 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLightCity: An Urban Dataset for Outdoor Inverse Rendering and Reconstruction under Multi-illumination Conditions
Feb 01, 2026Inverse rendering in urban scenes is pivotal for applications like autonomous driving and digital twins. Yet, it faces significant challenges due to complex illumination conditions, including multi-illumination and indirect light and shadow effects. However, the effects of these challenges on intrinsic decomposition and 3D reconstruction have not been explored due to the lack of appropriate datasets. In this paper, we present LightCity, a novel high-quality synthetic urban dataset featuring diverse illumination conditions with realistic indirect light and shadow effects. LightCity encompasses over 300 sky maps with highly controllable illumination, varying scales with street-level and aerial perspectives over 50K images, and rich properties such as depth, normal, material components, light and indirect light, etc. Besides, we leverage LightCity to benchmark three fundamental tasks in the urban environments and conduct a comprehensive analysis of these benchmarks, laying a robust foundation for advancing related research.
GaussianUpdate: Continual 3D Gaussian Splatting Update for Changing Environments
Aug 12, 2025Novel view synthesis with neural models has advanced rapidly in recent years, yet adapting these models to scene changes remains an open problem. Existing methods are either labor-intensive, requiring extensive model retraining, or fail to capture detailed types of changes over time. In this paper, we present GaussianUpdate, a novel approach that combines 3D Gaussian representation with continual learning to address these challenges. Our method effectively updates the Gaussian radiance fields with current data while preserving information from past scenes. Unlike existing methods, GaussianUpdate explicitly models different types of changes through a novel multi-stage update strategy. Additionally, we introduce a visibility-aware continual learning approach with generative replay, enabling self-aware updating without the need to store images. The experiments on the benchmark dataset demonstrate our method achieves superior and real-time rendering with the capability of visualizing changes over different times
ImmerseGen: Agent-Guided Immersive World Generation with Alpha-Textured Proxies
Jun 18, 2025Automatic creation of 3D scenes for immersive VR presence has been a significant research focus for decades. However, existing methods often rely on either high-poly mesh modeling with post-hoc simplification or massive 3D Gaussians, resulting in a complex pipeline or limited visual realism. In this paper, we demonstrate that such exhaustive modeling is unnecessary for achieving compelling immersive experience. We introduce ImmerseGen, a novel agent-guided framework for compact and photorealistic world modeling. ImmerseGen represents scenes as hierarchical compositions of lightweight geometric proxies, i.e., simplified terrain and billboard meshes, and generates photorealistic appearance by synthesizing RGBA textures onto these proxies. Specifically, we propose terrain-conditioned texturing for user-centric base world synthesis, and RGBA asset texturing for midground and foreground scenery. This reformulation offers several advantages: (i) it simplifies modeling by enabling agents to guide generative models in producing coherent textures that integrate seamlessly with the scene; (ii) it bypasses complex geometry creation and decimation by directly synthesizing photorealistic textures on proxies, preserving visual quality without degradation; (iii) it enables compact representations suitable for real-time rendering on mobile VR headsets. To automate scene creation from text prompts, we introduce VLM-based modeling agents enhanced with semantic grid-based analysis for improved spatial reasoning and accurate asset placement. ImmerseGen further enriches scenes with dynamic effects and ambient audio to support multisensory immersion. Experiments on scene generation and live VR showcases demonstrate that ImmerseGen achieves superior photorealism, spatial coherence and rendering efficiency compared to prior methods. Project webpage: https://immersegen.github.io.
