 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExpert Personas Improve LLM Alignment but Damage Accuracy: Bootstrapping Intent-Based Persona Routing with PRISM
Mar 19, 2026Persona prompting can steer LLM generation towards a domain-specific tone and pattern. This behavior enables use cases in multi-agent systems where diverse interactions are crucial and human-centered tasks require high-level human alignment. Prior works provide mixed opinions on their utility: some report performance gains when using expert personas for certain domains and their contribution to data diversity in synthetic data creation, while others find near-zero or negative impact on general utility. To fully leverage the benefits of the LLM persona and avoid its harmfulness, a more comprehensive investigation of the mechanism is crucial. In this work, we study how model optimization, task type, prompt length, and placement can impact expert persona effectiveness across instruction-tuned and reasoning LLMs, and provide insight into conditions under which expert personas fail and succeed. Based on our findings, we developed a pipeline to fully leverage the benefits of an expert persona, named PRISM (Persona Routing via Intent-based Self-Modeling), which self-distills an intent-conditioned expert persona into a gated LoRA adapter through a bootstrapping process that requires no external data, models, or knowledge. PRISM enhances human preference and safety alignment on generative tasks while maintaining accuracy on discriminative tasks across all models, with minimal memory and computing overhead.
Finetune-Informed Pretraining Boosts Downstream Performance
Jan 27, 2026Multimodal pretraining is effective for building general-purpose representations, but in many practical deployments, only one modality is heavily used during downstream fine-tuning. Standard pretraining strategies treat all modalities uniformly, which can lead to under-optimized representations for the modality that actually matters. We propose Finetune-Informed Pretraining (FIP), a model-agnostic method that biases representation learning toward a designated target modality needed at fine-tuning time. FIP combines higher masking difficulty, stronger loss weighting, and increased decoder capacity for the target modality, without modifying the shared encoder or requiring additional supervision. When applied to masked modeling on constellation diagrams for wireless signals, FIP consistently improves downstream fine-tuned performance with no extra data or compute. FIP is simple to implement, architecture-compatible, and broadly applicable across multimodal masked modeling pipelines.
Semi-Supervised Masked Autoencoders: Unlocking Vision Transformer Potential with Limited Data
Jan 27, 2026We address the challenge of training Vision Transformers (ViTs) when labeled data is scarce but unlabeled data is abundant. We propose Semi-Supervised Masked Autoencoder (SSMAE), a framework that jointly optimizes masked image reconstruction and classification using both unlabeled and labeled samples with dynamically selected pseudo-labels. SSMAE introduces a validation-driven gating mechanism that activates pseudo-labeling only after the model achieves reliable, high-confidence predictions that are consistent across both weakly and strongly augmented views of the same image, reducing confirmation bias. On CIFAR-10 and CIFAR-100, SSMAE consistently outperforms supervised ViT and fine-tuned MAE, with the largest gains in low-label regimes (+9.24% over ViT on CIFAR-10 with 10% labels). Our results demonstrate that when pseudo-labels are introduced is as important as how they are generated for data-efficient transformer training. Codes are available at https://github.com/atik666/ssmae.
CageDroneRF: A Large-Scale RF Benchmark and Toolkit for Drone Perception
Jan 06, 2026We present CageDroneRF (CDRF), a large-scale benchmark for Radio-Frequency (RF) drone detection and identification built from real-world captures and systematically generated synthetic variants. CDRF addresses the scarcity and limited diversity of existing RF datasets by coupling extensive raw recordings with a principled augmentation pipeline that (i) precisely controls Signal-to-Noise Ratio (SNR), (ii) injects interfering emitters, and (iii) applies frequency shifts with label-consistent bounding-box transformations for detection. This dataset spans a wide range of contemporary drone models, many unavailable in current public datasets, and acquisition conditions, derived from data collected at the Rowan University campus and within a controlled RF-cage facility. CDRF is released with interoperable open-source tools for data generation, preprocessing, augmentation, and evaluation that also operate on existing public benchmarks. CDRF enables standardized benchmarking for classification, open-set recognition, and object detection, supporting rigorous comparisons and reproducible pipelines. By releasing this comprehensive benchmark and tooling, CDRF aims to accelerate progress toward robust, generalizable RF perception models.
