 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTANQ: An open domain dataset of table answered questions
May 13, 2024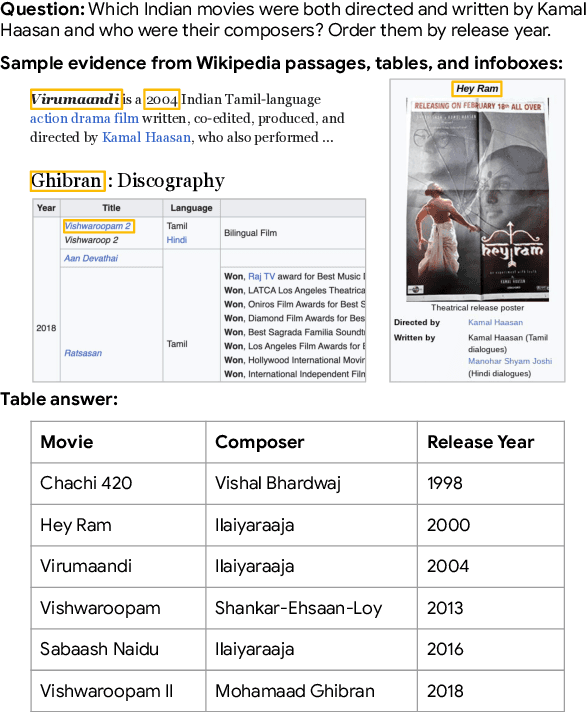
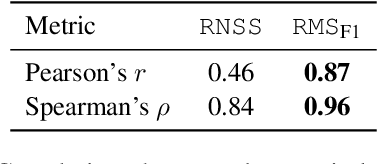
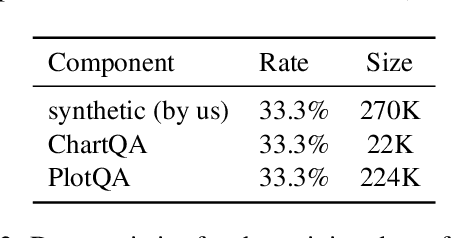
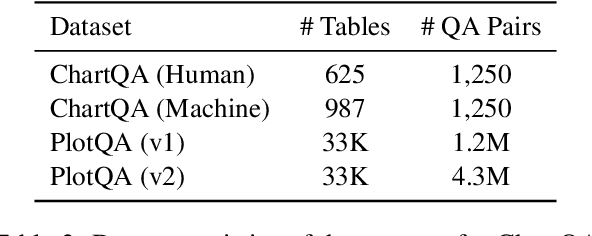
Language models, potentially augmented with tool usage such as retrieval are becoming the go-to means of answering questions. Understanding and answering questions in real-world settings often requires retrieving information from different sources, processing and aggregating data to extract insights, and presenting complex findings in form of structured artifacts such as novel tables, charts, or infographics. In this paper, we introduce TANQ, the first open domain question answering dataset where the answers require building tables from information across multiple sources. We release the full source attribution for every cell in the resulting table and benchmark state-of-the-art language models in open, oracle, and closed book setups. Our best-performing baseline, GPT4 reaches an overall F1 score of 29.1, lagging behind human performance by 19.7 points. We analyse baselines' performance across different dataset attributes such as different skills required for this task, including multi-hop reasoning, math operations, and unit conversions. We further discuss common failures in model-generated answers, suggesting that TANQ is a complex task with many challenges ahead.