IM-Portrait: Learning 3D-aware Video Diffusion for Photorealistic Talking Heads from Monocular Videos
Apr 29, 2025We propose a novel 3D-aware diffusion-based method for generating photorealistic talking head videos directly from a single identity image and explicit control signals (e.g., expressions). Our method generates Multiplane Images (MPIs) that ensure geometric consistency, making them ideal for immersive viewing experiences like binocular videos for VR headsets. Unlike existing methods that often require a separate stage or joint optimization to reconstruct a 3D representation (such as NeRF or 3D Gaussians), our approach directly generates the final output through a single denoising process, eliminating the need for post-processing steps to render novel views efficiently. To effectively learn from monocular videos, we introduce a training mechanism that reconstructs the output MPI randomly in either the target or the reference camera space. This approach enables the model to simultaneously learn sharp image details and underlying 3D information. Extensive experiments demonstrate the effectiveness of our method, which achieves competitive avatar quality and novel-view rendering capabilities, even without explicit 3D reconstruction or high-quality multi-view training data.
HiScene: Creating Hierarchical 3D Scenes with Isometric View Generation
Apr 17, 2025Scene-level 3D generation represents a critical frontier in multimedia and computer graphics, yet existing approaches either suffer from limited object categories or lack editing flexibility for interactive applications. In this paper, we present HiScene, a novel hierarchical framework that bridges the gap between 2D image generation and 3D object generation and delivers high-fidelity scenes with compositional identities and aesthetic scene content. Our key insight is treating scenes as hierarchical "objects" under isometric views, where a room functions as a complex object that can be further decomposed into manipulatable items. This hierarchical approach enables us to generate 3D content that aligns with 2D representations while maintaining compositional structure. To ensure completeness and spatial alignment of each decomposed instance, we develop a video-diffusion-based amodal completion technique that effectively handles occlusions and shadows between objects, and introduce shape prior injection to ensure spatial coherence within the scene. Experimental results demonstrate that our method produces more natural object arrangements and complete object instances suitable for interactive applications, while maintaining physical plausibility and alignment with user inputs.
Free360: Layered Gaussian Splatting for Unbounded 360-Degree View Synthesis from Extremely Sparse and Unposed Views
Mar 31, 2025

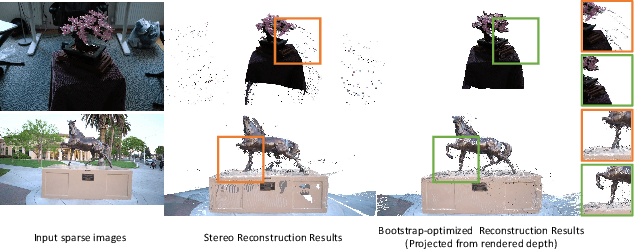

Neural rendering has demonstrated remarkable success in high-quality 3D neural reconstruction and novel view synthesis with dense input views and accurate poses. However, applying it to extremely sparse, unposed views in unbounded 360{\deg} scenes remains a challenging problem. In this paper, we propose a novel neural rendering framework to accomplish the unposed and extremely sparse-view 3D reconstruction in unbounded 360{\deg} scenes. To resolve the spatial ambiguity inherent in unbounded scenes with sparse input views, we propose a layered Gaussian-based representation to effectively model the scene with distinct spatial layers. By employing a dense stereo reconstruction model to recover coarse geometry, we introduce a layer-specific bootstrap optimization to refine the noise and fill occluded regions in the reconstruction. Furthermore, we propose an iterative fusion of reconstruction and generation alongside an uncertainty-aware training approach to facilitate mutual conditioning and enhancement between these two processes. Comprehensive experiments show that our approach outperforms existing state-of-the-art methods in terms of rendering quality and surface reconstruction accuracy. Project page: https://zju3dv.github.io/free360/
NeuraLoc: Visual Localization in Neural Implicit Map with Dual Complementary Features
