 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZero-Shot Iterative Formalization and Planning in Partially Observable Environments
May 19, 2025In planning, using LLMs not to predict plans but to formalize an environment into the Planning Domain Definition Language (PDDL) has been shown to greatly improve performance and control. While most work focused on fully observable environments, we tackle the more realistic and challenging partially observable environments where existing methods are incapacitated by the lack of complete information. We propose PDDLego+, a framework to iteratively formalize, plan, grow, and refine PDDL representations in a zero-shot manner, without needing access to any existing trajectories. On two textual simulated environments, we show that PDDLego+ not only achieves superior performance, but also shows robustness against problem complexity. We also show that the domain knowledge captured after a successful trial is interpretable and benefits future tasks.
MEGA-Bench: Scaling Multimodal Evaluation to over 500 Real-World Tasks
Oct 14, 2024



We present MEGA-Bench, an evaluation suite that scales multimodal evaluation to over 500 real-world tasks, to address the highly heterogeneous daily use cases of end users. Our objective is to optimize for a set of high-quality data samples that cover a highly diverse and rich set of multimodal tasks, while enabling cost-effective and accurate model evaluation. In particular, we collected 505 realistic tasks encompassing over 8,000 samples from 16 expert annotators to extensively cover the multimodal task space. Instead of unifying these problems into standard multi-choice questions (like MMMU, MMBench, and MMT-Bench), we embrace a wide range of output formats like numbers, phrases, code, \LaTeX, coordinates, JSON, free-form, etc. To accommodate these formats, we developed over 40 metrics to evaluate these tasks. Unlike existing benchmarks, MEGA-Bench offers a fine-grained capability report across multiple dimensions (e.g., application, input type, output format, skill), allowing users to interact with and visualize model capabilities in depth. We evaluate a wide variety of frontier vision-language models on MEGA-Bench to understand their capabilities across these dimensions.
TLDR: Token-Level Detective Reward Model for Large Vision Language Models
Oct 07, 2024



Although reward models have been successful in improving multimodal large language models, the reward models themselves remain brutal and contain minimal information. Notably, existing reward models only mimic human annotations by assigning only one binary feedback to any text, no matter how long the text is. In the realm of multimodal language models, where models are required to process both images and texts, a naive reward model may learn implicit biases toward texts and become less grounded in images. In this paper, we propose a $\textbf{T}$oken-$\textbf{L}$evel $\textbf{D}$etective $\textbf{R}$eward Model ($\textbf{TLDR}$) to provide fine-grained annotations to each text token. We first introduce a perturbation-based method to generate synthetic hard negatives and their token-level labels to train TLDR models. Then we show the rich usefulness of TLDR models both in assisting off-the-shelf models to self-correct their generations, and in serving as a hallucination evaluation tool. Finally, we show that TLDR models can significantly speed up human annotation by 3 times to acquire a broader range of high-quality vision language data.
ST-RetNet: A Long-term Spatial-Temporal Traffic Flow Prediction Method
Jul 13, 2024



Traffic flow forecasting is considered a critical task in the field of intelligent transportation systems. In this paper, to address the issue of low accuracy in long-term forecasting of spatial-temporal big data on traffic flow, we propose an innovative model called Spatial-Temporal Retentive Network (ST-RetNet). We extend the Retentive Network to address the task of traffic flow forecasting. At the spatial scale, we integrate a topological graph structure into Spatial Retentive Network(S-RetNet), utilizing an adaptive adjacency matrix to extract dynamic spatial features of the road network. We also employ Graph Convolutional Networks to extract static spatial features of the road network. These two components are then fused to capture dynamic and static spatial correlations. At the temporal scale, we propose the Temporal Retentive Network(T-RetNet), which has been demonstrated to excel in capturing long-term dependencies in traffic flow patterns compared to other time series models, including Recurrent Neural Networks based and transformer models. We achieve the spatial-temporal traffic flow forecasting task by integrating S-RetNet and T-RetNet to form ST-RetNet. Through experimental comparisons conducted on four real-world datasets, we demonstrate that ST-RetNet outperforms the state-of-the-art approaches in traffic flow forecasting.
Language Models can Infer Action Semantics for Classical Planners from Environment Feedback
Jun 04, 2024