DePlot: One-shot visual language reasoning by plot-to-table translation
Dec 20, 2022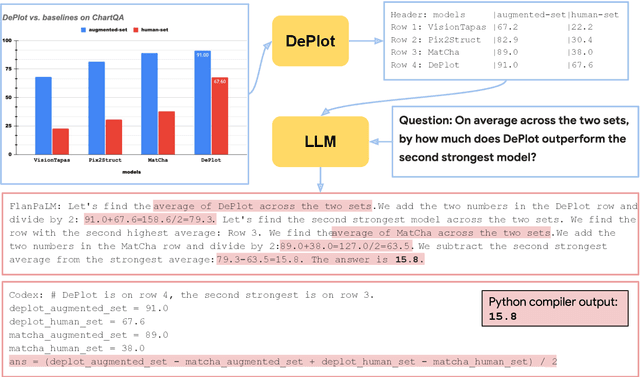
Visual language such as charts and plots is ubiquitous in the human world. Comprehending plots and charts requires strong reasoning skills. Prior state-of-the-art (SOTA) models require at least tens of thousands of training examples and their reasoning capabilities are still much limited, especially on complex human-written queries. This paper presents the first one-shot solution to visual language reasoning. We decompose the challenge of visual language reasoning into two steps: (1) plot-to-text translation, and (2) reasoning over the translated text. The key in this method is a modality conversion module, named as DePlot, which translates the image of a plot or chart to a linearized table. The output of DePlot can then be directly used to prompt a pretrained large language model (LLM), exploiting the few-shot reasoning capabilities of LLMs. To obtain DePlot, we standardize the plot-to-table task by establishing unified task formats and metrics, and train DePlot end-to-end on this task. DePlot can then be used off-the-shelf together with LLMs in a plug-and-play fashion. Compared with a SOTA model finetuned on more than >28k data points, DePlot+LLM with just one-shot prompting achieves a 24.0% improvement over finetuned SOTA on human-written queries from the task of chart QA.
MatCha: Enhancing Visual Language Pretraining with Math Reasoning and Chart Derendering
Dec 19, 2022



Visual language data such as plots, charts, and infographics are ubiquitous in the human world. However, state-of-the-art vision-language models do not perform well on these data. We propose MatCha (Math reasoning and Chart derendering pretraining) to enhance visual language models' capabilities in jointly modeling charts/plots and language data. Specifically, we propose several pretraining tasks that cover plot deconstruction and numerical reasoning which are the key capabilities in visual language modeling. We perform the MatCha pretraining starting from Pix2Struct, a recently proposed image-to-text visual language model. On standard benchmarks such as PlotQA and ChartQA, the MatCha model outperforms state-of-the-art methods by as much as nearly 20%. We also examine how well MatCha pretraining transfers to domains such as screenshots, textbook diagrams, and document figures and observe overall improvement, verifying the usefulness of MatCha pretraining on broader visual language tasks.
Table-To-Text generation and pre-training with TabT5
Oct 17, 2022
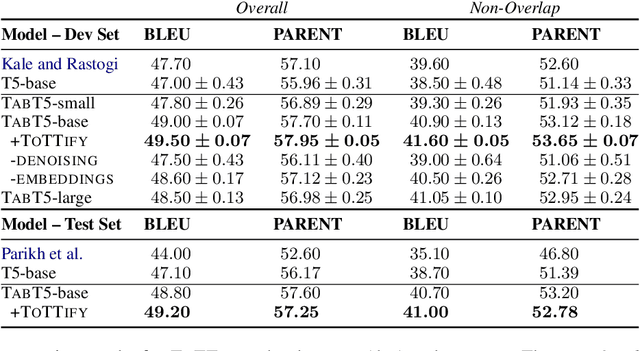
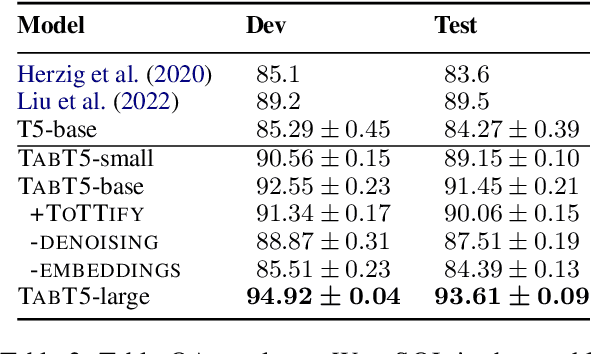
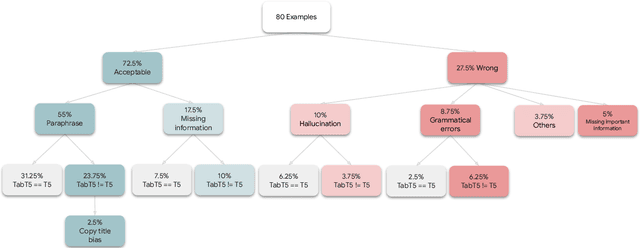
Encoder-only transformer models have been successfully applied to different table understanding tasks, as in TAPAS (Herzig et al., 2020). A major limitation of these architectures is that they are constrained to classification-like tasks such as cell selection or entailment detection. We present TABT5, an encoder-decoder model that generates natural language text based on tables and textual inputs. TABT5 overcomes the encoder-only limitation by incorporating a decoder component and leverages the input structure with table specific embeddings and pre-training. TABT5 achieves new state-of-the-art results on several domains, including spreadsheet formula prediction with a 15% increase in sequence accuracy, QA with a 2.5% increase in sequence accuracy and data-to-text generation with a 2.5% increase in BLEU.
