 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEffective Reasoning Chains Reduce Intrinsic Dimensionality
Feb 09, 2026Chain-of-thought (CoT) reasoning and its variants have substantially improved the performance of language models on complex reasoning tasks, yet the precise mechanisms by which different strategies facilitate generalization remain poorly understood. While current explanations often point to increased test-time computation or structural guidance, establishing a consistent, quantifiable link between these factors and generalization remains challenging. In this work, we identify intrinsic dimensionality as a quantitative measure for characterizing the effectiveness of reasoning chains. Intrinsic dimensionality quantifies the minimum number of model dimensions needed to reach a given accuracy threshold on a given task. By keeping the model architecture fixed and varying the task formulation through different reasoning strategies, we demonstrate that effective reasoning strategies consistently reduce the intrinsic dimensionality of the task. Validating this on GSM8K with Gemma-3 1B and 4B, we observe a strong inverse correlation between the intrinsic dimensionality of a reasoning strategy and its generalization performance on both in-distribution and out-of-distribution data. Our findings suggest that effective reasoning chains facilitate learning by better compressing the task using fewer parameters, offering a new quantitative metric for analyzing reasoning processes.
ALTA: Compiler-Based Analysis of Transformers
Oct 23, 2024
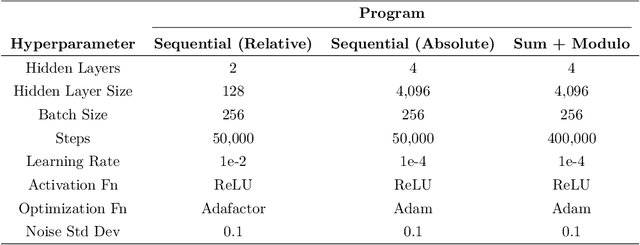

We propose a new programming language called ALTA and a compiler that can map ALTA programs to Transformer weights. ALTA is inspired by RASP, a language proposed by Weiss et al. (2021), and Tracr (Lindner et al., 2023), a compiler from RASP programs to Transformer weights. ALTA complements and extends this prior work, offering the ability to express loops and to compile programs to Universal Transformers, among other advantages. ALTA allows us to constructively show how Transformers can represent length-invariant algorithms for computing parity and addition, as well as a solution to the SCAN benchmark of compositional generalization tasks, without requiring intermediate scratchpad decoding steps. We also propose tools to analyze cases where the expressibility of an algorithm is established, but end-to-end training on a given training set fails to induce behavior consistent with the desired algorithm. To this end, we explore training from ALTA execution traces as a more fine-grained supervision signal. This enables additional experiments and theoretical analyses relating the learnability of various algorithms to data availability and modeling decisions, such as positional encodings. We make the ALTA framework -- language specification, symbolic interpreter, and weight compiler -- available to the community to enable further applications and insights.
MagicLens: Self-Supervised Image Retrieval with Open-Ended Instructions
Mar 28, 2024



Image retrieval, i.e., finding desired images given a reference image, inherently encompasses rich, multi-faceted search intents that are difficult to capture solely using image-based measures. Recent work leverages text instructions to allow users to more freely express their search intents. However, existing work primarily focuses on image pairs that are visually similar and/or can be characterized by a small set of pre-defined relations. The core thesis of this paper is that text instructions can enable retrieving images with richer relations beyond visual similarity. To show this, we introduce MagicLens, a series of self-supervised image retrieval models that support open-ended instructions. MagicLens is built on a key novel insight: image pairs that naturally occur on the same web pages contain a wide range of implicit relations (e.g., inside view of), and we can bring those implicit relations explicit by synthesizing instructions via large multimodal models (LMMs) and large language models (LLMs). Trained on 36.7M (query image, instruction, target image) triplets with rich semantic relations mined from the web, MagicLens achieves comparable or better results on eight benchmarks of various image retrieval tasks than prior state-of-the-art (SOTA) methods. Remarkably, it outperforms previous SOTA but with a 50X smaller model size on multiple benchmarks. Additional human analyses on a 1.4M-image unseen corpus further demonstrate the diversity of search intents supported by MagicLens.
BAGEL: Bootstrapping Agents by Guiding Exploration with Language
Mar 12, 2024



