 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDreamLifting: A Plug-in Module Lifting MV Diffusion Models for 3D Asset Generation
Sep 09, 2025

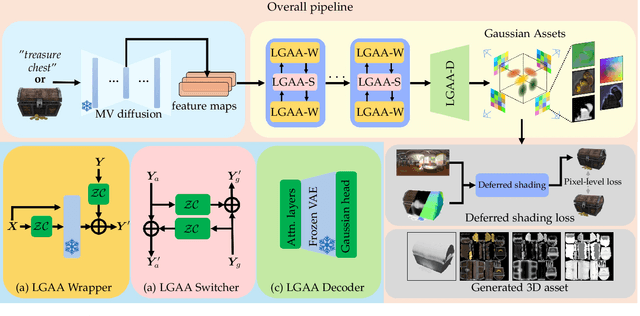

The labor- and experience-intensive creation of 3D assets with physically based rendering (PBR) materials demands an autonomous 3D asset creation pipeline. However, most existing 3D generation methods focus on geometry modeling, either baking textures into simple vertex colors or leaving texture synthesis to post-processing with image diffusion models. To achieve end-to-end PBR-ready 3D asset generation, we present Lightweight Gaussian Asset Adapter (LGAA), a novel framework that unifies the modeling of geometry and PBR materials by exploiting multi-view (MV) diffusion priors from a novel perspective. The LGAA features a modular design with three components. Specifically, the LGAA Wrapper reuses and adapts network layers from MV diffusion models, which encapsulate knowledge acquired from billions of images, enabling better convergence in a data-efficient manner. To incorporate multiple diffusion priors for geometry and PBR synthesis, the LGAA Switcher aligns multiple LGAA Wrapper layers encapsulating different knowledge. Then, a tamed variational autoencoder (VAE), termed LGAA Decoder, is designed to predict 2D Gaussian Splatting (2DGS) with PBR channels. Finally, we introduce a dedicated post-processing procedure to effectively extract high-quality, relightable mesh assets from the resulting 2DGS. Extensive quantitative and qualitative experiments demonstrate the superior performance of LGAA with both text-and image-conditioned MV diffusion models. Additionally, the modular design enables flexible incorporation of multiple diffusion priors, and the knowledge-preserving scheme leads to efficient convergence trained on merely 69k multi-view instances. Our code, pre-trained weights, and the dataset used will be publicly available via our project page: https://zx-yin.github.io/dreamlifting/.
RoboTransfer: Geometry-Consistent Video Diffusion for Robotic Visual Policy Transfer
May 29, 2025Imitation Learning has become a fundamental approach in robotic manipulation. However, collecting large-scale real-world robot demonstrations is prohibitively expensive. Simulators offer a cost-effective alternative, but the sim-to-real gap make it extremely challenging to scale. Therefore, we introduce RoboTransfer, a diffusion-based video generation framework for robotic data synthesis. Unlike previous methods, RoboTransfer integrates multi-view geometry with explicit control over scene components, such as background and object attributes. By incorporating cross-view feature interactions and global depth/normal conditions, RoboTransfer ensures geometry consistency across views. This framework allows fine-grained control, including background edits and object swaps. Experiments demonstrate that RoboTransfer is capable of generating multi-view videos with enhanced geometric consistency and visual fidelity. In addition, policies trained on the data generated by RoboTransfer achieve a 33.3% relative improvement in the success rate in the DIFF-OBJ setting and a substantial 251% relative improvement in the more challenging DIFF-ALL scenario. Explore more demos on our project page: https://horizonrobotics.github.io/robot_lab/robotransfer
