 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWords that make SENSE: Sensorimotor Norms in Learned Lexical Token Representations
Jan 31, 2026While word embeddings derive meaning from co-occurrence patterns, human language understanding is grounded in sensory and motor experience. We present $\text{SENSE}$ $(\textbf{S}\text{ensorimotor }$ $\textbf{E}\text{mbedding }$ $\textbf{N}\text{orm }$ $\textbf{S}\text{coring }$ $\textbf{E}\text{ngine})$, a learned projection model that predicts Lancaster sensorimotor norms from word lexical embeddings. We also conducted a behavioral study where 281 participants selected which among candidate nonce words evoked specific sensorimotor associations, finding statistically significant correlations between human selection rates and $\text{SENSE}$ ratings across 6 of the 11 modalities. Sublexical analysis of these nonce words selection rates revealed systematic phonosthemic patterns for the interoceptive norm, suggesting a path towards computationally proposing candidate phonosthemes from text data.
Maestro: Learning to Collaborate via Conditional Listwise Policy Optimization for Multi-Agent LLMs
Nov 08, 2025Multi-agent systems (MAS) built on Large Language Models (LLMs) are being used to approach complex problems and can surpass single model inference. However, their success hinges on navigating a fundamental cognitive tension: the need to balance broad, divergent exploration of the solution space with a principled, convergent synthesis to the optimal solution. Existing paradigms often struggle to manage this duality, leading to premature consensus, error propagation, and a critical credit assignment problem that fails to distinguish between genuine reasoning and superficially plausible arguments. To resolve this core challenge, we propose the Multi-Agent Exploration-Synthesis framework Through Role Orchestration (Maestro), a principled paradigm for collaboration that structurally decouples these cognitive modes. Maestro uses a collective of parallel Execution Agents for diverse exploration and a specialized Central Agent for convergent, evaluative synthesis. To operationalize this critical synthesis phase, we introduce Conditional Listwise Policy Optimization (CLPO), a reinforcement learning objective that disentangles signals for strategic decisions and tactical rationales. By combining decision-focused policy gradients with a list-wise ranking loss over justifications, CLPO achieves clean credit assignment and stronger comparative supervision. Experiments on mathematical reasoning and general problem-solving benchmarks demonstrate that Maestro, coupled with CLPO, consistently outperforms existing state-of-the-art multi-agent approaches, delivering absolute accuracy gains of 6% on average and up to 10% at best.
VeriMoA: A Mixture-of-Agents Framework for Spec-to-HDL Generation
Oct 31, 2025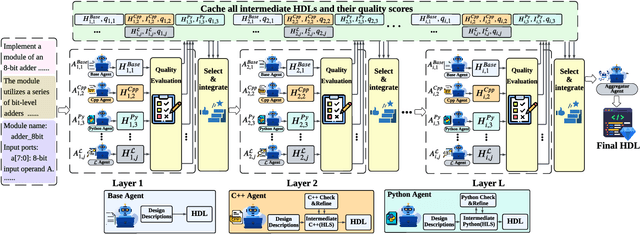
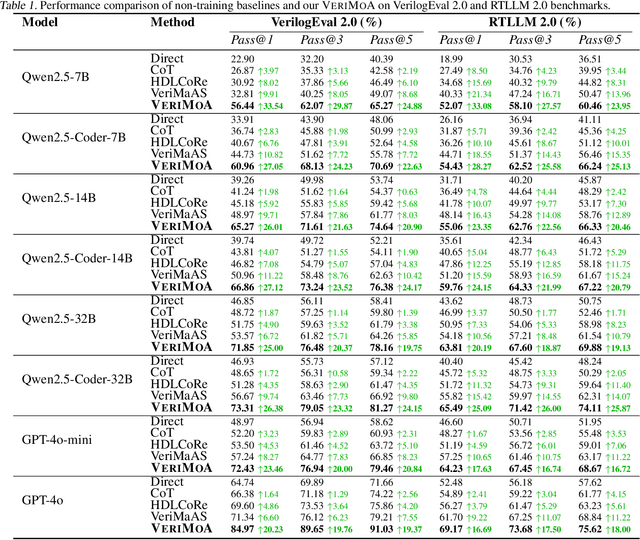
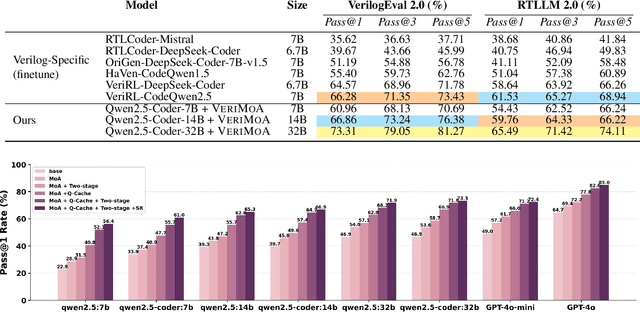
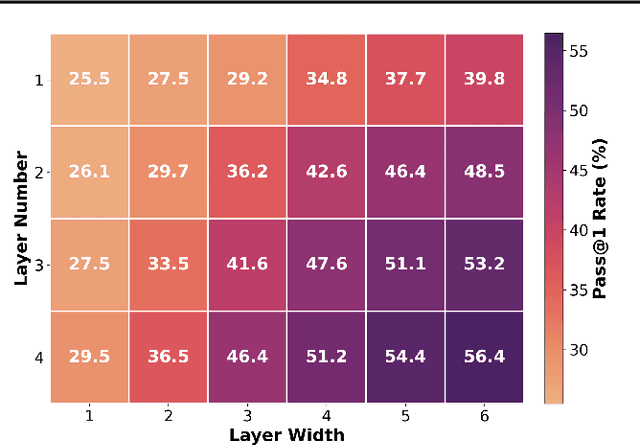
Automation of Register Transfer Level (RTL) design can help developers meet increasing computational demands. Large Language Models (LLMs) show promise for Hardware Description Language (HDL) generation, but face challenges due to limited parametric knowledge and domain-specific constraints. While prompt engineering and fine-tuning have limitations in knowledge coverage and training costs, multi-agent architectures offer a training-free paradigm to enhance reasoning through collaborative generation. However, current multi-agent approaches suffer from two critical deficiencies: susceptibility to