 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExpert Personas Improve LLM Alignment but Damage Accuracy: Bootstrapping Intent-Based Persona Routing with PRISM
Mar 19, 2026Persona prompting can steer LLM generation towards a domain-specific tone and pattern. This behavior enables use cases in multi-agent systems where diverse interactions are crucial and human-centered tasks require high-level human alignment. Prior works provide mixed opinions on their utility: some report performance gains when using expert personas for certain domains and their contribution to data diversity in synthetic data creation, while others find near-zero or negative impact on general utility. To fully leverage the benefits of the LLM persona and avoid its harmfulness, a more comprehensive investigation of the mechanism is crucial. In this work, we study how model optimization, task type, prompt length, and placement can impact expert persona effectiveness across instruction-tuned and reasoning LLMs, and provide insight into conditions under which expert personas fail and succeed. Based on our findings, we developed a pipeline to fully leverage the benefits of an expert persona, named PRISM (Persona Routing via Intent-based Self-Modeling), which self-distills an intent-conditioned expert persona into a gated LoRA adapter through a bootstrapping process that requires no external data, models, or knowledge. PRISM enhances human preference and safety alignment on generative tasks while maintaining accuracy on discriminative tasks across all models, with minimal memory and computing overhead.
Multi-modal Synthetic Data Training and Model Collapse: Insights from VLMs and Diffusion Models
May 10, 2025Recent research has highlighted the risk of generative model collapse, where performance progressively degrades when continually trained on self-generated data. However, existing exploration on model collapse is limited to single, unimodal models, limiting our understanding in more realistic scenarios, such as diverse multi-modal AI agents interacting autonomously through synthetic data and continually evolving. We expand the synthetic data training and model collapse study to multi-modal vision-language generative systems, such as vision-language models (VLMs) and text-to-image diffusion models, as well as recursive generate-train loops with multiple models. We find that model collapse, previously observed in single-modality generative models, exhibits distinct characteristics in the multi-modal context, such as improved vision-language alignment and increased variance in VLM image-captioning task. Additionally, we find that general approaches such as increased decoding budgets, greater model diversity, and relabeling with frozen models can effectively mitigate model collapse. Our findings provide initial insights and practical guidelines for reducing the risk of model collapse in self-improving multi-agent AI systems and curating robust multi-modal synthetic datasets.
Static Key Attention in Vision
Dec 09, 2024