DIPO: Dual-State Images Controlled Articulated Object Generation Powered by Diverse Data
May 28, 2025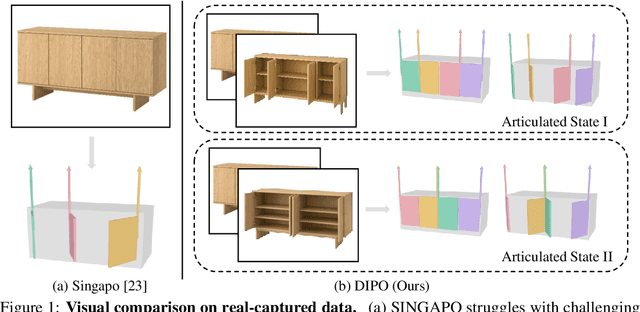
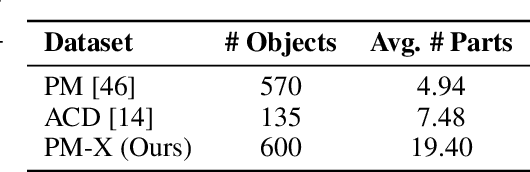
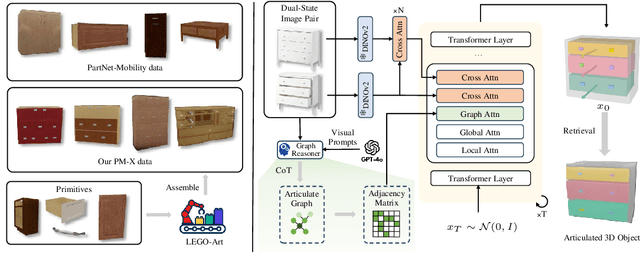
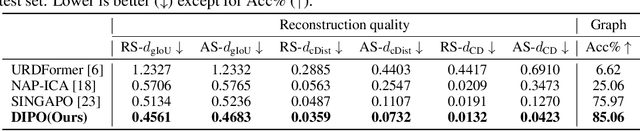
We present DIPO, a novel framework for the controllable generation of articulated 3D objects from a pair of images: one depicting the object in a resting state and the other in an articulated state. Compared to the single-image approach, our dual-image input imposes only a modest overhead for data collection, but at the same time provides important motion information, which is a reliable guide for predicting kinematic relationships between parts. Specifically, we propose a dual-image diffusion model that captures relationships between the image pair to generate part layouts and joint parameters. In addition, we introduce a Chain-of-Thought (CoT) based graph reasoner that explicitly infers part connectivity relationships. To further improve robustness and generalization on complex articulated objects, we develop a fully automated dataset expansion pipeline, name LEGO-Art, that enriches the diversity and complexity of PartNet-Mobility dataset. We propose PM-X, a large-scale dataset of complex articulated 3D objects, accompanied by rendered images, URDF annotations, and textual descriptions. Extensive experiments demonstrate that DIPO significantly outperforms existing baselines in both the resting state and the articulated state, while the proposed PM-X dataset further enhances generalization to diverse and structurally complex articulated objects. Our code and dataset will be released to the community upon publication.
GeoFlow-SLAM: A Robust Tightly-Coupled RGBD-Inertial Fusion SLAM for Dynamic Legged Robotics
Mar 18, 2025This paper presents GeoFlow-SLAM, a robust and effective Tightly-Coupled RGBD-inertial SLAM for legged robots operating in highly dynamic environments.By integrating geometric consistency, legged odometry constraints, and dual-stream optical flow (GeoFlow), our method addresses three critical challenges:feature matching and pose initialization failures during fast locomotion and visual feature scarcity in texture-less scenes.Specifically, in rapid motion scenarios, feature matching is notably enhanced by leveraging dual-stream optical flow, which combines prior map points and poses. Additionally, we propose a robust pose initialization method for fast locomotion and IMU error in legged robots, integrating IMU/Legged odometry, inter-frame Perspective-n-Point (PnP), and Generalized Iterative Closest Point (GICP). Furthermore, a novel optimization framework that tightly couples depth-to-map and GICP geometric constraints is first introduced to improve the robustness and accuracy in long-duration, visually texture-less environments. The proposed algorithms achieve state-of-the-art (SOTA) on collected legged robots and open-source datasets. To further promote research and development, the open-source datasets and code will be made publicly available at https://github.com/NSN-Hello/GeoFlow-SLAM
Gaussian Object Carver: Object-Compositional Gaussian Splatting with surfaces completion
Dec 03, 2024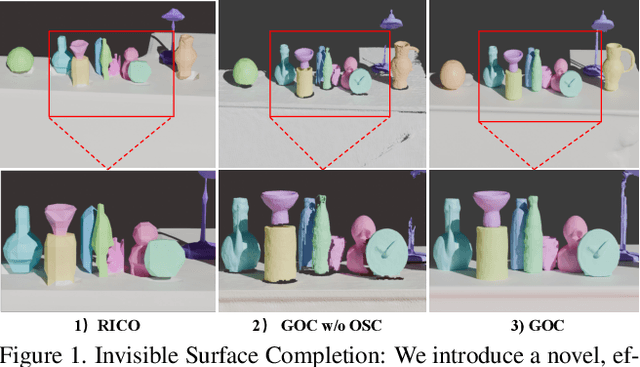

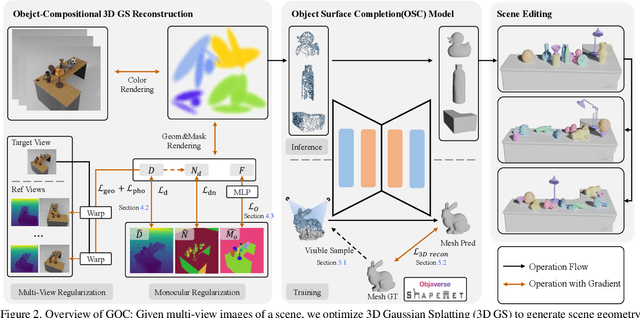
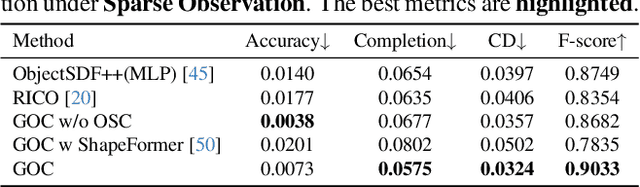