LAD: Language Models as Data for Zero-Shot Dialog
Jul 28, 2022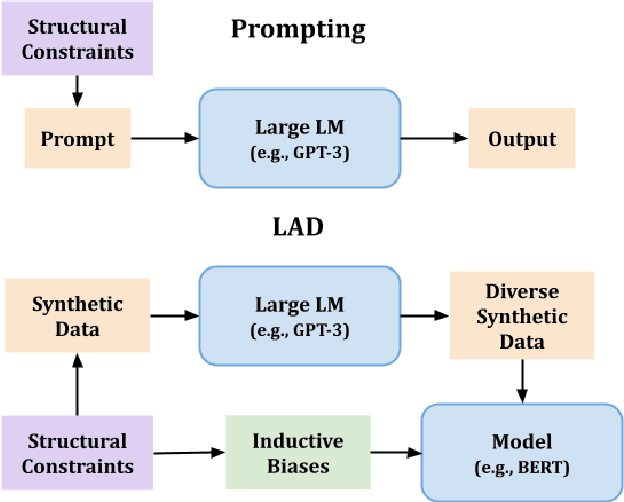
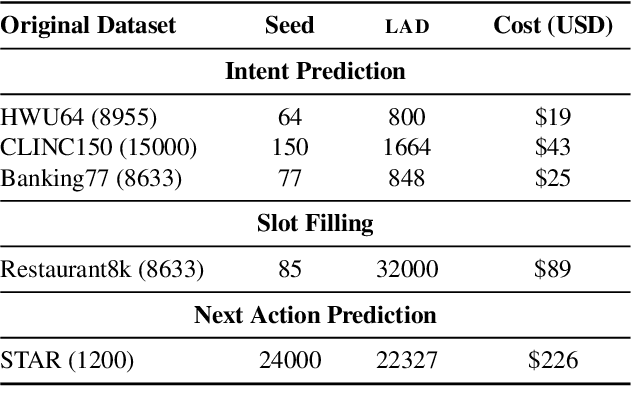
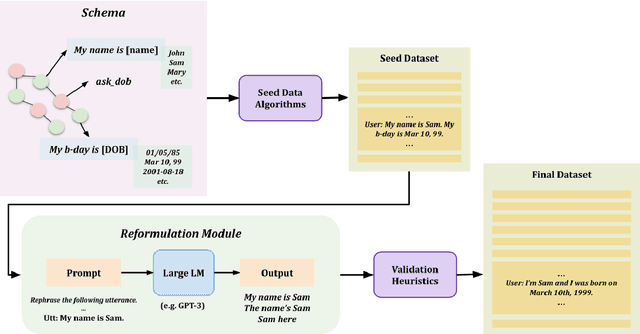

To facilitate zero-shot generalization in taskoriented dialog, this paper proposes Language Models as Data (LAD). LAD is a paradigm for creating diverse and accurate synthetic data which conveys the necessary structural constraints and can be used to train a downstream neural dialog model. LAD leverages GPT-3 to induce linguistic diversity. LAD achieves significant performance gains in zero-shot settings on intent prediction (+15%), slot filling (+31.4 F-1) and next action prediction (+11 F1). Furthermore, an interactive human evaluation shows that training with LAD is competitive with training on human dialogs. LAD is open-sourced, with the code and data available at https://github.com/Shikib/lad.
What Did You Say? Task-Oriented Dialog Datasets Are Not Conversational!?