Following natural language instructions by executing actions in digital environments (e.g. web-browsers and REST APIs) is a challenging task for language model (LM) agents. Unfortunately, LM agents often fail to generalize to new environments without human demonstrations. This work presents BAGEL, a method for bootstrapping LM agents without human supervision. BAGEL converts a seed set of randomly explored trajectories or synthetic instructions, into demonstrations, via round-trips between two noisy LM components: an LM labeler which converts a trajectory into a synthetic instruction, and a zero-shot LM agent which maps the synthetic instruction into a refined trajectory. By performing these round-trips iteratively, BAGEL quickly converts the initial distribution of trajectories towards those that are well-described by natural language. We use BAGEL demonstrations to adapt a zero shot LM agent at test time via in-context learning over retrieved demonstrations, and find improvements of over 2-13% absolute on ToolQA and MiniWob++, with up to 13x reduction in execution failures.
From Pixels to UI Actions: Learning to Follow Instructions via Graphical User Interfaces
May 31, 2023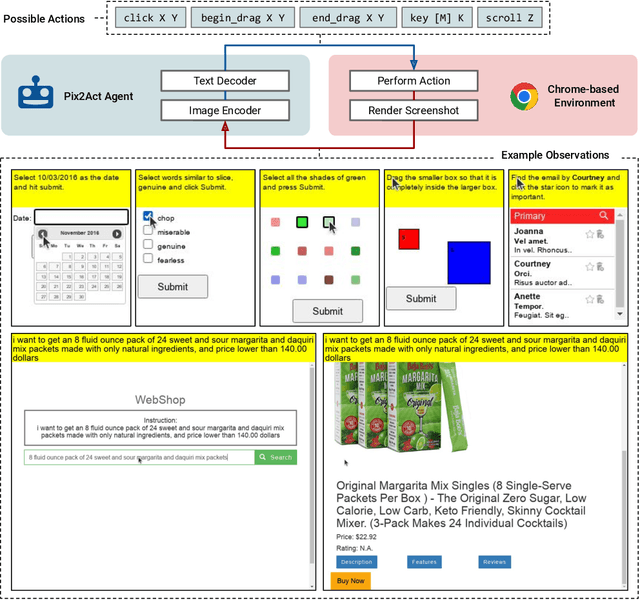
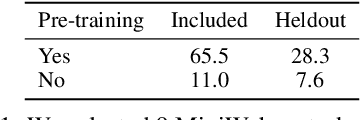
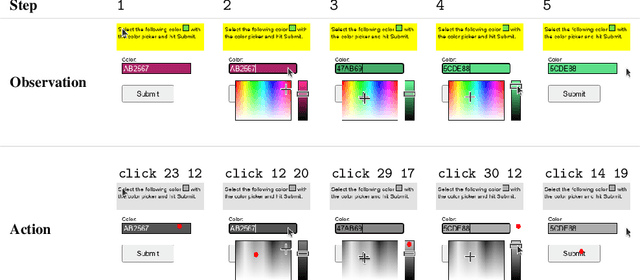
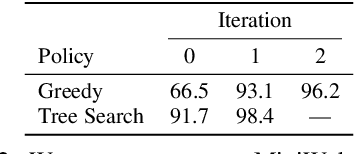
Much of the previous work towards digital agents for graphical user interfaces (GUIs) has relied on text-based representations (derived from HTML or other structured data sources), which are not always readily available. These input representations have been often coupled with custom, task-specific action spaces. This paper focuses on creating agents that interact with the digital world using the same conceptual interface that humans commonly use -- via pixel-based screenshots and a generic action space corresponding to keyboard and mouse actions. Building upon recent progress in pixel-based pretraining, we show, for the first time, that it is possible for such agents to outperform human crowdworkers on the MiniWob++ benchmark of GUI-based instruction following tasks.
PaLI-X: On Scaling up a Multilingual Vision and Language Model
May 29, 2023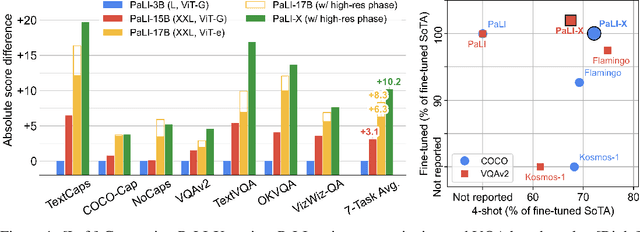
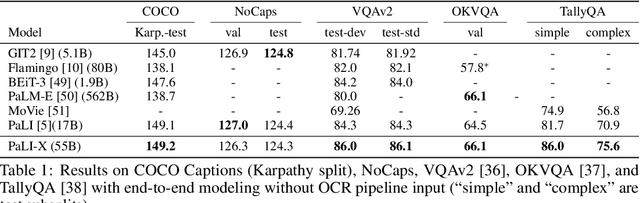
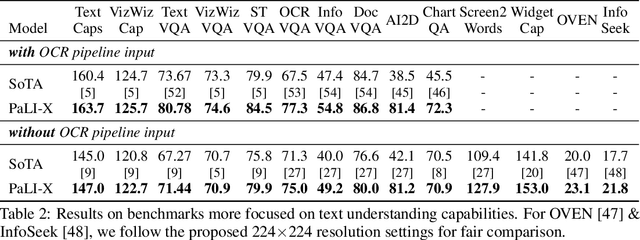