noise propagation and constrained reasoning space exploration. We propose VeriMoA, a training-free mixture-of-agents (MoA) framework with two synergistic innovations. First, a quality-guided caching mechanism to maintain all intermediate HDL outputs and enables quality-based ranking and selection across the entire generation process, encouraging knowledge accumulation over layers of reasoning. Second, a multi-path generation strategy that leverages C++ and Python as intermediate representations, decomposing specification-to-HDL translation into two-stage processes that exploit LLM fluency in high-resource languages while promoting solution diversity. Comprehensive experiments on VerilogEval 2.0 and RTLLM 2.0 benchmarks demonstrate that VeriMoA achieves 15--30% improvements in Pass@1 across diverse LLM backbones, especially enabling smaller models to match larger models and fine-tuned alternatives without requiring costly training.
Phonological Representation Learning for Isolated Signs Improves Out-of-Vocabulary Generalization
Sep 05, 2025Sign language datasets are often not representative in terms of vocabulary, underscoring the need for models that generalize to unseen signs. Vector quantization is a promising approach for learning discrete, token-like representations, but it has not been evaluated whether the learned units capture spurious correlations that hinder out-of-vocabulary performance. This work investigates two phonological inductive biases: Parameter Disentanglement, an architectural bias, and Phonological Semi-Supervision, a regularization technique, to improve isolated sign recognition of known signs and reconstruction quality of unseen signs with a vector-quantized autoencoder. The primary finding is that the learned representations from the proposed model are more effective for one-shot reconstruction of unseen signs and more discriminative for sign identification compared to a controlled baseline. This work provides a quantitative analysis of how explicit, linguistically-motivated biases can improve the generalization of learned representations of sign language.
Learning to Deliberate: Meta-policy Collaboration for Agentic LLMs with Multi-agent Reinforcement Learning
Sep 04, 2025Multi-agent systems of large language models (LLMs) show promise for complex reasoning, but their effectiveness is often limited by fixed collaboration protocols. These frameworks typically focus on macro-level orchestration while overlooking agents' internal deliberative capabilities. This critical meta-cognitive blindspot treats agents as passive executors unable to adapt their strategy based on internal cognitive states like uncertainty or confidence. We introduce the Meta-Policy Deliberation Framework (MPDF), where agents learn a decentralized policy over a set of high-level meta-cognitive actions: Persist, Refine, and Concede. To overcome the instability of traditional policy gradients in this setting, we develop SoftRankPO, a novel reinforcement learning algorithm. SoftRankPO stabilizes training by shaping advantages based on the rank of rewards mapped through smooth normal quantiles, making the learning process robust to reward variance. Experiments show that MPDF with SoftRankPO achieves a a 4-5% absolute gain in average accuracy across five mathematical and general reasoning benchmarks compared to six state-of-the-art heuristic and learning-based multi-agent reasoning algorithms. Our work presents a paradigm for learning adaptive, meta-cognitive policies for multi-agent LLM systems, shifting the focus from designing fixed protocols to learning dynamic, deliberative strategies.