3D scene reconstruction is a foundational problem in computer vision. Despite recent advancements in Neural Implicit Representations (NIR), existing methods often lack editability and compositional flexibility, limiting their use in scenarios requiring high interactivity and object-level manipulation. In this paper, we introduce the Gaussian Object Carver (GOC), a novel, efficient, and scalable framework for object-compositional 3D scene reconstruction. GOC leverages 3D Gaussian Splatting (GS), enriched with monocular geometry priors and multi-view geometry regularization, to achieve high-quality and flexible reconstruction. Furthermore, we propose a zero-shot Object Surface Completion (OSC) model, which uses 3D priors from 3d object data to reconstruct unobserved surfaces, ensuring object completeness even in occluded areas. Experimental results demonstrate that GOC improves reconstruction efficiency and geometric fidelity. It holds promise for advancing the practical application of digital twins in embodied AI, AR/VR, and interactive simulation environments.
GLS: Geometry-aware 3D Language Gaussian Splatting
Nov 27, 2024



Recently, 3D Gaussian Splatting (3DGS) has achieved significant performance on indoor surface reconstruction and open-vocabulary segmentation. This paper presents GLS, a unified framework of surface reconstruction and open-vocabulary segmentation based on 3DGS. GLS extends two fields by exploring the correlation between them. For indoor surface reconstruction, we introduce surface normal prior as a geometric cue to guide the rendered normal, and use the normal error to optimize the rendered depth. For open-vocabulary segmentation, we employ 2D CLIP features to guide instance features and utilize DEVA masks to enhance their view consistency. Extensive experiments demonstrate the effectiveness of jointly optimizing surface reconstruction and open-vocabulary segmentation, where GLS surpasses state-of-the-art approaches of each task on MuSHRoom, ScanNet++, and LERF-OVS datasets. Code will be available at https://github.com/JiaxiongQ/GLS.
Multi-Space Neural Radiance Fields
May 07, 2023Existing Neural Radiance Fields (NeRF) methods suffer from the existence of reflective objects, often resulting in blurry or distorted rendering. Instead of calculating a single radiance field, we propose a multi-space neural radiance field (MS-NeRF) that represents the scene using a group of feature fields in parallel sub-spaces, which leads to a better understanding of the neural network toward the existence of reflective and refractive objects. Our multi-space scheme works as an enhancement to existing NeRF methods, with only small computational overheads needed for training and inferring the extra-space outputs. We demonstrate the superiority and compatibility of our approach using three representative NeRF-based models, i.e., NeRF, Mip-NeRF, and Mip-NeRF 360. Comparisons are performed on a novelly constructed dataset consisting of 25 synthetic scenes and 7 real captured scenes with complex reflection and refraction, all having 360-degree viewpoints. Extensive experiments show that our approach significantly outperforms the existing single-space NeRF methods for rendering high-quality scenes concerned with complex light paths through mirror-like objects. Our code and dataset will be publicly available at https://zx-yin.github.io/msnerf.