TNG-CLIP:Training-Time Negation Data Generation for Negation Awareness of CLIP
May 24, 2025Vision-language models (VLMs), such as CLIP, have demonstrated strong performance across a range of downstream tasks. However, CLIP is still limited in negation understanding: the ability to recognize the absence or exclusion of a concept. Existing methods address the problem by using a large language model (LLM) to generate large-scale data of image captions containing negation for further fine-tuning CLIP. However, these methods are both time- and compute-intensive, and their evaluations are typically restricted to image-text matching tasks. To expand the horizon, we (1) introduce a training-time negation data generation pipeline such that negation captions are generated during the training stage, which only increases 2.5% extra training time, and (2) we propose the first benchmark, Neg-TtoI, for evaluating text-to-image generation models on prompts containing negation, assessing model's ability to produce semantically accurate images. We show that our proposed method, TNG-CLIP, achieves SOTA performance on diverse negation benchmarks of image-to-text matching, text-to-image retrieval, and image generation.
Multi-modal Synthetic Data Training and Model Collapse: Insights from VLMs and Diffusion Models
May 10, 2025Recent research has highlighted the risk of generative model collapse, where performance progressively degrades when continually trained on self-generated data. However, existing exploration on model collapse is limited to single, unimodal models, limiting our understanding in more realistic scenarios, such as diverse multi-modal AI agents interacting autonomously through synthetic data and continually evolving. We expand the synthetic data training and model collapse study to multi-modal vision-language generative systems, such as vision-language models (VLMs) and text-to-image diffusion models, as well as recursive generate-train loops with multiple models. We find that model collapse, previously observed in single-modality generative models, exhibits distinct characteristics in the multi-modal context, such as improved vision-language alignment and increased variance in VLM image-captioning task. Additionally, we find that general approaches such as increased decoding budgets, greater model diversity, and relabeling with frozen models can effectively mitigate model collapse. Our findings provide initial insights and practical guidelines for reducing the risk of model collapse in self-improving multi-agent AI systems and curating robust multi-modal synthetic datasets.
Plug-and-Play AMC: Context Is King in Training-Free, Open-Set Modulation with LLMs
May 06, 2025Automatic Modulation Classification (AMC) is critical for efficient spectrum management and robust wireless communications. However, AMC remains challenging due to the complex interplay of signal interference and noise. In this work, we propose an innovative framework that integrates traditional signal processing techniques with Large-Language Models (LLMs) to address AMC. Our approach leverages higher-order statistics and cumulant estimation to convert quantitative signal features into structured natural language prompts. By incorporating exemplar contexts into these prompts, our method exploits the LLM's inherent familiarity with classical signal processing, enabling effective one-shot classification without additional training or preprocessing (e.g., denoising). Experimental evaluations on synthetically generated datasets, spanning both noiseless and noisy conditions, demonstrate that our framework achieves competitive performance across diverse modulation schemes and Signal-to-Noise Ratios (SNRs). Moreover, our approach paves the way for robust foundation models in wireless communications across varying channel conditions, significantly reducing the expense associated with developing channel-specific models. This work lays the foundation for scalable, interpretable, and versatile signal classification systems in next-generation wireless networks. The source code is available at https://github.com/RU-SIT/context-is-king
Hybrid Learners Do Not Forget: A Brain-Inspired Neuro-Symbolic Approach to Continual Learning
Mar 16, 2025Continual learning is crucial for creating AI agents that can learn and improve themselves autonomously. A primary challenge in continual learning is to learn new tasks without losing previously learned knowledge. Current continual learning methods primarily focus on enabling a neural network with mechanisms that mitigate forgetting effects. Inspired by the two distinct systems in the human brain, System 1 and System 2, we propose a Neuro-Symbolic Brain-Inspired Continual Learning (NeSyBiCL) framework that incorporates two subsystems to solve continual learning: A neural network model responsible for quickly adapting to the most recent task, together with a symbolic reasoner responsible for retaining previously acquired knowledge from previous tasks. Moreover, we design an integration mechanism between these components to facilitate knowledge transfer from the symbolic reasoner to the neural network. We also introduce two compositional continual learning benchmarks and demonstrate that NeSyBiCL is effective and leads to superior performance compared to continual learning methods that merely rely on neural architectures to address forgetting.