We present the training recipe and results of scaling up PaLI-X, a multilingual vision and language model, both in terms of size of the components and the breadth of its training task mixture. Our model achieves new levels of performance on a wide-range of varied and complex tasks, including multiple image-based captioning and question-answering tasks, image-based document understanding and few-shot (in-context) learning, as well as object detection, video question answering, and video captioning. PaLI-X advances the state-of-the-art on most vision-and-language benchmarks considered (25+ of them). Finally, we observe emerging capabilities, such as complex counting and multilingual object detection, tasks that are not explicitly in the training mix.
Anchor Prediction: Automatic Refinement of Internet Links
May 24, 2023Internet links enable users to deepen their understanding of a topic by providing convenient access to related information. However, the majority of links are unanchored -- they link to a target webpage as a whole, and readers may expend considerable effort localizing the specific parts of the target webpage that enrich their understanding of the link's source context. To help readers effectively find information in linked webpages, we introduce the task of anchor prediction, where the goal is to identify the specific part of the linked target webpage that is most related to the source linking context. We release the AuthorAnchors dataset, a collection of 34K naturally-occurring anchored links, which reflect relevance judgments by the authors of the source article. To model reader relevance judgments, we annotate and release ReaderAnchors, an evaluation set of anchors that readers find useful. Our analysis shows that effective anchor prediction often requires jointly reasoning over lengthy source and target webpages to determine their implicit relations and identify parts of the target webpage that are related but not redundant. We benchmark a performant T5-based ranking approach to establish baseline performance on the task, finding ample room for improvement.
QUEST: A Retrieval Dataset of Entity-Seeking Queries with Implicit Set Operations
May 19, 2023



Formulating selective information needs results in queries that implicitly specify set operations, such as intersection, union, and difference. For instance, one might search for "shorebirds that are not sandpipers" or "science-fiction films shot in England". To study the ability of retrieval systems to meet such information needs, we construct QUEST, a dataset of 3357 natural language queries with implicit set operations, that map to a set of entities corresponding to Wikipedia documents. The dataset challenges models to match multiple constraints mentioned in queries with corresponding evidence in documents and correctly perform various set operations. The dataset is constructed semi-automatically using Wikipedia category names. Queries are automatically composed from individual categories, then paraphrased and further validated for naturalness and fluency by crowdworkers. Crowdworkers also assess the relevance of entities based on their documents and highlight attribution of query constraints to spans of document text. We analyze several modern retrieval systems, finding that they often struggle on such queries. Queries involving negation and conjunction are particularly challenging and systems are further challenged with combinations of these operations.
Conditional Adapters: Parameter-efficient Transfer Learning with Fast Inference
Apr 11, 2023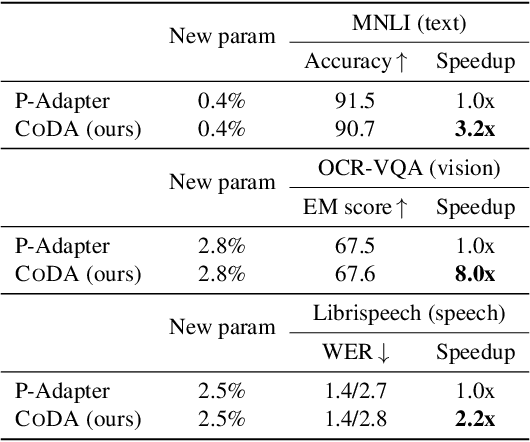

