 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFairness or Fluency? An Investigation into Language Bias of Pairwise LLM-as-a-Judge
Jan 20, 2026Recent advances in Large Language Models (LLMs) have incentivized the development of LLM-as-a-judge, an application of LLMs where they are used as judges to decide the quality of a certain piece of text given a certain context. However, previous studies have demonstrated that LLM-as-a-judge can be biased towards different aspects of the judged texts, which often do not align with human preference. One of the identified biases is language bias, which indicates that the decision of LLM-as-a-judge can differ based on the language of the judged texts. In this paper, we study two types of language bias in pairwise LLM-as-a-judge: (1) performance disparity between languages when the judge is prompted to compare options from the same language, and (2) bias towards options written in major languages when the judge is prompted to compare options of two different languages. We find that for same-language judging, there exist significant performance disparities across language families, with European languages consistently outperforming African languages, and this bias is more pronounced in culturally-related subjects. For inter-language judging, we observe that most models favor English answers, and that this preference is influenced more by answer language than question language. Finally, we investigate whether language bias is in fact caused by low-perplexity bias, a previously identified bias of LLM-as-a-judge, and we find that while perplexity is slightly correlated with language bias, language bias cannot be fully explained by perplexity only.
GeoFlow-SLAM: A Robust Tightly-Coupled RGBD-Inertial Fusion SLAM for Dynamic Legged Robotics
Mar 18, 2025This paper presents GeoFlow-SLAM, a robust and effective Tightly-Coupled RGBD-inertial SLAM for legged robots operating in highly dynamic environments.By integrating geometric consistency, legged odometry constraints, and dual-stream optical flow (GeoFlow), our method addresses three critical challenges:feature matching and pose initialization failures during fast locomotion and visual feature scarcity in texture-less scenes.Specifically, in rapid motion scenarios, feature matching is notably enhanced by leveraging dual-stream optical flow, which combines prior map points and poses. Additionally, we propose a robust pose initialization method for fast locomotion and IMU error in legged robots, integrating IMU/Legged odometry, inter-frame Perspective-n-Point (PnP), and Generalized Iterative Closest Point (GICP). Furthermore, a novel optimization framework that tightly couples depth-to-map and GICP geometric constraints is first introduced to improve the robustness and accuracy in long-duration, visually texture-less environments. The proposed algorithms achieve state-of-the-art (SOTA) on collected legged robots and open-source datasets. To further promote research and development, the open-source datasets and code will be made publicly available at https://github.com/NSN-Hello/GeoFlow-SLAM
Static Key Attention in Vision
Dec 09, 2024



The success of vision transformers is widely attributed to the expressive power of their dynamically parameterized multi-head self-attention mechanism. We examine the impact of substituting the dynamic parameterized key with a static key within the standard attention mechanism in Vision Transformers. Our findings reveal that static key attention mechanisms can match or even exceed the performance of standard self-attention. Integrating static key attention modules into a Metaformer backbone, we find that it serves as a better intermediate stage in hierarchical hybrid architectures, balancing the strengths of depth-wise convolution and self-attention. Experiments on several vision tasks underscore the effectiveness of the static key mechanism, indicating that the typical two-step dynamic parameterization in attention can be streamlined to a single step without impacting performance under certain circumstances.
Gaussian Object Carver: Object-Compositional Gaussian Splatting with surfaces completion
Dec 03, 2024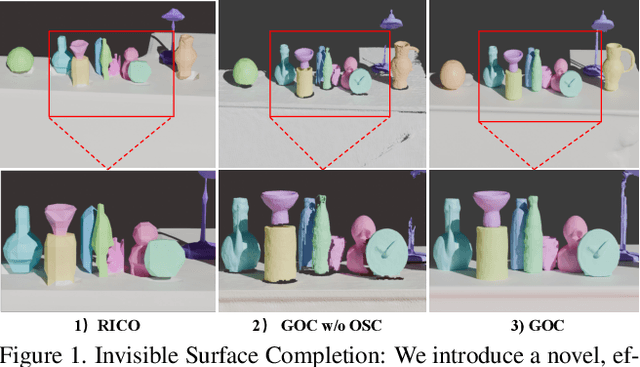

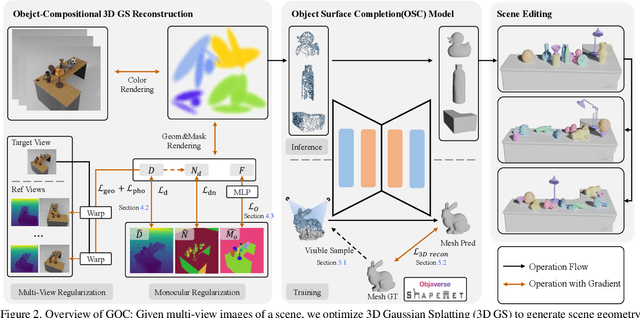
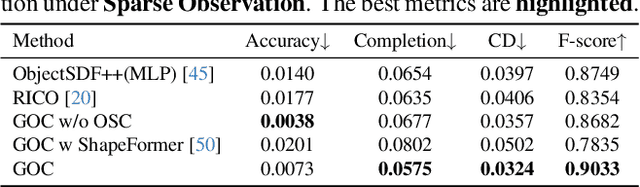
3D scene reconstruction is a foundational problem in computer vision. Despite recent advancements in Neural Implicit Representations (NIR), existing methods often lack editability and compositional flexibility, limiting their use in scenarios requiring high interactivity and object-level manipulation. In this paper, we introduce the Gaussian Object Carver (GOC), a novel, efficient, and scalable framework for object-compositional 3D scene reconstruction. GOC leverages 3D Gaussian Splatting (GS), enriched with monocular geometry priors and multi-view geometry regularization, to achieve high-quality and flexible reconstruction. Furthermore, we propose a zero-shot Object Surface Completion (OSC) model, which uses 3D priors from 3d object data to reconstruct unobserved surfaces, ensuring object completeness even in occluded areas. Experimental results demonstrate that GOC improves reconstruction efficiency and geometric fidelity. It holds promise for advancing the practical application of digital twins in embodied AI, AR/VR, and interactive simulation environments.