DenoMAE2.0: Improving Denoising Masked Autoencoders by Classifying Local Patches
Feb 25, 2025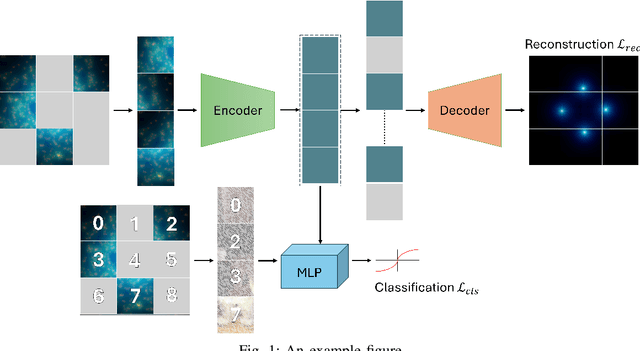
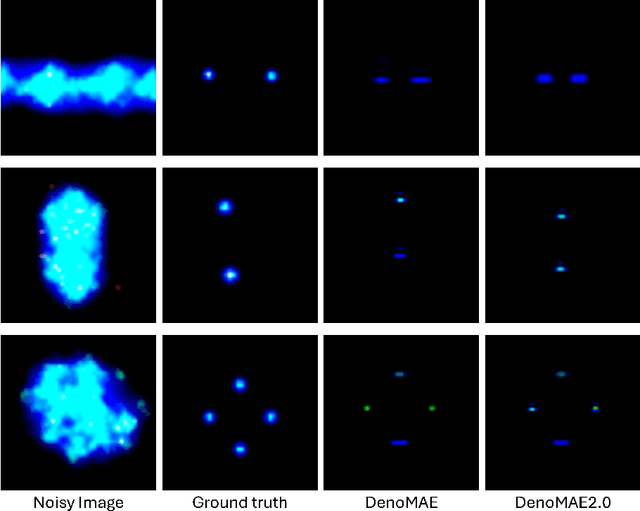
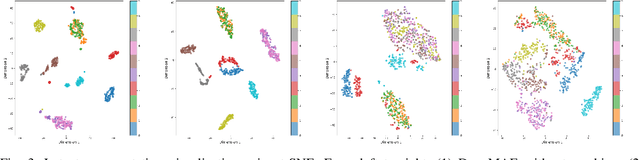
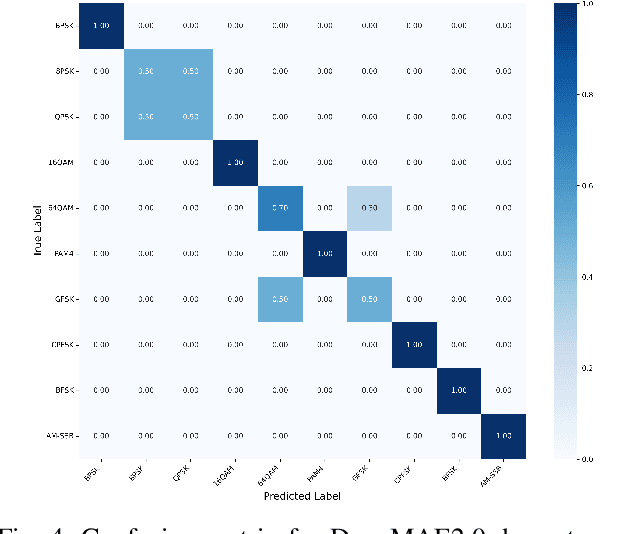
We introduce DenoMAE2.0, an enhanced denoising masked autoencoder that integrates a local patch classification objective alongside traditional reconstruction loss to improve representation learning and robustness. Unlike conventional Masked Autoencoders (MAE), which focus solely on reconstructing missing inputs, DenoMAE2.0 introduces position-aware classification of unmasked patches, enabling the model to capture fine-grained local features while maintaining global coherence. This dual-objective approach is particularly beneficial in semi-supervised learning for wireless communication, where high noise levels and data scarcity pose significant challenges. We conduct extensive experiments on modulation signal classification across a wide range of signal-to-noise ratios (SNRs), from extremely low to moderately high conditions and in a low data regime. Our results demonstrate that DenoMAE2.0 surpasses its predecessor, Deno-MAE, and other baselines in both denoising quality and downstream classification accuracy. DenoMAE2.0 achieves a 1.1% improvement over DenoMAE on our dataset and 11.83%, 16.55% significant improved accuracy gains on the RadioML benchmark, over DenoMAE, for constellation diagram classification of modulation signals.