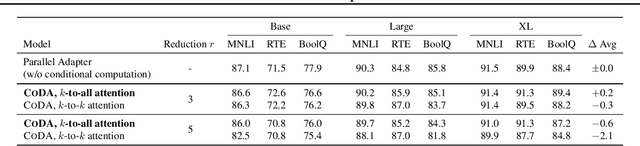
We propose Conditional Adapter (CoDA), a parameter-efficient transfer learning method that also improves inference efficiency. CoDA generalizes beyond standard adapter approaches to enable a new way of balancing speed and accuracy using conditional computation. Starting with an existing dense pretrained model, CoDA adds sparse activation together with a small number of new parameters and a light-weight training phase. Our experiments demonstrate that the CoDA approach provides an unexpectedly efficient way to transfer knowledge. Across a variety of language, vision, and speech tasks, CoDA achieves a 2x to 8x inference speed-up compared to the state-of-the-art Adapter approach with moderate to no accuracy loss and the same parameter efficiency.
Open-domain Visual Entity Recognition: Towards Recognizing Millions of Wikipedia Entities
Feb 24, 2023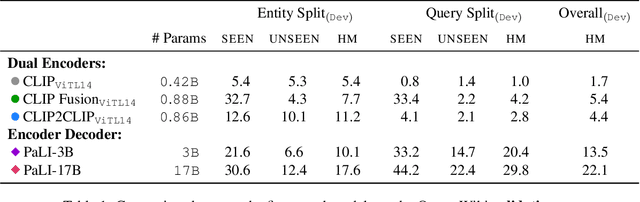
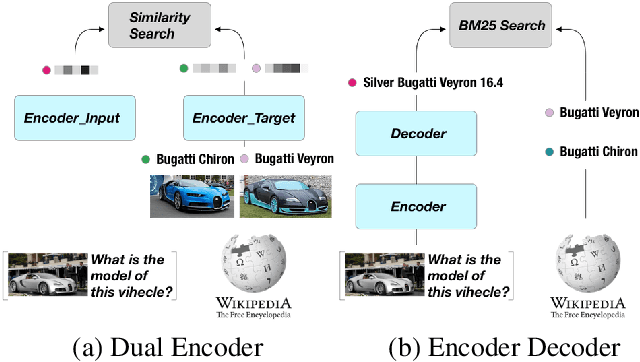
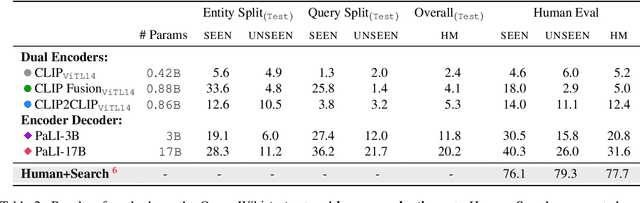

Large-scale multi-modal pre-training models such as CLIP and PaLI exhibit strong generalization on various visual domains and tasks. However, existing image classification benchmarks often evaluate recognition on a specific domain (e.g., outdoor images) or a specific task (e.g., classifying plant species), which falls short of evaluating whether pre-trained foundational models are universal visual recognizers. To address this, we formally present the task of Open-domain Visual Entity recognitioN (OVEN), where a model need to link an image onto a Wikipedia entity with respect to a text query. We construct OVEN-Wiki by re-purposing 14 existing datasets with all labels grounded onto one single label space: Wikipedia entities. OVEN challenges models to select among six million possible Wikipedia entities, making it a general visual recognition benchmark with the largest number of labels. Our study on state-of-the-art pre-trained models reveals large headroom in generalizing to the massive-scale label space. We show that a PaLI-based auto-regressive visual recognition model performs surprisingly well, even on Wikipedia entities that have never been seen during fine-tuning. We also find existing pretrained models yield different strengths: while PaLI-based models obtain higher overall performance, CLIP-based models are better at recognizing tail entities.