Classical planning approaches guarantee finding a set of actions that can achieve a given goal state when possible, but require an expert to specify logical action semantics that govern the dynamics of the environment. Researchers have shown that Large Language Models (LLMs) can be used to directly infer planning steps based on commonsense knowledge and minimal domain information alone, but such plans often fail on execution. We bring together the strengths of classical planning and LLM commonsense inference to perform domain induction, learning and validating action pre- and post-conditions based on closed-loop interactions with the environment itself. We propose PSALM, which leverages LLM inference to heuristically complete partial plans emitted by a classical planner given partial domain knowledge, as well as to infer the semantic rules of the domain in a logical language based on environment feedback after execution. Our analysis on 7 environments shows that with just one expert-curated example plans, using LLMs as heuristic planners and rule predictors achieves lower environment execution steps and environment resets than random exploration while simultaneously recovering the underlying ground truth action semantics of the domain.
Hybrid Transformer and Spatial-Temporal Self-Supervised Learning for Long-term Traffic Prediction
Jan 29, 2024Long-term traffic prediction has always been a challenging task due to its dynamic temporal dependencies and complex spatial dependencies. In this paper, we propose a model that combines hybrid Transformer and spatio-temporal self-supervised learning. The model enhances its robustness by applying adaptive data augmentation techniques at the sequence-level and graph-level of the traffic data. It utilizes Transformer to overcome the limitations of recurrent neural networks in capturing long-term sequences, and employs Chebyshev polynomial graph convolution to capture complex spatial dependencies. Furthermore, considering the impact of spatio-temporal heterogeneity on traffic speed, we design two self-supervised learning tasks to model the temporal and spatial heterogeneity, thereby improving the accuracy and generalization ability of the model. Experimental evaluations are conducted on two real-world datasets, PeMS04 and PeMS08, and the results are visualized and analyzed, demonstrating the superior performance of the proposed model.
Does VLN Pretraining Work with Nonsensical or Irrelevant Instructions?
Dec 02, 2023



Data augmentation via back-translation is common when pretraining Vision-and-Language Navigation (VLN) models, even though the generated instructions are noisy. But: does that noise matter? We find that nonsensical or irrelevant language instructions during pretraining can have little effect on downstream performance for both HAMT and VLN-BERT on R2R, and is still better than only using clean, human data. To underscore these results, we concoct an efficient augmentation method, Unigram + Object, which generates nonsensical instructions that nonetheless improve downstream performance. Our findings suggest that what matters for VLN R2R pretraining is the quantity of visual trajectories, not the quality of instructions.
Efficient End-to-End Visual Document Understanding with Rationale Distillation
Nov 16, 2023