Mar 07, 2022
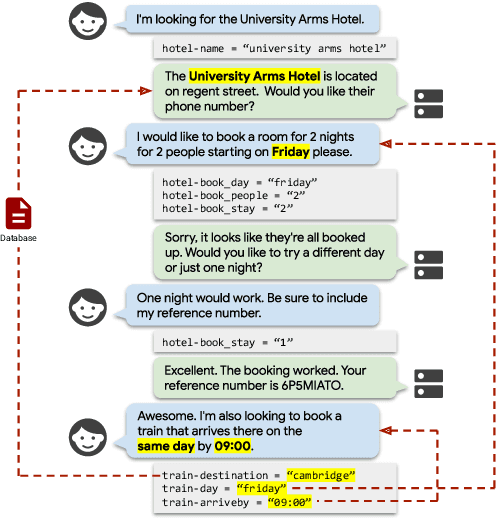
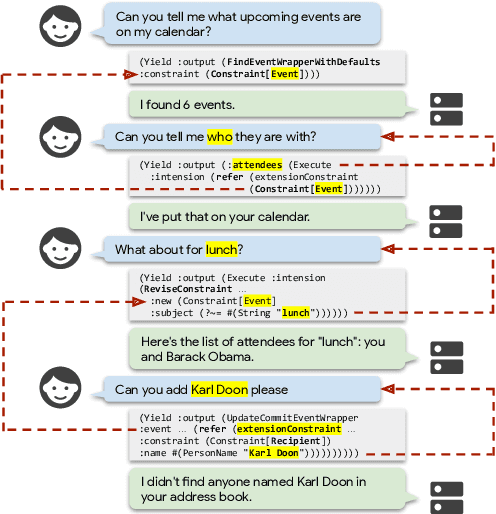

High-quality datasets for task-oriented dialog are crucial for the development of virtual assistants. Yet three of the most relevant large scale dialog datasets suffer from one common flaw: the dialog state update can be tracked, to a great extent, by a model that only considers the current user utterance, ignoring the dialog history. In this work, we outline a taxonomy of conversational and contextual effects, which we use to examine MultiWOZ, SGD and SMCalFlow, among the most recent and widely used task-oriented dialog datasets. We analyze the datasets in a model-independent fashion and corroborate these findings experimentally using a strong text-to-text baseline (T5). We find that less than 4% of MultiWOZ's turns and 10% of SGD's turns are conversational, while SMCalFlow is not conversational at all in its current release: its dialog state tracking task can be reduced to single exchange semantic parsing. We conclude by outlining desiderata for truly conversational dialog datasets.
Translate & Fill: Improving Zero-Shot Multilingual Semantic Parsing with Synthetic Data
Sep 09, 2021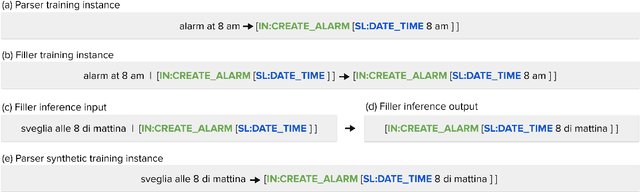

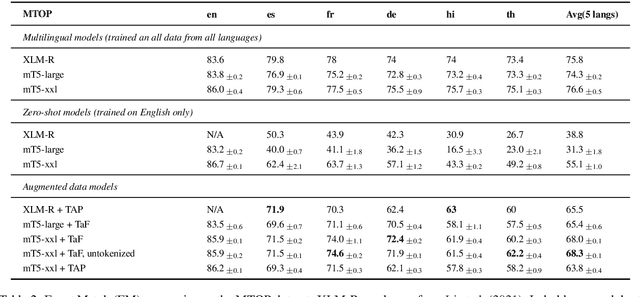
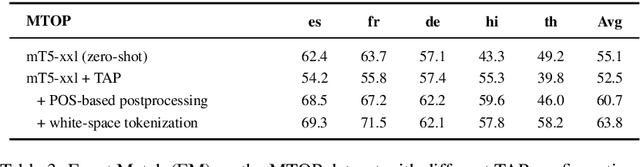
While multilingual pretrained language models (LMs) fine-tuned on a single language have shown substantial cross-lingual task transfer capabilities, there is still a wide performance gap in semantic parsing tasks when target language supervision is available. In this paper, we propose a novel Translate-and-Fill (TaF) method to produce silver training data for a multilingual semantic parser. This method simplifies the popular Translate-Align-Project (TAP) pipeline and consists of a sequence-to-sequence filler model that constructs a full parse conditioned on an utterance and a view of the same parse. Our filler is trained on English data only but can accurately complete instances in other languages (i.e., translations of the English training utterances), in a zero-shot fashion. Experimental results on three multilingual semantic parsing datasets show that data augmentation with TaF reaches accuracies competitive with similar systems which rely on traditional alignment techniques.
