 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEffective Reasoning Chains Reduce Intrinsic Dimensionality
Feb 09, 2026Chain-of-thought (CoT) reasoning and its variants have substantially improved the performance of language models on complex reasoning tasks, yet the precise mechanisms by which different strategies facilitate generalization remain poorly understood. While current explanations often point to increased test-time computation or structural guidance, establishing a consistent, quantifiable link between these factors and generalization remains challenging. In this work, we identify intrinsic dimensionality as a quantitative measure for characterizing the effectiveness of reasoning chains. Intrinsic dimensionality quantifies the minimum number of model dimensions needed to reach a given accuracy threshold on a given task. By keeping the model architecture fixed and varying the task formulation through different reasoning strategies, we demonstrate that effective reasoning strategies consistently reduce the intrinsic dimensionality of the task. Validating this on GSM8K with Gemma-3 1B and 4B, we observe a strong inverse correlation between the intrinsic dimensionality of a reasoning strategy and its generalization performance on both in-distribution and out-of-distribution data. Our findings suggest that effective reasoning chains facilitate learning by better compressing the task using fewer parameters, offering a new quantitative metric for analyzing reasoning processes.
BAGEL: Bootstrapping Agents by Guiding Exploration with Language
Mar 12, 2024



Following natural language instructions by executing actions in digital environments (e.g. web-browsers and REST APIs) is a challenging task for language model (LM) agents. Unfortunately, LM agents often fail to generalize to new environments without human demonstrations. This work presents BAGEL, a method for bootstrapping LM agents without human supervision. BAGEL converts a seed set of randomly explored trajectories or synthetic instructions, into demonstrations, via round-trips between two noisy LM components: an LM labeler which converts a trajectory into a synthetic instruction, and a zero-shot LM agent which maps the synthetic instruction into a refined trajectory. By performing these round-trips iteratively, BAGEL quickly converts the initial distribution of trajectories towards those that are well-described by natural language. We use BAGEL demonstrations to adapt a zero shot LM agent at test time via in-context learning over retrieved demonstrations, and find improvements of over 2-13% absolute on ToolQA and MiniWob++, with up to 13x reduction in execution failures.
Efficient End-to-End Visual Document Understanding with Rationale Distillation
Nov 16, 2023



Understanding visually situated language requires recognizing text and visual elements, and interpreting complex layouts. State-of-the-art methods commonly use specialized pre-processing tools, such as optical character recognition (OCR) systems, that map document image inputs to extracted information in the space of textual tokens, and sometimes also employ large language models (LLMs) to reason in text token space. However, the gains from external tools and LLMs come at the cost of increased computational and engineering complexity. In this paper, we ask whether small pretrained image-to-text models can learn selective text or layout recognition and reasoning as an intermediate inference step in an end-to-end model for pixel-level visual language understanding. We incorporate the outputs of such OCR tools, LLMs, and larger multimodal models as intermediate ``rationales'' on training data, and train a small student model to predict both rationales and answers for input questions based on those training examples. A student model based on Pix2Struct (282M parameters) achieves consistent improvements on three visual document understanding benchmarks representing infographics, scanned documents, and figures, with improvements of more than 4\% absolute over a comparable Pix2Struct model that predicts answers directly.