Understanding visually situated language requires recognizing text and visual elements, and interpreting complex layouts. State-of-the-art methods commonly use specialized pre-processing tools, such as optical character recognition (OCR) systems, that map document image inputs to extracted information in the space of textual tokens, and sometimes also employ large language models (LLMs) to reason in text token space. However, the gains from external tools and LLMs come at the cost of increased computational and engineering complexity. In this paper, we ask whether small pretrained image-to-text models can learn selective text or layout recognition and reasoning as an intermediate inference step in an end-to-end model for pixel-level visual language understanding. We incorporate the outputs of such OCR tools, LLMs, and larger multimodal models as intermediate ``rationales'' on training data, and train a small student model to predict both rationales and answers for input questions based on those training examples. A student model based on Pix2Struct (282M parameters) achieves consistent improvements on three visual document understanding benchmarks representing infographics, scanned documents, and figures, with improvements of more than 4\% absolute over a comparable Pix2Struct model that predicts answers directly.
Chain-of-Questions Training with Latent Answers for Robust Multistep Question Answering
May 24, 2023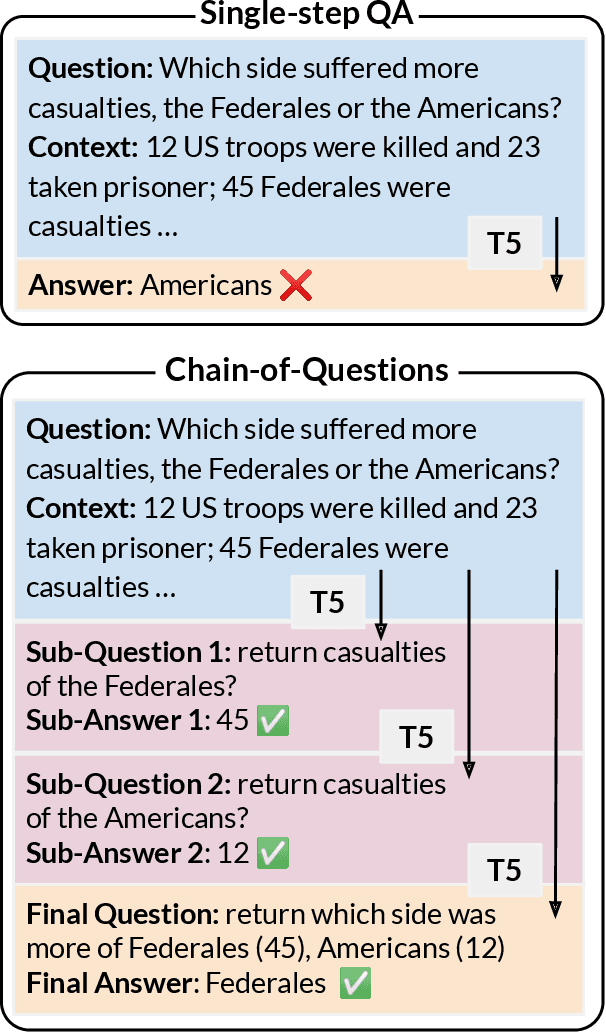
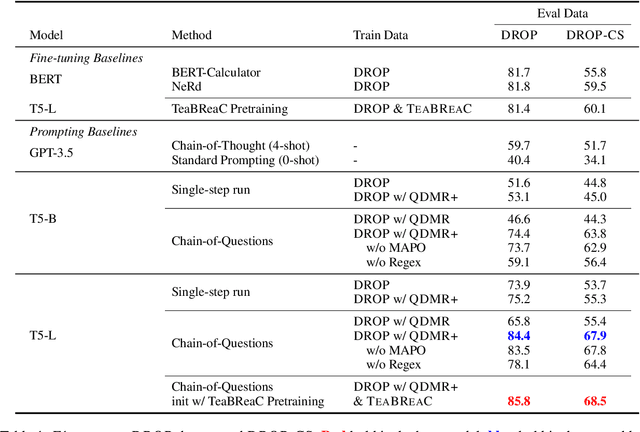
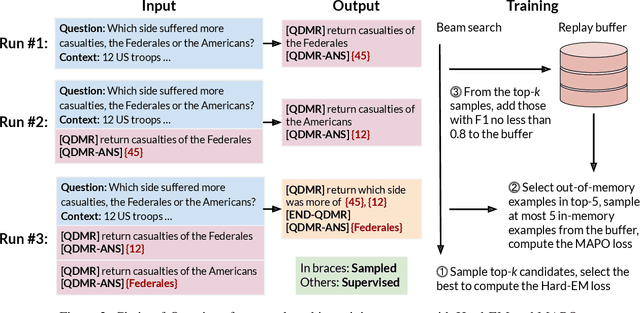
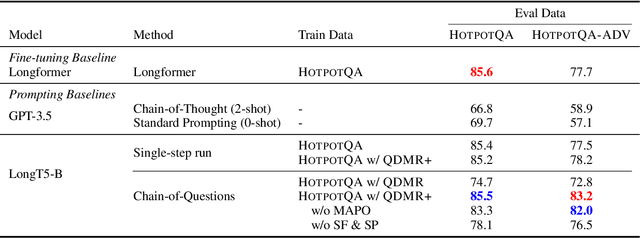
We train a language model (LM) to robustly answer multistep questions by generating and answering sub-questions. We propose Chain-of-Questions, a framework that trains a model to generate sub-questions and sub-answers one at a time by leveraging human annotated question decomposition meaning representation (QDMR). The key technical challenge is that QDMR only contains sub-questions but not answers to those sub-questions, so we treat sub-answers as latent variables and optimize them using a novel dynamic mixture of Hard-EM and MAPO. Chain-of-Questions greatly outperforms strong neuro-symbolic methods by 9.0 F1 on DROP contrast set, and outperforms GPT-3.5 by 24.3 F1 on HOTPOTQA adversarial set, thus demonstrating the effectiveness and robustness of our framework.
Generalization Differences between End-to-End and Neuro-Symbolic Vision-Language Reasoning Systems
Oct 26, 2022



For vision-and-language reasoning tasks, both fully connectionist, end-to-end methods and hybrid, neuro-symbolic methods have achieved high in-distribution performance. In which out-of-distribution settings does each paradigm excel? We investigate this question on both single-image and multi-image visual question-answering through four types of generalization tests: a novel segment-combine test for multi-image queries, contrast set, compositional generalization, and cross-benchmark transfer. Vision-and-language end-to-end trained systems exhibit sizeable performance drops across all these tests. Neuro-symbolic methods suffer even more on cross-benchmark transfer from GQA to VQA, but they show smaller accuracy drops on the other generalization tests and their performance quickly improves by few-shot training. Overall, our results demonstrate the complementary benefits of these two paradigms, and emphasize the importance of using a diverse suite of generalization tests to fully characterize model robustness to distribution shift.