The success of vision transformers is widely attributed to the expressive power of their dynamically parameterized multi-head self-attention mechanism. We examine the impact of substituting the dynamic parameterized key with a static key within the standard attention mechanism in Vision Transformers. Our findings reveal that static key attention mechanisms can match or even exceed the performance of standard self-attention. Integrating static key attention modules into a Metaformer backbone, we find that it serves as a better intermediate stage in hierarchical hybrid architectures, balancing the strengths of depth-wise convolution and self-attention. Experiments on several vision tasks underscore the effectiveness of the static key mechanism, indicating that the typical two-step dynamic parameterization in attention can be streamlined to a single step without impacting performance under certain circumstances.
Lateralization MLP: A Simple Brain-inspired Architecture for Diffusion
May 25, 2024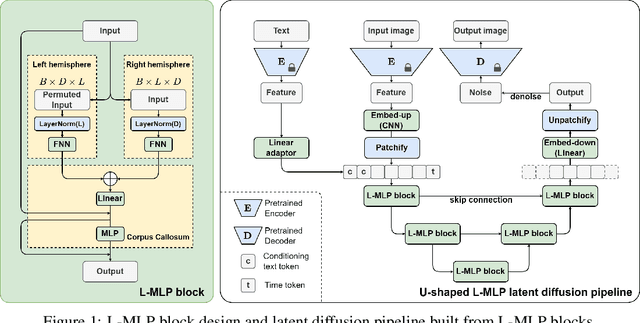
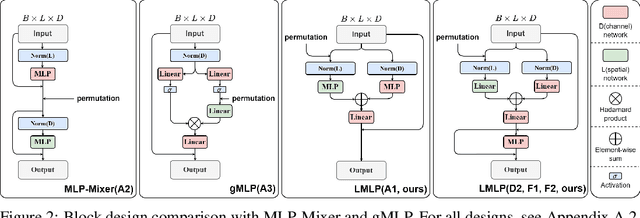
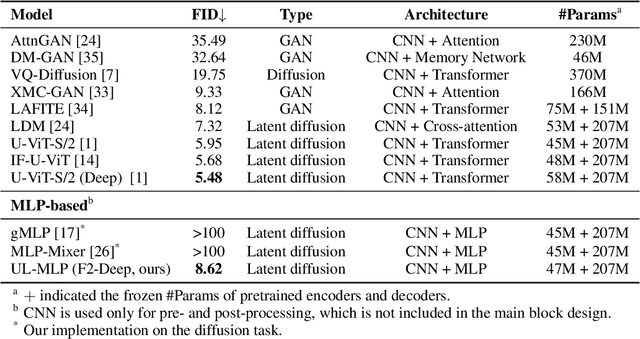
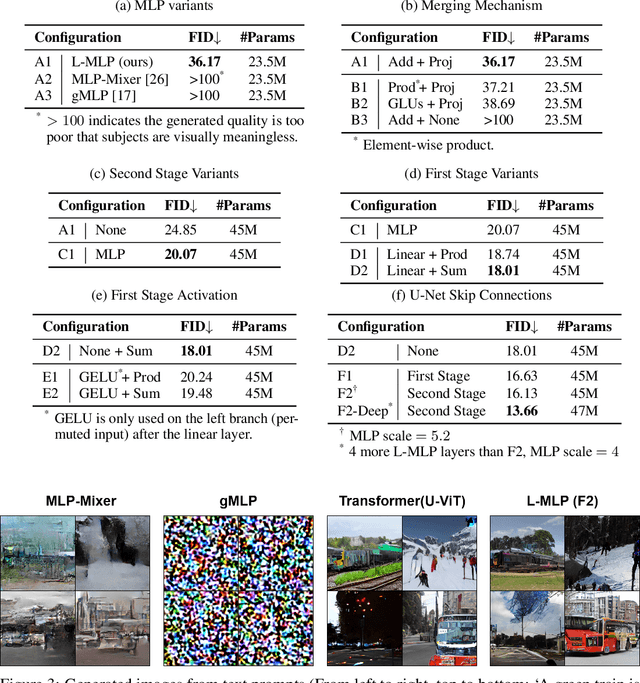
The Transformer architecture has dominated machine learning in a wide range of tasks. The specific characteristic of this architecture is an expensive scaled dot-product attention mechanism that models the inter-token interactions, which is known to be the reason behind its success. However, such a mechanism does not have a direct parallel to the human brain which brings the question if the scaled-dot product is necessary for intelligence with strong expressive power. Inspired by the lateralization of the human brain, we propose a new simple but effective architecture called the Lateralization MLP (L-MLP). Stacking L-MLP blocks can generate complex architectures. Each L-MLP block is based on a multi-layer perceptron (MLP) that permutes data dimensions, processes each dimension in parallel, merges them, and finally passes through a joint MLP. We discover that this specific design outperforms other MLP variants and performs comparably to a transformer-based architecture in the challenging diffusion task while being highly efficient. We conduct experiments using text-to-image generation tasks to demonstrate the effectiveness and efficiency of L-MLP. Further, we look into the model behavior and discover a connection to the function of the human brain. Our code is publicly available: \url{https://github.com/zizhao-hu/L-MLP}
An Intermediate Fusion ViT Enables Efficient Text-Image Alignment in Diffusion Models
Mar 25, 2024

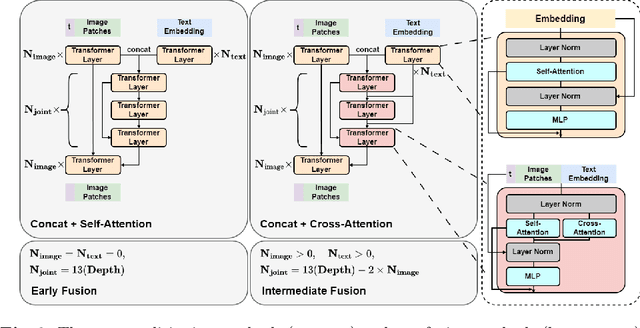

Diffusion models have been widely used for conditional data cross-modal generation tasks such as text-to-image and text-to-video. However, state-of-the-art models still fail to align the generated visual concepts with high-level semantics in a language such as object count, spatial relationship, etc. We approach this problem from a multimodal data fusion perspective and investigate how different fusion strategies can affect vision-language alignment. We discover that compared to the widely used early fusion of conditioning text in a pretrained image feature space, a specially designed intermediate fusion can: (i) boost text-to-image alignment with improved generation quality and (ii) improve training and inference efficiency by reducing low-rank text-to-image attention calculations. We perform experiments using a text-to-image generation task on the MS-COCO dataset. We compare our intermediate fusion mechanism with the classic early fusion mechanism on two common conditioning methods on a U-shaped ViT backbone. Our intermediate fusion model achieves a higher CLIP Score and lower FID, with 20% reduced FLOPs, and 50% increased training speed compared to a strong U-ViT baseline with an early fusion.