From Calibration to Collaboration: LLM Uncertainty Quantification Should Be More Human-Centered
Jun 09, 2025Large Language Models (LLMs) are increasingly assisting users in the real world, yet their reliability remains a concern. Uncertainty quantification (UQ) has been heralded as a tool to enhance human-LLM collaboration by enabling users to know when to trust LLM predictions. We argue that current practices for uncertainty quantification in LLMs are not optimal for developing useful UQ for human users making decisions in real-world tasks. Through an analysis of 40 LLM UQ methods, we identify three prevalent practices hindering the community's progress toward its goal of benefiting downstream users: 1) evaluating on benchmarks with low ecological validity; 2) considering only epistemic uncertainty; and 3) optimizing metrics that are not necessarily indicative of downstream utility. For each issue, we propose concrete user-centric practices and research directions that LLM UQ researchers should consider. Instead of hill-climbing on unrepresentative tasks using imperfect metrics, we argue that the community should adopt a more human-centered approach to LLM uncertainty quantification.
HAND Me the Data: Fast Robot Adaptation via Hand Path Retrieval
May 28, 2025



We hand the community HAND, a simple and time-efficient method for teaching robots new manipulation tasks through human hand demonstrations. Instead of relying on task-specific robot demonstrations collected via teleoperation, HAND uses easy-to-provide hand demonstrations to retrieve relevant behaviors from task-agnostic robot play data. Using a visual tracking pipeline, HAND extracts the motion of the human hand from the hand demonstration and retrieves robot sub-trajectories in two stages: first filtering by visual similarity, then retrieving trajectories with similar behaviors to the hand. Fine-tuning a policy on the retrieved data enables real-time learning of tasks in under four minutes, without requiring calibrated cameras or detailed hand pose estimation. Experiments also show that HAND outperforms retrieval baselines by over 2x in average task success rates on real robots. Videos can be found at our project website: https://liralab.usc.edu/handretrieval/.
TNG-CLIP:Training-Time Negation Data Generation for Negation Awareness of CLIP
May 24, 2025Vision-language models (VLMs), such as CLIP, have demonstrated strong performance across a range of downstream tasks. However, CLIP is still limited in negation understanding: the ability to recognize the absence or exclusion of a concept. Existing methods address the problem by using a large language model (LLM) to generate large-scale data of image captions containing negation for further fine-tuning CLIP. However, these methods are both time- and compute-intensive, and their evaluations are typically restricted to image-text matching tasks. To expand the horizon, we (1) introduce a training-time negation data generation pipeline such that negation captions are generated during the training stage, which only increases 2.5% extra training time, and (2) we propose the first benchmark, Neg-TtoI, for evaluating text-to-image generation models on prompts containing negation, assessing model's ability to produce semantically accurate images. We show that our proposed method, TNG-CLIP, achieves SOTA performance on diverse negation benchmarks of image-to-text matching, text-to-image retrieval, and image generation.
Large Language Models Do Multi-Label Classification Differently
May 23, 2025Multi-label classification is prevalent in real-world settings, but the behavior of Large Language Models (LLMs) in this setting is understudied. We investigate how autoregressive LLMs perform multi-label classification, with a focus on subjective tasks, by analyzing the output distributions of the models in each generation step. We find that their predictive behavior reflects the multiple steps in the underlying language modeling required to generate all relevant labels as they tend to suppress all but one label at each step. We further observe that as model scale increases, their token distributions exhibit lower entropy, yet the internal ranking of the labels improves. Finetuning methods such as supervised finetuning and reinforcement learning amplify this phenomenon. To further study this issue, we introduce the task of distribution alignment for multi-label settings: aligning LLM-derived label distributions with empirical distributions estimated from annotator responses in subjective tasks. We propose both zero-shot and supervised methods which improve both alignment and predictive performance over existing approaches.
Zero-Shot Iterative Formalization and Planning in Partially Observable Environments
May 19, 2025In planning, using LLMs not to predict plans but to formalize an environment into the Planning Domain Definition Language (PDDL) has been shown to greatly improve performance and control. While most work focused on fully observable environments, we tackle the more realistic and challenging partially observable environments where existing methods are incapacitated by the lack of complete information. We propose PDDLego+, a framework to iteratively formalize, plan, grow, and refine PDDL representations in a zero-shot manner, without needing access to any existing trajectories. On two textual simulated environments, we show that PDDLego+ not only achieves superior performance, but also shows robustness against problem complexity. We also show that the domain knowledge captured after a successful trial is interpretable and benefits future tasks.