2.