 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Intermediate Fusion ViT Enables Efficient Text-Image Alignment in Diffusion Models
Paper and Code
Mar 25, 2024

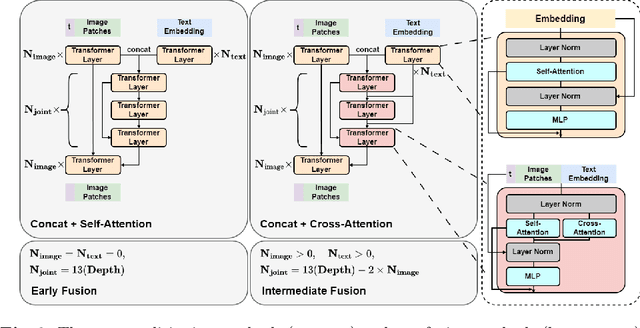

Diffusion models have been widely used for conditional data cross-modal generation tasks such as text-to-image and text-to-video. However, state-of-the-art models still fail to align the generated visual concepts with high-level semantics in a language such as object count, spatial relationship, etc. We approach this problem from a multimodal data fusion perspective and investigate how different fusion strategies can affect vision-language alignment. We discover that compared to the widely used early fusion of conditioning text in a pretrained image feature space, a specially designed intermediate fusion can: (i) boost text-to-image alignment with improved generation quality and (ii) improve training and inference efficiency by reducing low-rank text-to-image attention calculations. We perform experiments using a text-to-image generation task on the MS-COCO dataset. We compare our intermediate fusion mechanism with the classic early fusion mechanism on two common conditioning methods on a U-shaped ViT backbone. Our intermediate fusion model achieves a higher CLIP Score and lower FID, with 20% reduced FLOPs, and 50% increased training speed compared to a strong U-ViT baseline with an early fusion.