From Pixels to UI Actions: Learning to Follow Instructions via Graphical User Interfaces
May 31, 2023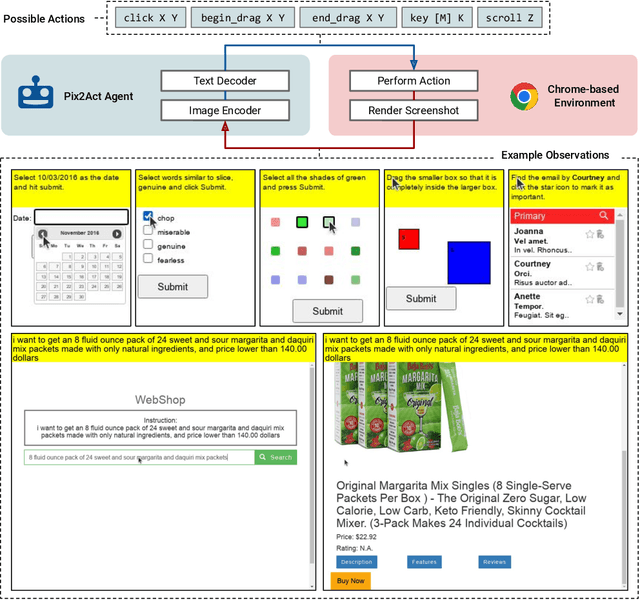
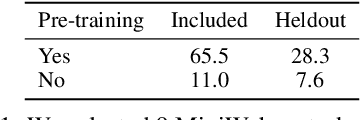
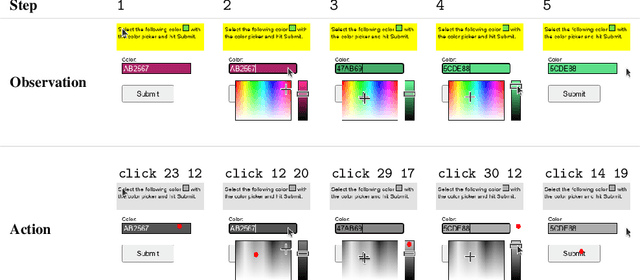
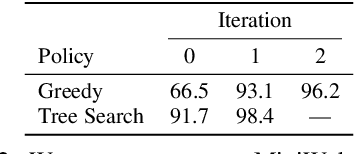
Much of the previous work towards digital agents for graphical user interfaces (GUIs) has relied on text-based representations (derived from HTML or other structured data sources), which are not always readily available. These input representations have been often coupled with custom, task-specific action spaces. This paper focuses on creating agents that interact with the digital world using the same conceptual interface that humans commonly use -- via pixel-based screenshots and a generic action space corresponding to keyboard and mouse actions. Building upon recent progress in pixel-based pretraining, we show, for the first time, that it is possible for such agents to outperform human crowdworkers on the MiniWob++ benchmark of GUI-based instruction following tasks.
PaLI-X: On Scaling up a Multilingual Vision and Language Model
May 29, 2023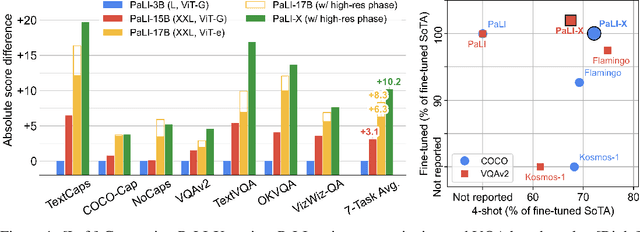
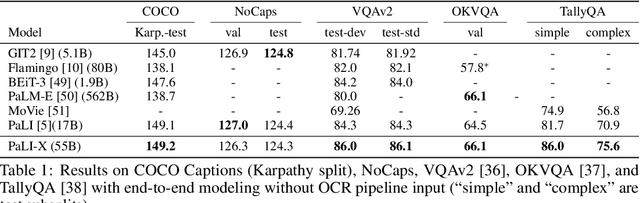
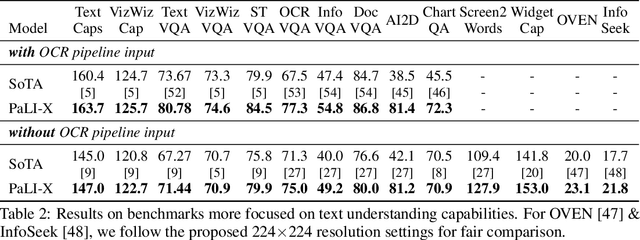

We present the training recipe and results of scaling up PaLI-X, a multilingual vision and language model, both in terms of size of the components and the breadth of its training task mixture. Our model achieves new levels of performance on a wide-range of varied and complex tasks, including multiple image-based captioning and question-answering tasks, image-based document understanding and few-shot (in-context) learning, as well as object detection, video question answering, and video captioning. PaLI-X advances the state-of-the-art on most vision-and-language benchmarks considered (25+ of them). Finally, we observe emerging capabilities, such as complex counting and multilingual object detection, tasks that are not explicitly in the training mix.