Efficient Multimodal Diffusion Models Using Joint Data Infilling with Partially Shared U-Net
Nov 28, 2023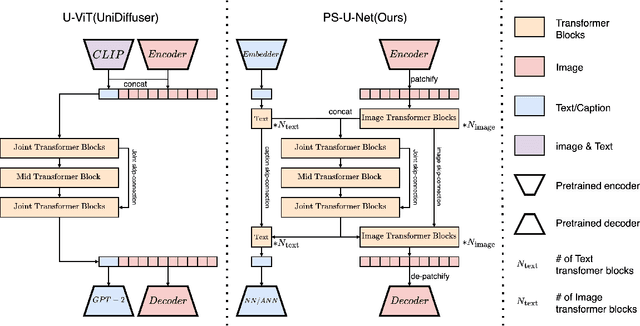
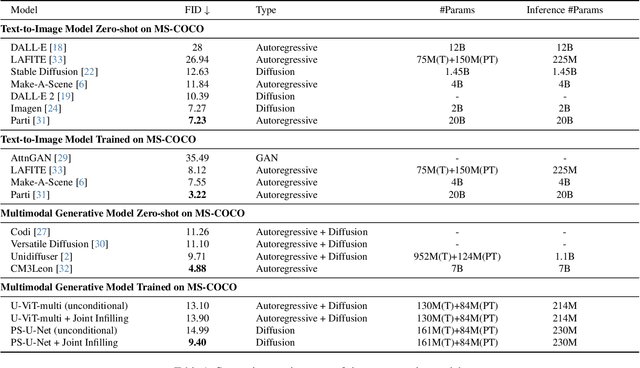
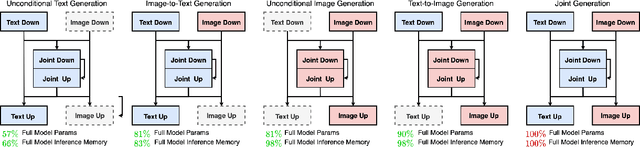
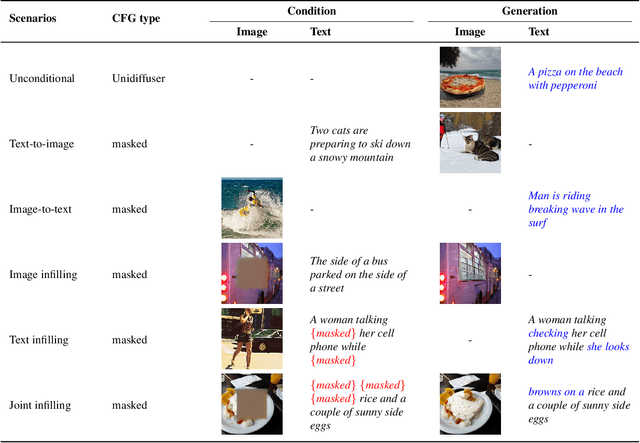
Recently, diffusion models have been used successfully to fit distributions for cross-modal data translation and multimodal data generation. However, these methods rely on extensive scaling, overlooking the inefficiency and interference between modalities. We develop Partially Shared U-Net (PS-U-Net) architecture which is an efficient multimodal diffusion model that allows text and image inputs to pass through dedicated layers and skip-connections for preserving modality-specific fine-grained details. Inspired by image inpainting, we also propose a new efficient multimodal sampling method that introduces new scenarios for conditional generation while only requiring a simple joint distribution to be learned. Our empirical exploration of the MS-COCO dataset demonstrates that our method generates multimodal text and image data with higher quality compared to existing multimodal diffusion models while having a comparable size, faster training, faster multimodal sampling, and more flexible generation.