Cross-domain Few-shot Object Detection with Multi-modal Textual Enrichment
Feb 23, 2025
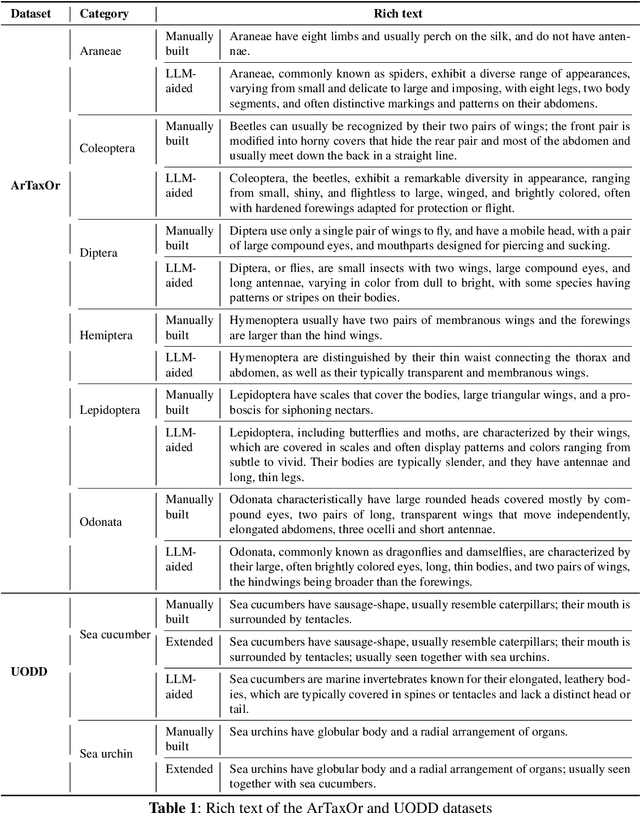
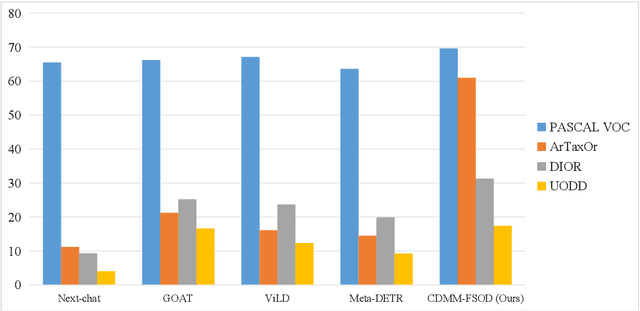
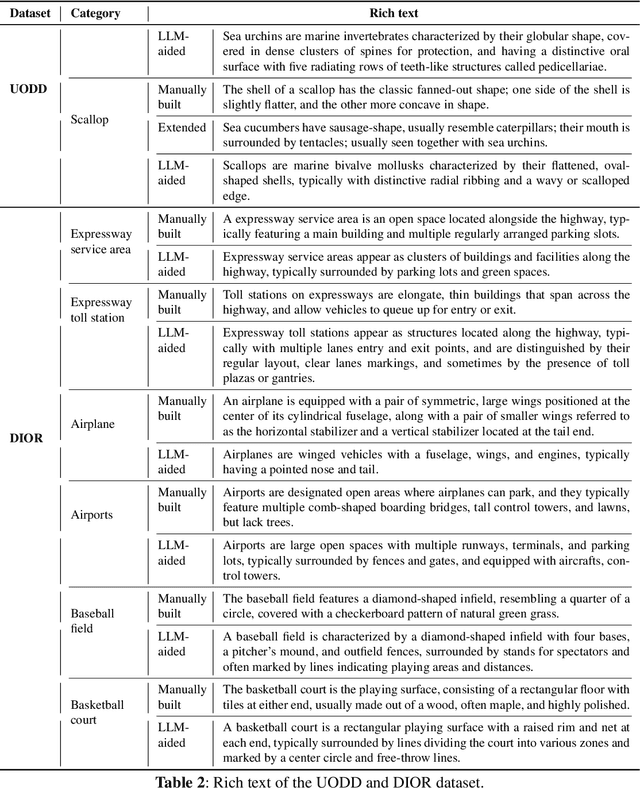
Advancements in cross-modal feature extraction and integration have significantly enhanced performance in few-shot learning tasks. However, current multi-modal object detection (MM-OD) methods often experience notable performance degradation when encountering substantial domain shifts. We propose that incorporating rich textual information can enable the model to establish a more robust knowledge relationship between visual instances and their corresponding language descriptions, thereby mitigating the challenges of domain shift. Specifically, we focus on the problem of Cross-Domain Multi-Modal Few-Shot Object Detection (CDMM-FSOD) and introduce a meta-learning-based framework designed to leverage rich textual semantics as an auxiliary modality to achieve effective domain adaptation. Our new architecture incorporates two key components: (i) A multi-modal feature aggregation module, which aligns visual and linguistic feature embeddings to ensure cohesive integration across modalities. (ii) A rich text semantic rectification module, which employs bidirectional text feature generation to refine multi-modal feature alignment, thereby enhancing understanding of language and its application in object detection. We evaluate the proposed method on common cross-domain object detection benchmarks and demonstrate that it significantly surpasses existing few-shot object detection approaches.