Open-domain Visual Entity Recognition: Towards Recognizing Millions of Wikipedia Entities
Feb 24, 2023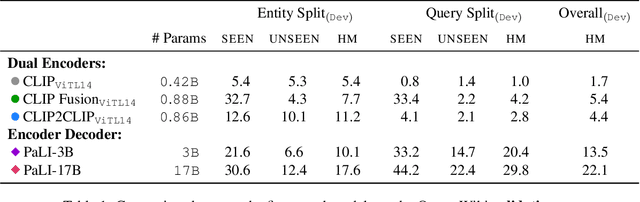
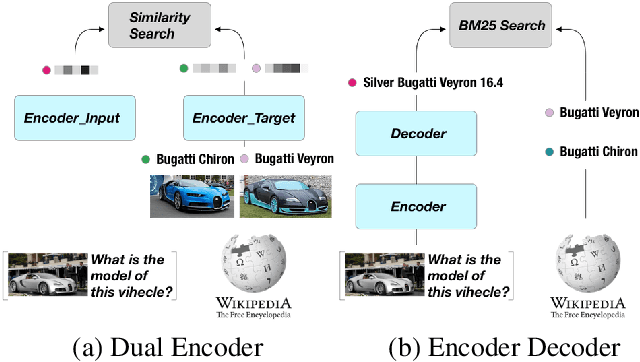
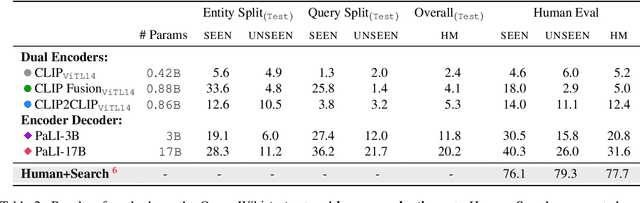

Large-scale multi-modal pre-training models such as CLIP and PaLI exhibit strong generalization on various visual domains and tasks. However, existing image classification benchmarks often evaluate recognition on a specific domain (e.g., outdoor images) or a specific task (e.g., classifying plant species), which falls short of evaluating whether pre-trained foundational models are universal visual recognizers. To address this, we formally present the task of Open-domain Visual Entity recognitioN (OVEN), where a model need to link an image onto a Wikipedia entity with respect to a text query. We construct OVEN-Wiki by re-purposing 14 existing datasets with all labels grounded onto one single label space: Wikipedia entities. OVEN challenges models to select among six million possible Wikipedia entities, making it a general visual recognition benchmark with the largest number of labels. Our study on state-of-the-art pre-trained models reveals large headroom in generalizing to the massive-scale label space. We show that a PaLI-based auto-regressive visual recognition model performs surprisingly well, even on Wikipedia entities that have never been seen during fine-tuning. We also find existing pretrained models yield different strengths: while PaLI-based models obtain higher overall performance, CLIP-based models are better at recognizing tail entities.