Class-Incremental Learning Using Generative Experience Replay Based on Time-aware Regularization
Oct 05, 2023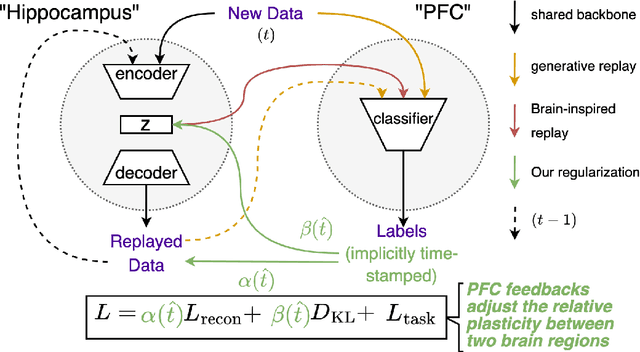
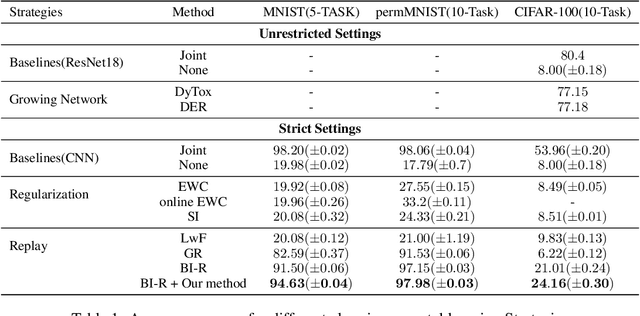


Learning new tasks accumulatively without forgetting remains a critical challenge in continual learning. Generative experience replay addresses this challenge by synthesizing pseudo-data points for past learned tasks and later replaying them for concurrent training along with the new tasks' data. Generative replay is the best strategy for continual learning under a strict class-incremental setting when certain constraints need to be met: (i) constant model size, (ii) no pre-training dataset, and (iii) no memory buffer for storing past tasks' data. Inspired by the biological nervous system mechanisms, we introduce a time-aware regularization method to dynamically fine-tune the three training objective terms used for generative replay: supervised learning, latent regularization, and data reconstruction. Experimental results on major benchmarks indicate that our method pushes the limit of brain-inspired continual learners under such strict settings, improves memory retention, and increases the average performance over continually arriving tasks.
Cognitively Inspired Cross-Modal Data Generation Using Diffusion Models
May 28, 2023Most existing cross-modal generative methods based on diffusion models use guidance to provide control over the latent space to enable conditional generation across different modalities. Such methods focus on providing guidance through separately-trained models, each for one modality. As a result, these methods suffer from cross-modal information loss and are limited to unidirectional conditional generation. Inspired by how humans synchronously acquire multi-modal information and learn the correlation between modalities, we explore a multi-modal diffusion model training and sampling scheme that uses channel-wise image conditioning to learn cross-modality correlation during the training phase to better mimic the learning process in the brain. Our empirical results demonstrate that our approach can achieve data generation conditioned on all correlated modalities.
Encoding Binary Concepts in the Latent Space of Generative Models for Enhancing Data Representation