Looking Through the Glass: Neural Surface Reconstruction Against High Specular Reflections
Apr 18, 2023
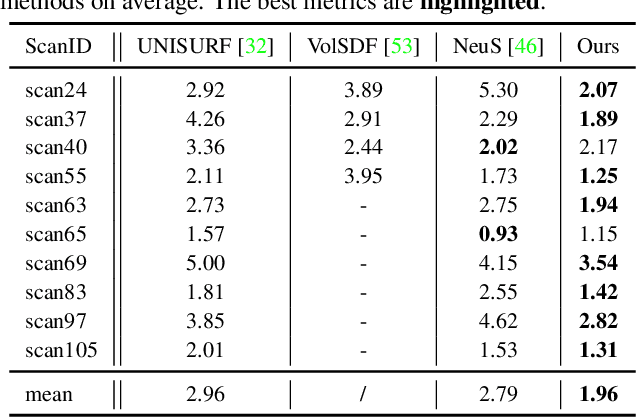


Neural implicit methods have achieved high-quality 3D object surfaces under slight specular highlights. However, high specular reflections (HSR) often appear in front of target objects when we capture them through glasses. The complex ambiguity in these scenes violates the multi-view consistency, then makes it challenging for recent methods to reconstruct target objects correctly. To remedy this issue, we present a novel surface reconstruction framework, NeuS-HSR, based on implicit neural rendering. In NeuS-HSR, the object surface is parameterized as an implicit signed distance function (SDF). To reduce the interference of HSR, we propose decomposing the rendered image into two appearances: the target object and the auxiliary plane. We design a novel auxiliary plane module by combining physical assumptions and neural networks to generate the auxiliary plane appearance. Extensive experiments on synthetic and real-world datasets demonstrate that NeuS-HSR outperforms state-of-the-art approaches for accurate and robust target surface reconstruction against HSR. Code is available at https://github.com/JiaxiongQ/NeuS-HSR.
SlimConv: Reducing Channel Redundancy in Convolutional Neural Networks by Weights Flipping
Mar 16, 2020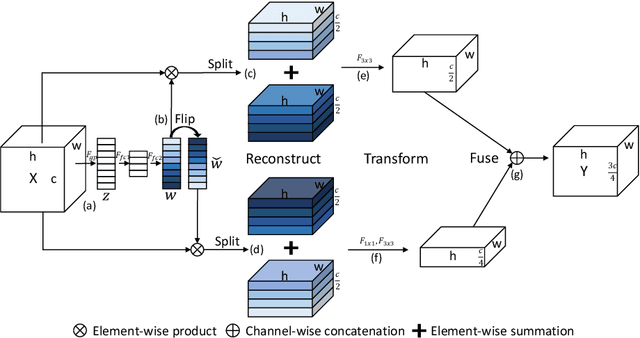
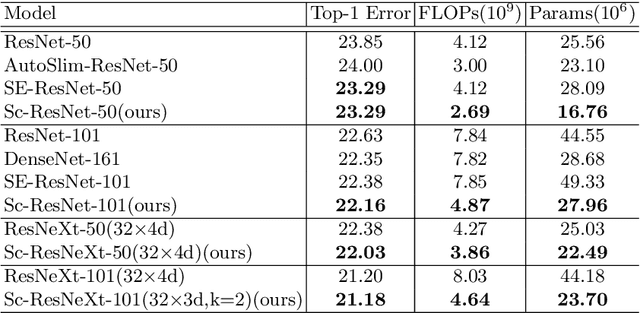
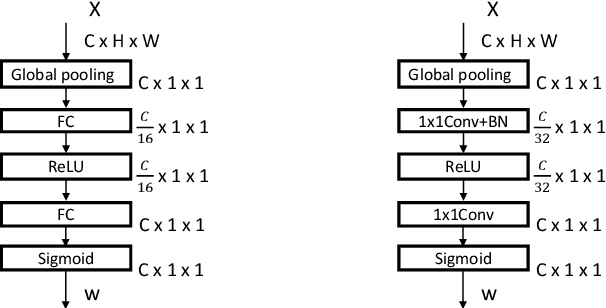
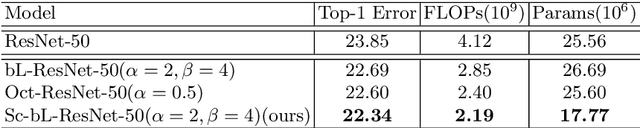
The channel redundancy in feature maps of convolutional neural networks (CNNs) results in the large consumption of memories and computational resources. In this work, we design a novel Slim Convolution (SlimConv) module to boost the performance of CNNs by reducing channel redundancies. Our SlimConv consists of three main steps: Reconstruct, Transform and Fuse, through which the features are splitted and reorganized in a more efficient way, such that the learned weights can be compressed effectively. In particular, the core of our model is a weight flipping operation which can largely