DePlot: One-shot visual language reasoning by plot-to-table translation
Dec 20, 2022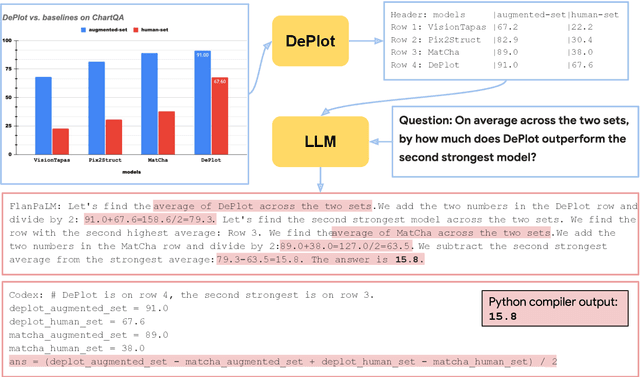
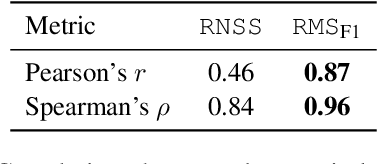
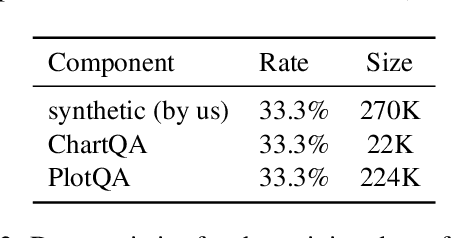
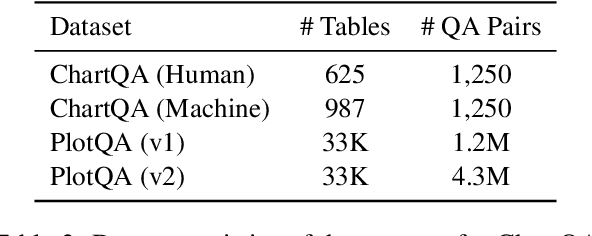
Visual language such as charts and plots is ubiquitous in the human world. Comprehending plots and charts requires strong reasoning skills. Prior state-of-the-art (SOTA) models require at least tens of thousands of training examples and their reasoning capabilities are still much limited, especially on complex human-written queries. This paper presents the first one-shot solution to visual language reasoning. We decompose the challenge of visual language reasoning into two steps: (1) plot-to-text translation, and (2) reasoning over the translated text. The key in this method is a modality conversion module, named as DePlot, which translates the image of a plot or chart to a linearized table. The output of DePlot can then be directly used to prompt a pretrained large language model (LLM), exploiting the few-shot reasoning capabilities of LLMs. To obtain DePlot, we standardize the plot-to-table task by establishing unified task formats and metrics, and train DePlot end-to-end on this task. DePlot can then be used off-the-shelf together with LLMs in a plug-and-play fashion. Compared with a SOTA model finetuned on more than >28k data points, DePlot+LLM with just one-shot prompting achieves a 24.0% improvement over finetuned SOTA on human-written queries from the task of chart QA.
MatCha: Enhancing Visual Language Pretraining with Math Reasoning and Chart Derendering
Dec 19, 2022



Visual language data such as plots, charts, and infographics are ubiquitous in the human world. However, state-of-the-art vision-language models do not perform well on these data. We propose MatCha (Math reasoning and Chart derendering pretraining) to enhance visual language models' capabilities in jointly modeling charts/plots and language data. Specifically, we propose several pretraining tasks that cover plot deconstruction and numerical reasoning which are the key capabilities in visual language modeling. We perform the MatCha pretraining starting from Pix2Struct, a recently proposed image-to-text visual language model. On standard benchmarks such as PlotQA and ChartQA, the MatCha model outperforms state-of-the-art methods by as much as nearly 20%. We also examine how well MatCha pretraining transfers to domains such as screenshots, textbook diagrams, and document figures and observe overall improvement, verifying the usefulness of MatCha pretraining on broader visual language tasks.