Mar 08, 2025Recently, neural radiance fields (NeRF) have gained significant attention in the field of visual localization. However, existing NeRF-based approaches either lack geometric constraints or require extensive storage for feature matching, limiting their practical applications. To address these challenges, we propose an efficient and novel visual localization approach based on the neural implicit map with complementary features. Specifically, to enforce geometric constraints and reduce storage requirements, we implicitly learn a 3D keypoint descriptor field, avoiding the need to explicitly store point-wise features. To further address the semantic ambiguity of descriptors, we introduce additional semantic contextual feature fields, which enhance the quality and reliability of 2D-3D correspondences. Besides, we propose descriptor similarity distribution alignment to minimize the domain gap between 2D and 3D feature spaces during matching. Finally, we construct the matching graph using both complementary descriptors and contextual features to establish accurate 2D-3D correspondences for 6-DoF pose estimation. Compared with the recent NeRF-based approaches, our method achieves a 3$\times$ faster training speed and a 45$\times$ reduction in model storage. Extensive experiments on two widely used datasets demonstrate that our approach outperforms or is highly competitive with other state-of-the-art NeRF-based visual localization methods. Project page: \href{https://zju3dv.github.io/neuraloc}{https://zju3dv.github.io/neuraloc}
GURecon: Learning Detailed 3D Geometric Uncertainties for Neural Surface Reconstruction
Dec 19, 2024Neural surface representation has demonstrated remarkable success in the areas of novel view synthesis and 3D reconstruction. However, assessing the geometric quality of 3D reconstructions in the absence of ground truth mesh remains a significant challenge, due to its rendering-based optimization process and entangled learning of appearance and geometry with photometric losses. In this paper, we present a novel framework, i.e, GURecon, which establishes a geometric uncertainty field for the neural surface based on geometric consistency. Different from existing methods that rely on rendering-based measurement, GURecon models a continuous 3D uncertainty field for the reconstructed surface, and is learned by an online distillation approach without introducing real geometric information for supervision. Moreover, in order to mitigate the interference of illumination on geometric consistency, a decoupled field is learned and exploited to finetune the uncertainty field. Experiments on various datasets demonstrate the superiority of GURecon in modeling 3D geometric uncertainty, as well as its plug-and-play extension to various neural surface representations and improvement on downstream tasks such as incremental reconstruction. The code and supplementary material are available on the project website: https://zju3dv.github.io/GURecon/.
CFSynthesis: Controllable and Free-view 3D Human Video Synthesis
Dec 17, 2024



Human video synthesis aims to create lifelike characters in various environments, with wide applications in VR, storytelling, and content creation. While 2D diffusion-based methods have made significant progress, they struggle to generalize to complex 3D poses and varying scene backgrounds. To address these limitations, we introduce CFSynthesis, a novel framework for generating high-quality human videos with customizable attributes, including identity, motion, and scene configurations. Our method leverages a texture-SMPL-based representation to ensure consistent and stable character appearances across free viewpoints. Additionally, we introduce a novel foreground-background separation strategy that effectively decomposes the scene as foreground and background, enabling seamless integration of user-defined backgrounds. Experimental results on multiple datasets show that CFSynthesis not only achieves state-of-the-art performance in complex human animations but also adapts effectively to 3D motions in free-view and user-specified scenarios.
A Global Depth-Range-Free Multi-View Stereo Transformer Network with Pose Embedding
Nov 04, 2024



In this paper, we propose a novel multi-view stereo (MVS) framework that gets rid of the depth range prior. Unlike recent prior-free MVS methods that work in a pair-wise manner, our method simultaneously considers all the source images. Specifically, we introduce a Multi-view Disparity Attention (MDA) module to aggregate long-range context information within and across multi-view images. Considering the asymmetry of the epipolar disparity flow, the key to our method lies in accurately modeling multi-view geometric constraints. We integrate pose embedding to encapsulate information such as multi-view camera poses, providing implicit geometric constraints for multi-view disparity feature fusion dominated by attention. Additionally, we construct corresponding hidden states for each source image due to significant differences in the observation quality of the same pixel in the reference frame across multiple source frames. We explicitly estimate the quality of the current pixel corresponding to sampled points on the epipolar line of the source image and dynamically update hidden states through the uncertainty estimation module. Extensive results on the DTU dataset and Tanks&Temple benchmark demonstrate the effectiveness of our method. The code is available at our project page: https://zju3dv.github.io/GD-PoseMVS/.