Mar 22, 2023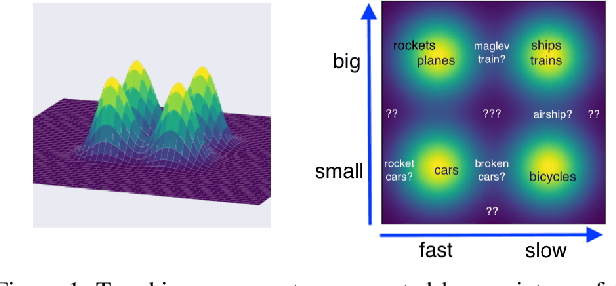
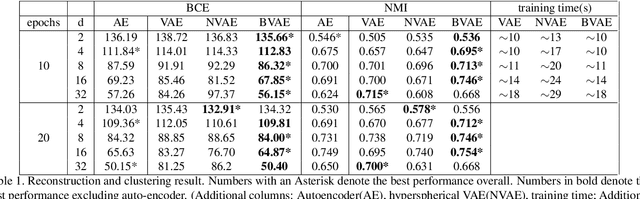
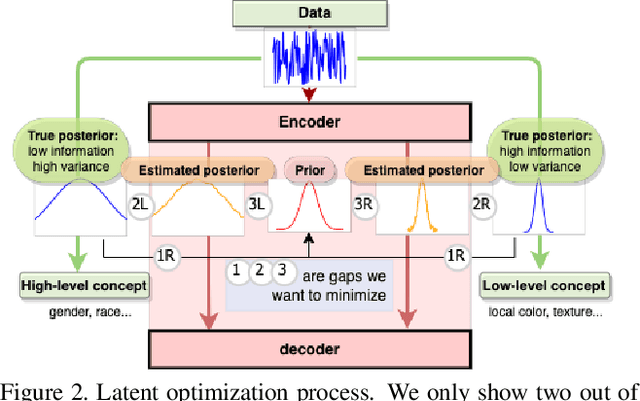
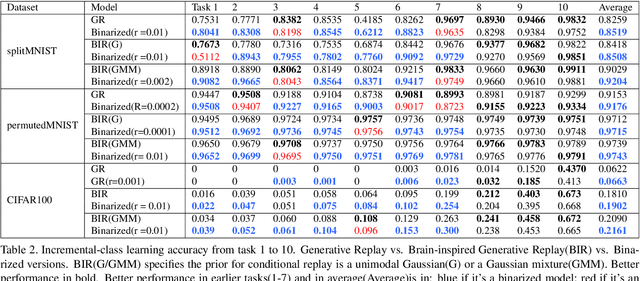
Binary concepts are empirically used by humans to generalize efficiently. And they are based on Bernoulli distribution which is the building block of information. These concepts span both low-level and high-level features such as "large vs small" and "a neuron is active or inactive". Binary concepts are ubiquitous features and can be used to transfer knowledge to improve model generalization. We propose a novel binarized regularization to facilitate learning of binary concepts to improve the quality of data generation in autoencoders. We introduce a binarizing hyperparameter $r$ in data generation process to disentangle the latent space symmetrically. We demonstrate that this method can be applied easily to existing variational autoencoder (VAE) variants to encourage symmetric disentanglement, improve reconstruction quality, and prevent posterior collapse without computation overhead. We also demonstrate that this method can boost existing models to learn more transferable representations and generate more representative samples for the input distribution which can alleviate catastrophic forgetting using generative replay under continual learning settings.
Evaluating NLP Systems On a Novel Cloze Task: Judging the Plausibility of Possible Fillers in Instructional Texts
Dec 03, 2021
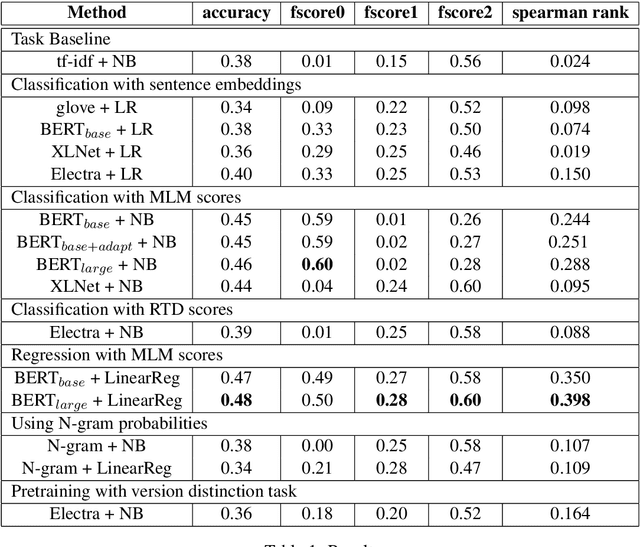

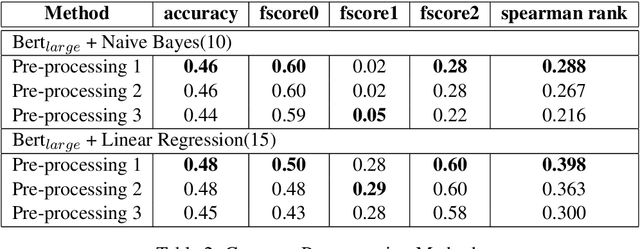
Cloze task is a widely used task to evaluate an NLP system's language understanding ability. However, most of the existing cloze tasks only require NLP systems to give the relative best prediction for each input data sample, rather than the absolute quality of all possible predictions, in a consistent way across the input domain. Thus a new task is proposed: predicting if a filler word in a cloze task is a good, neutral, or bad candidate. Complicated versions can be extended to predicting more discrete classes or continuous scores. We focus on subtask A in Semeval 2022 task 7, explored some possible architectures to solve this new task, provided a detailed comparison of them, and proposed an ensemble method to improve traditional models in this new task.