Pix2Struct: Screenshot Parsing as Pretraining for Visual Language Understanding
Oct 07, 2022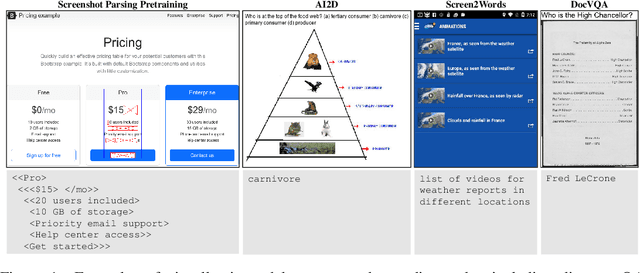


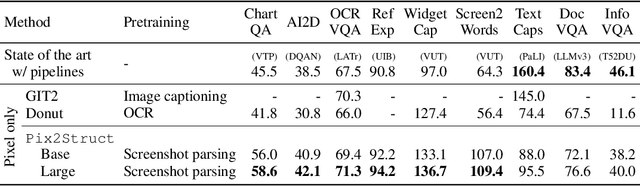
Visually-situated language is ubiquitous -- sources range from textbooks with diagrams to web pages with images and tables, to mobile apps with buttons and forms. Perhaps due to this diversity, previous work has typically relied on domain-specific recipes with limited sharing of the underlying data, model architectures, and objectives. We present Pix2Struct, a pretrained image-to-text model for purely visual language understanding, which can be finetuned on tasks containing visually-situated language. Pix2Struct is pretrained by learning to parse masked screenshots of web pages into simplified HTML. The web, with its richness of visual elements cleanly reflected in the HTML structure, provides a large source of pretraining data well suited to the diversity of downstream tasks. Intuitively, this objective subsumes common pretraining signals such as OCR, language modeling, image captioning. In addition to the novel pretraining strategy, we introduce a variable-resolution input representation and a more flexible integration of language and vision inputs, where language prompts such as questions are rendered directly on top of the input image. For the first time, we show that a single pretrained model can achieve state-of-the-art results in six out of nine tasks across four domains: documents, illustrations, user interfaces, and natural images.
Few-shot Mining of Naturally Occurring Inputs and Outputs
May 09, 2022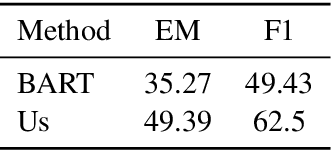
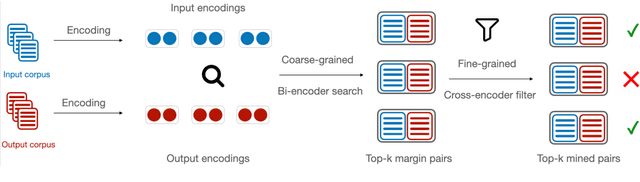
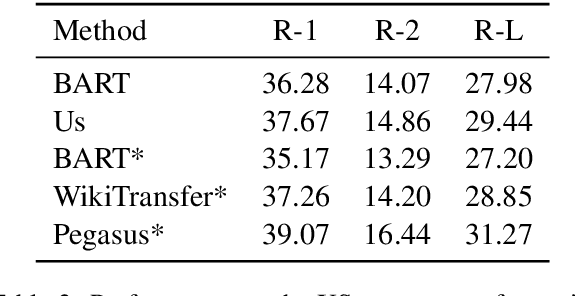

Creating labeled natural language training data is expensive and requires significant human effort. We mine input output examples from large corpora using a supervised mining function trained using a small seed set of only 100 examples. The mining consists of two stages -- (1) a biencoder-based recall-oriented dense search which pairs inputs with potential outputs, and (2) a crossencoder-based filter which re-ranks the output of the biencoder stage for better precision. Unlike model-generated data augmentation, our method mines naturally occurring high-quality input output pairs to mimic the style of the seed set for multiple tasks. On SQuAD-style reading comprehension, augmenting the seed set with the mined data results in an improvement of 13 F1 over a BART-large baseline fine-tuned only on the seed set. Likewise, we see improvements of 1.46 ROUGE-L on Xsum abstractive summarization.