Answering Conversational Questions on Structured Data without Logical Forms
Aug 30, 2019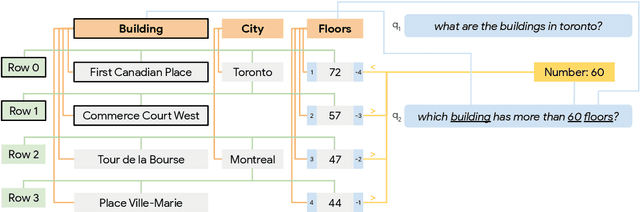
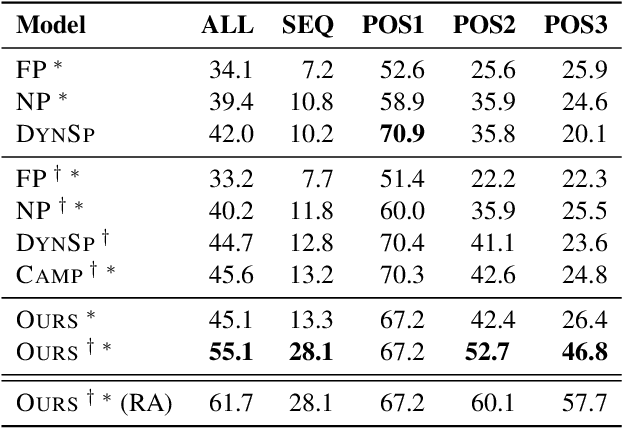

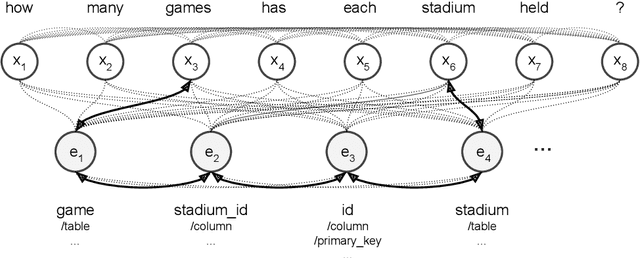
We present a novel approach to answering sequential questions based on structured objects such as knowledge bases or tables without using a logical form as an intermediate representation. We encode tables as graphs using a graph neural network model based on the Transformer architecture. The answers are then selected from the encoded graph using a pointer network. This model is appropriate for processing conversations around structured data, where the attention mechanism that selects the answers to a question can also be used to resolve conversational references. We demonstrate the validity of this approach with competitive results on the Sequential Question Answering (SQA) task (Iyyer et al., 2017).
Generating Logical Forms from Graph Representations of Text and Entities
May 21, 2019
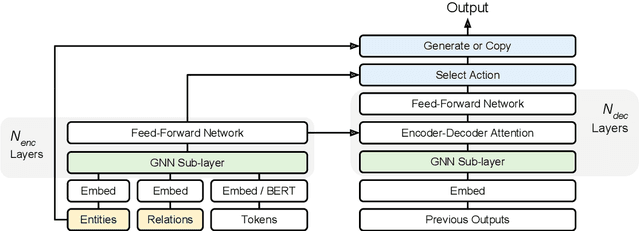

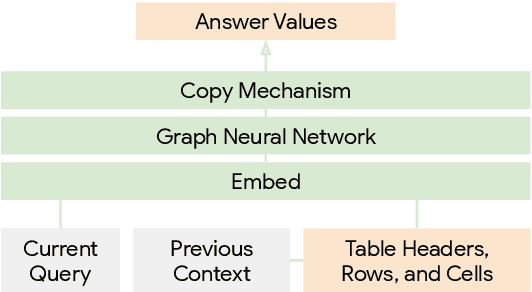
Structured information about entities is critical for many semantic parsing tasks. We present an approach that uses a Graph Neural Network (GNN) architecture to incorporate information about relevant entities and their relations during parsing. Combined with a decoder copy mechanism, this approach provides a conceptually simple mechanism to generate logical forms with entities. We demonstrate that this approach is competitive with state-of-the-art across several tasks without pre-training, and outperforms existing approaches when combined with BERT pre-training.
Exponential Families for Conditional Random Fields
Jul 11, 2012
In this paper we de ne conditional random elds in reproducing kernel Hilbert spaces and show connections to Gaussian Process classi cation. More speci cally, we prove decomposition results for undirected graphical models and we give constructions for kernels. Finally we present e cient means of solving the optimization problem using reduced rank decompositions and we show how stationarity can be exploited e ciently in the optimization process.