improve the feature diversities, contributing to the performance crucially. Our SlimConv is a plug-and-play architectural unit which can be used to replace convolutional layers in CNNs directly. We validate the effectiveness of SlimConv by conducting comprehensive experiments on ImageNet, MS COCO2014, Pascal VOC2012 segmentation, and Pascal VOC2007 detection datasets. The experiments show that SlimConv-equipped models can achieve better performances consistently, less consumption of memory and computation resources than non-equipped conterparts. For example, the ResNet-101 fitted with SlimConv achieves 77.84% top-1 classification accuracy with 4.87 GFLOPs and 27.96M parameters on ImageNet, which shows almost 0.5% better performance with about 3 GFLOPs and 38% parameters reduced.
DeepBlindness: Fast Blindness Map Estimation and Blindness Type Classification for Outdoor Scene from Single Color Image
Nov 02, 2019
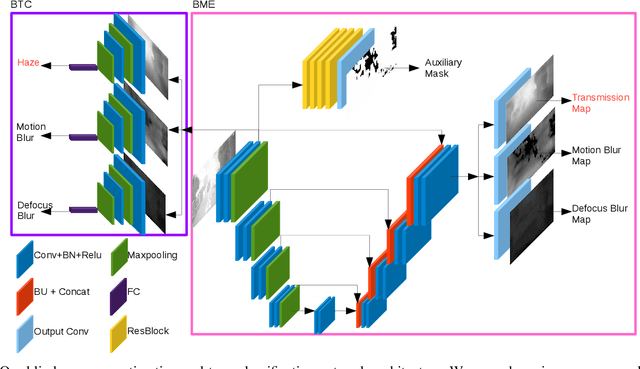

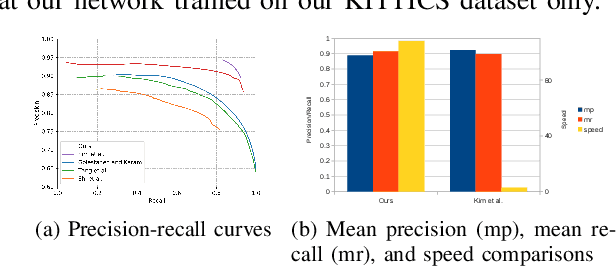
Outdoor vision robotic systems and autonomous cars suffer from many image-quality issues, particularly haze, defocus blur, and motion blur, which we will define generically as "blindness issues". These blindness issues may seriously affect the performance of robotic systems and could lead to unsafe decisions being made. However, existing solutions either focus on one type of blindness only or lack the ability to estimate the degree of blindness accurately. Besides, heavy computation is needed so that these solutions cannot run in real-time on practical systems. In this paper, we provide a method which could simultaneously detect the type of blindness and provide a blindness map indicating to what degree the vision is limited on a pixel-by-pixel basis. Both the blindness type and the estimate of per-pixel blindness are essential for tasks like deblur, dehaze, or the fail-safe functioning of robotic systems. We demonstrate the effectiveness of our approach on the KITTI and CUHK datasets where experiments show that our method outperforms other state-of-the-art approaches, achieving speeds of about 130 frames per second (fps).